 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Neural Architecture Search
Progressive neural architecture search (PNAS) is a method for automatically designing neural network architectures.
Papers and Code
RobustMask: Certified Robustness against Adversarial Neural Ranking Attack via Randomized Masking
Dec 29, 2025Neural ranking models have achieved remarkable progress and are now widely deployed in real-world applications such as Retrieval-Augmented Generation (RAG). However, like other neural architectures, they remain vulnerable to adversarial manipulations: subtle character-, word-, or phrase-level perturbations can poison retrieval results and artificially promote targeted candidates, undermining the integrity of search engines and downstream systems. Existing defenses either rely on heuristics with poor generalization or on certified methods that assume overly strong adversarial knowledge, limiting their practical use. To address these challenges, we propose RobustMask, a novel defense that combines the context-prediction capability of pretrained language models with a randomized masking-based smoothing mechanism. Our approach strengthens neural ranking models against adversarial perturbations at the character, word, and phrase levels. Leveraging both the pairwise comparison ability of ranking models and probabilistic statistical analysis, we provide a theoretical proof of RobustMask's certified top-K robustness. Extensive experiments further demonstrate that RobustMask successfully certifies over 20% of candidate documents within the top-10 ranking positions against adversarial perturbations affecting up to 30% of their content. These results highlight the effectiveness of RobustMask in enhancing the adversarial robustness of neural ranking models, marking a significant step toward providing stronger security guarantees for real-world retrieval systems.
Sequencing to Mitigate Catastrophic Forgetting in Continual Learning
Dec 18, 2025To cope with real-world dynamics, an intelligent system needs to incrementally acquire, update, and exploit knowledge throughout its lifetime. This ability, known as Continual learning, provides a foundation for AI systems to develop themselves adaptively. Catastrophic forgetting is a major challenge to the progress of Continual Learning approaches, where learning a new task usually results in a dramatic performance drop on previously learned ones. Many approaches have emerged to counteract the impact of CF. Most of the proposed approaches can be categorized into five classes: replay-based, regularization-based, optimization-based, representation-based, and architecture-based. In this work, we approach the problem from a different angle, specifically by considering the optimal sequencing of tasks as they are presented to the model. We investigate the role of task sequencing in mitigating CF and propose a method for determining the optimal task order. The proposed method leverages zero-shot scoring algorithms inspired by neural architecture search (NAS). Results demonstrate that intelligent task sequencing can substantially reduce CF. Moreover, when combined with traditional continual learning strategies, sequencing offers enhanced performance and robustness against forgetting. Additionally, the presented approaches can find applications in other fields, such as curriculum learning.
Sparse by Rule: Probability-Based N:M Pruning for Spiking Neural Networks
Nov 15, 2025Brain-inspired Spiking neural networks (SNNs) promise energy-efficient intelligence via event-driven, sparse computation, but deeper architectures inflate parameters and computational cost, hindering their edge deployment. Recent progress in SNN pruning helps alleviate this burden, yet existing efforts fall into only two families: \emph{unstructured} pruning, which attains high sparsity but is difficult to accelerate on general hardware, and \emph{structured} pruning, which eases deployment but lack flexibility and often degrades accuracy at matched sparsity. In this work, we introduce \textbf{SpikeNM}, the first SNN-oriented \emph{semi-structured} \(N{:}M\) pruning framework that learns sparse SNNs \emph{from scratch}, enforcing \emph{at most \(N\)} non-zeros per \(M\)-weight block. To avoid the combinatorial space complexity \(\sum_{k=1}^{N}\binom{M}{k}\) growing exponentially with \(M\), SpikeNM adopts an \(M\)-way basis-logit parameterization with a differentiable top-\(k\) sampler, \emph{linearizing} per-block complexity to \(\mathcal O(M)\) and enabling more aggressive sparsification. Further inspired by neuroscience, we propose \emph{eligibility-inspired distillation} (EID), which converts temporally accumulated credits into block-wise soft targets to align mask probabilities with spiking dynamics, reducing sampling variance and stabilizing search under high sparsity. Experiments show that at \(2{:}4\) sparsity, SpikeNM maintains and even with gains across main-stream datasets, while yielding hardware-amenable patterns that complement intrinsic spike sparsity.
Semantic Search for Information Retrieval
Aug 25, 2025Information retrieval systems have progressed notably from lexical techniques such as BM25 and TF-IDF to modern semantic retrievers. This survey provides a brief overview of the BM25 baseline, then discusses the architecture of modern state-of-the-art semantic retrievers. Advancing from BERT, we introduce dense bi-encoders (DPR), late-interaction models (ColBERT), and neural sparse retrieval (SPLADE). Finally, we examine MonoT5, a cross-encoder model. We conclude with common evaluation tactics, pressing challenges, and propositions for future directions.
