 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXVerse: Consistent Multi-Subject Control of Identity and Semantic Attributes via DiT Modulation
Jun 26, 2025Achieving fine-grained control over subject identity and semantic attributes (pose, style, lighting) in text-to-image generation, particularly for multiple subjects, often undermines the editability and coherence of Diffusion Transformers (DiTs). Many approaches introduce artifacts or suffer from attribute entanglement. To overcome these challenges, we propose a novel multi-subject controlled generation model XVerse. By transforming reference images into offsets for token-specific text-stream modulation, XVerse allows for precise and independent control for specific subject without disrupting image latents or features. Consequently, XVerse offers high-fidelity, editable multi-subject image synthesis with robust control over individual subject characteristics and semantic attributes. This advancement significantly improves personalized and complex scene generation capabilities.
PhotoVerse: Tuning-Free Image Customization with Text-to-Image Diffusion Models
Sep 11, 2023



Personalized text-to-image generation has emerged as a powerful and sought-after tool, empowering users to create customized images based on their specific concepts and prompts. However, existing approaches to personalization encounter multiple challenges, including long tuning times, large storage requirements, the necessity for multiple input images per identity, and limitations in preserving identity and editability. To address these obstacles, we present PhotoVerse, an innovative methodology that incorporates a dual-branch conditioning mechanism in both text and image domains, providing effective control over the image generation process. Furthermore, we introduce facial identity loss as a novel component to enhance the preservation of identity during training. Remarkably, our proposed PhotoVerse eliminates the need for test time tuning and relies solely on a single facial photo of the target identity, significantly reducing the resource cost associated with image generation. After a single training phase, our approach enables generating high-quality images within only a few seconds. Moreover, our method can produce diverse images that encompass various scenes and styles. The extensive evaluation demonstrates the superior performance of our approach, which achieves the dual objectives of preserving identity and facilitating editability. Project page: https://photoverse2d.github.io/
Modiff: Action-Conditioned 3D Motion Generation with Denoising Diffusion Probabilistic Models
Jan 10, 2023



Diffusion-based generative models have recently emerged as powerful solutions for high-quality synthesis in multiple domains. Leveraging the bidirectional Markov chains, diffusion probabilistic models generate samples by inferring the reversed Markov chain based on the learned distribution mapping at the forward diffusion process. In this work, we propose Modiff, a conditional paradigm that benefits from the denoising diffusion probabilistic model (DDPM) to tackle the problem of realistic and diverse action-conditioned 3D skeleton-based motion generation. We are a pioneering attempt that uses DDPM to synthesize a variable number of motion sequences conditioned on a categorical action. We evaluate our approach on the large-scale NTU RGB+D dataset and show improvements over state-of-the-art motion generation methods.
Multi-Scale Local-Temporal Similarity Fusion for Continuous Sign Language Recognition
Jul 27, 2021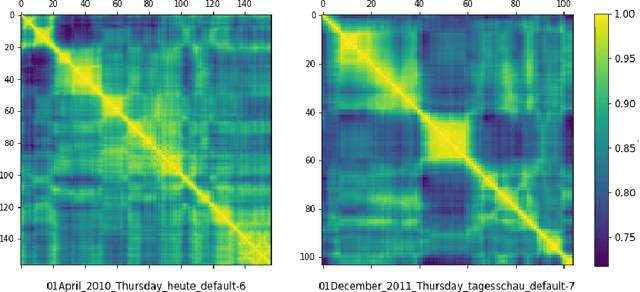