Database Views as Explanations for Relational Deep Learning
Sep 11, 2025In recent years, there has been significant progress in the development of deep learning models over relational databases, including architectures based on heterogeneous graph neural networks (hetero-GNNs) and heterogeneous graph transformers. In effect, such architectures state how the database records and links (e.g., foreign-key references) translate into a large, complex numerical expression, involving numerous learnable parameters. This complexity makes it hard to explain, in human-understandable terms, how a model uses the available data to arrive at a given prediction. We present a novel framework for explaining machine-learning models over relational databases, where explanations are view definitions that highlight focused parts of the database that mostly contribute to the model's prediction. We establish such global abductive explanations by adapting the classic notion of determinacy by Nash, Segoufin, and Vianu (2010). In addition to tuning the tradeoff between determinacy and conciseness, the framework allows controlling the level of granularity by adopting different fragments of view definitions, such as ones highlighting whole columns, foreign keys between tables, relevant groups of tuples, and so on. We investigate the realization of the framework in the case of hetero-GNNs. We develop heuristic algorithms that avoid the exhaustive search over the space of all databases. We propose techniques that are model-agnostic, and others that are tailored to hetero-GNNs via the notion of learnable masking. Our approach is evaluated through an extensive empirical study on the RelBench collection, covering a variety of domains and different record-level tasks. The results demonstrate the usefulness of the proposed explanations, as well as the efficiency of their generation.
AlphaGo Moment for Model Architecture Discovery
Jul 24, 2025
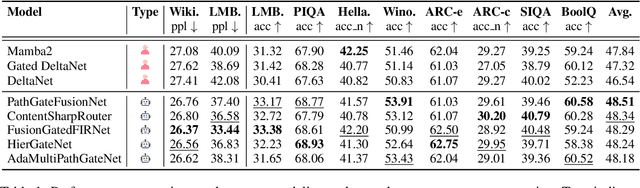
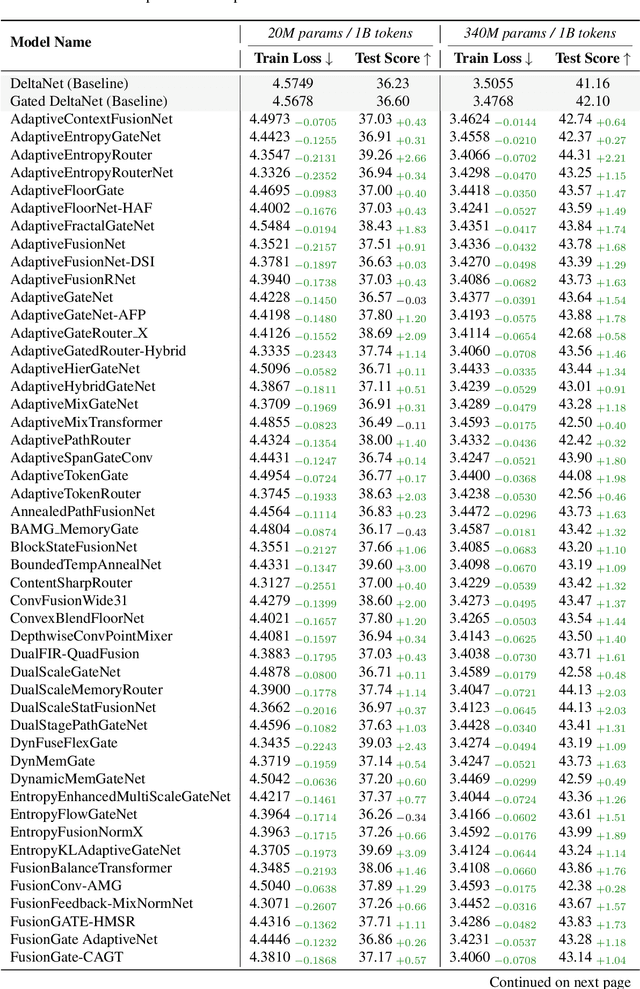

While AI systems demonstrate exponentially improving capabilities, the pace of AI research itself remains linearly bounded by human cognitive capacity, creating an increasingly severe development bottleneck. We present ASI-Arch, the first demonstration of Artificial Superintelligence for AI research (ASI4AI) in the critical domain of neural architecture discovery--a fully autonomous system that shatters this fundamental constraint by enabling AI to conduct its own architectural innovation. Moving beyond traditional Neural Architecture Search (NAS), which is fundamentally limited to exploring human-defined spaces, we introduce a paradigm shift from automated optimization to automated innovation. ASI-Arch can conduct end-to-end scientific research in the domain of architecture discovery, autonomously hypothesizing novel architectural concepts, implementing them as executable code, training and empirically validating their performance through rigorous experimentation and past experience. ASI-Arch conducted 1,773 autonomous experiments over 20,000 GPU hours, culminating in the discovery of 106 innovative, state-of-the-art (SOTA) linear attention architectures. Like AlphaGo's Move 37 that revealed unexpected strategic insights invisible to human players, our AI-discovered architectures demonstrate emergent design principles that systematically surpass human-designed baselines and illuminate previously unknown pathways for architectural innovation. Crucially, we establish the first empirical scaling law for scientific discovery itself--demonstrating that architectural breakthroughs can be scaled computationally, transforming research progress from a human-limited to a computation-scalable process. We provide comprehensive analysis of the emergent design patterns and autonomous research capabilities that enabled these breakthroughs, establishing a blueprint for self-accelerating AI systems.
Guidelines for the Quality Assessment of Energy-Aware NAS Benchmarks
May 21, 2025Neural Architecture Search (NAS) accelerates progress in deep learning through systematic refinement of model architectures. The downside is increasingly large energy consumption during the search process. Surrogate-based benchmarking mitigates the cost of full training by querying a pre-trained surrogate to obtain an estimate for the quality of the model. Specifically, energy-aware benchmarking aims to make it possible for NAS to favourably trade off model energy consumption against accuracy. Towards this end, we propose three design principles for such energy-aware benchmarks: (i) reliable power measurements, (ii) a wide range of GPU usage, and (iii) holistic cost reporting. We analyse EA-HAS-Bench based on these principles and find that the choice of GPU measurement API has a large impact on the quality of results. Using the Nvidia System Management Interface (SMI) on top of its underlying library influences the sampling rate during the initial data collection, returning faulty low-power estimations. This results in poor correlation with accurate measurements obtained from an external power meter. With this study, we bring to attention several key considerations when performing energy-aware surrogate-based benchmarking and derive first guidelines that can help design novel benchmarks. We show a narrow usage range of the four GPUs attached to our device, ranging from 146 W to 305 W in a single-GPU setting, and narrowing down even further when using all four GPUs. To improve holistic energy reporting, we propose calibration experiments over assumptions made in popular tools, such as Code Carbon, thus achieving reductions in the maximum inaccuracy from 10.3 % to 8.9 % without and to 6.6 % with prior estimation of the expected load on the device.
Refining music sample identification with a self-supervised graph neural network
Jun 17, 2025Automatic sample identification (ASID), the detection and identification of portions of audio recordings that have been reused in new musical works, is an essential but challenging task in the field of audio query-based retrieval. While a related task, audio fingerprinting, has made significant progress in accurately retrieving musical content under "real world" (noisy, reverberant) conditions, ASID systems struggle to identify samples that have undergone musical modifications. Thus, a system robust to common music production transformations such as time-stretching, pitch-shifting, effects processing, and underlying or overlaying music is an important open challenge. In this work, we propose a lightweight and scalable encoding architecture employing a Graph Neural Network within a contrastive learning framework. Our model uses only 9% of the trainable parameters compared to the current state-of-the-art system while achieving comparable performance, reaching a mean average precision (mAP) of 44.2%. To enhance retrieval quality, we introduce a two-stage approach consisting of an initial coarse similarity search for candidate selection, followed by a cross-attention classifier that rejects irrelevant matches and refines the ranking of retrieved candidates - an essential capability absent in prior models. In addition, because queries in real-world applications are often short in duration, we benchmark our system for short queries using new fine-grained annotations for the Sample100 dataset, which we publish as part of this work.
DimGrow: Memory-Efficient Field-level Embedding Dimension Search
May 19, 2025Key feature fields need bigger embedding dimensionality, others need smaller. This demands automated dimension allocation. Existing approaches, such as pruning or Neural Architecture Search (NAS), require training a memory-intensive SuperNet that enumerates all possible dimension combinations, which is infeasible for large feature spaces. We propose DimGrow, a lightweight approach that eliminates the SuperNet requirement. Starting training model from one dimension per feature field, DimGrow can progressively expand/shrink dimensions via importance scoring. Dimensions grow only when their importance consistently exceed a threshold, ensuring memory efficiency. Experiments on three recommendation datasets verify the effectiveness of DimGrow while it reduces training memory compared to SuperNet-based methods.
DNAD: Differentiable Neural Architecture Distillation
Apr 25, 2025To meet the demand for designing efficient neural networks with appropriate trade-offs between model performance (e.g., classification accuracy) and computational complexity, the differentiable neural architecture distillation (DNAD) algorithm is developed based on two cores, namely search by deleting and search by imitating. Primarily, to derive neural architectures in a space where cells of the same type no longer share the same topology, the super-network progressive shrinking (SNPS) algorithm is developed based on the framework of differentiable architecture search (DARTS), i.e., search by deleting. Unlike conventional DARTS-based approaches which yield neural architectures with simple structures and derive only one architecture during the search procedure, SNPS is able to derive a Pareto-optimal set of architectures with flexible structures by forcing the dynamic super-network shrink from a dense structure to a sparse one progressively. Furthermore, since knowledge distillation (KD) has shown great effectiveness to train a compact network with the assistance of an over-parameterized model, we integrate SNPS with KD to formulate the DNAD algorithm, i.e., search by imitating. By minimizing behavioral differences between the super-network and teacher network, the over-fitting of one-level DARTS is avoided and well-performed neural architectures are derived. Experiments on CIFAR-10 and ImageNet classification tasks demonstrate that both SNPS and DNAD are able to derive a set of architectures which achieve similar or lower error rates with fewer parameters and FLOPs. Particularly, DNAD achieves the top-1 error rate of 23.7% on ImageNet classification with a model of 6.0M parameters and 598M FLOPs, which outperforms most DARTS-based methods.