Continuous sign language recognition (cSLR) is a public significant task that transcribes a sign language video into an ordered gloss sequence. It is important to capture the fine-grained gloss-level details, since there is no explicit alignment between sign video frames and the corresponding glosses. Among the past works, one promising way is to adopt a one-dimensional convolutional network (1D-CNN) to temporally fuse the sequential frames. However, CNNs are agnostic to similarity or dissimilarity, and thus are unable to capture local consistent semantics within temporally neighboring frames. To address the issue, we propose to adaptively fuse local features via temporal similarity for this task. Specifically, we devise a Multi-scale Local-Temporal Similarity Fusion Network (mLTSF-Net) as follows: 1) In terms of a specific video frame, we firstly select its similar neighbours with multi-scale receptive regions to accommodate different lengths of glosses. 2) To ensure temporal consistency, we then use position-aware convolution to temporally convolve each scale of selected frames. 3) To obtain a local-temporally enhanced frame-wise representation, we finally fuse the results of different scales using a content-dependent aggregator. We train our model in an end-to-end fashion, and the experimental results on RWTH-PHOENIX-Weather 2014 datasets (RWTH) demonstrate that our model achieves competitive performance compared with several state-of-the-art models.
PiSLTRc: Position-informed Sign Language Transformer with Content-aware Convolution
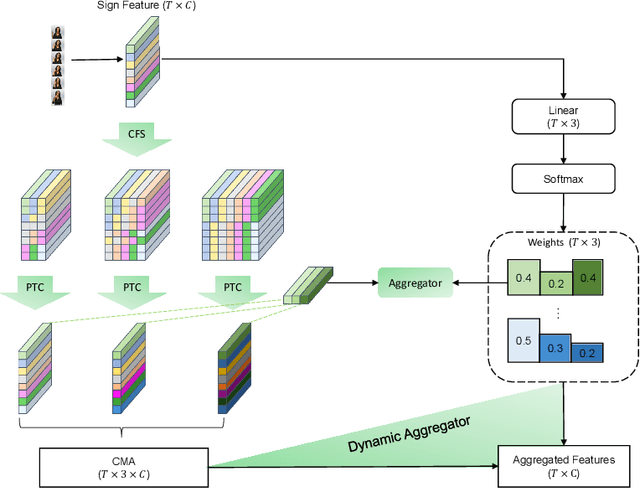
Jul 27, 2021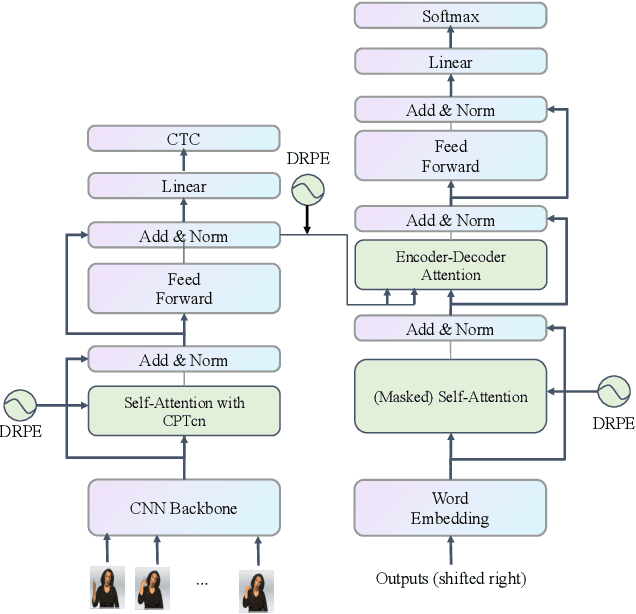
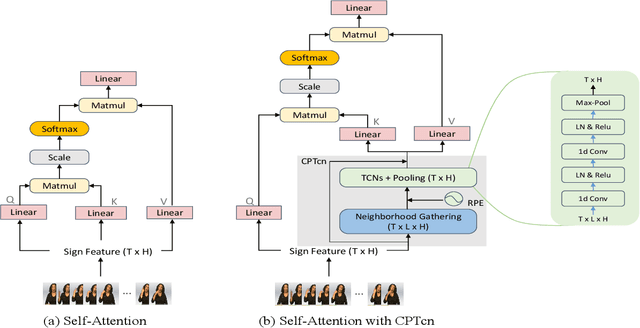


Since the superiority of Transformer in learning long-term dependency, the sign language Transformer model achieves remarkable progress in Sign Language Recognition (SLR) and Translation (SLT). However, there are several issues with the Transformer that prevent it from better sign language understanding. The first issue is that the self-attention mechanism learns sign video representation in a frame-wise manner, neglecting the temporal semantic structure of sign gestures. Secondly, the attention mechanism with absolute position encoding is direction and distance unaware, thus limiting its ability. To address these issues, we propose a new model architecture, namely PiSLTRc, with two distinctive characteristics: (i) content-aware and position-aware convolution layers. Specifically, we explicitly select relevant features using a novel content-aware neighborhood gathering method. Then we aggregate these features with position-informed temporal convolution layers, thus generating robust neighborhood-enhanced sign representation. (ii) injecting the relative position information to the attention mechanism in the encoder, decoder, and even encoder-decoder cross attention. Compared with the vanilla Transformer model, our model performs consistently better on three large-scale sign language benchmarks: PHOENIX-2014, PHOENIX-2014-T and CSL. Furthermore, extensive experiments demonstrate that the proposed method achieves state-of-the-art performance on translation quality with $+1.6$ BLEU improvements.