 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoto To Caricature Translation
Papers and Code
Unsupervised Contrastive Photo-to-Caricature Translation based on Auto-distortion
Nov 10, 2020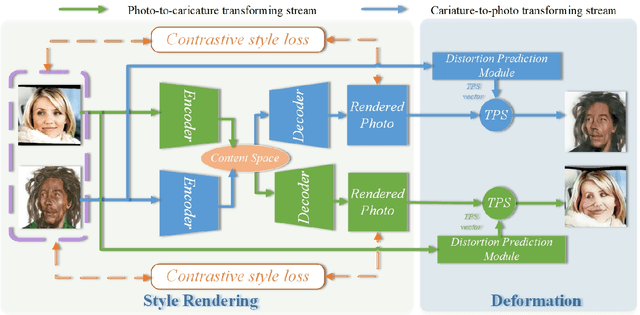
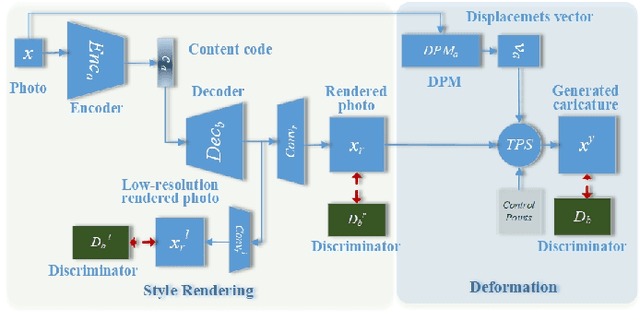

Photo-to-caricature translation aims to synthesize the caricature as a rendered image exaggerating the features through sketching, pencil strokes, or other artistic drawings. Style rendering and geometry deformation are the most important aspects in photo-to-caricature translation task. To take both into consideration, we propose an unsupervised contrastive photo-to-caricature translation architecture. Considering the intuitive artifacts in the existing methods, we propose a contrastive style loss for style rendering to enforce the similarity between the style of rendered photo and the caricature, and simultaneously enhance its discrepancy to the photos. To obtain an exaggerating deformation in an unpaired/unsupervised fashion, we propose a Distortion Prediction Module (DPM) to predict a set of displacements vectors for each input image while fixing some controlling points, followed by the thin plate spline interpolation for warping. The model is trained on unpaired photo and caricature while can offer bidirectional synthesizing via inputting either a photo or a caricature. Extensive experiments demonstrate that the proposed model is effective to generate hand-drawn like caricatures compared with existing competitors.
cGANs for Cartoon to Real-life Images
Jan 24, 2021

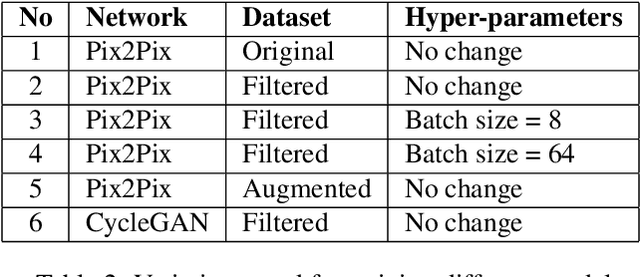

The image-to-image translation is a learning task to establish a visual mapping between an input and output image. The task has several variations differentiated based on the purpose of the translation, such as synthetic to real translation, photo to caricature translation, and many others. The problem has been tackled using different approaches, either through traditional computer vision methods, as well as deep learning approaches in recent trends. One approach currently deemed popular and effective is using the conditional generative adversarial network, also known shortly as cGAN. It is adapted to perform image-to-image translation tasks with typically two networks: a generator and a discriminator. This project aims to evaluate the robustness of the Pix2Pix model by applying the Pix2Pix model to datasets consisting of cartoonized images. Using the Pix2Pix model, it should be possible to train the network to generate real-life images from the cartoonized images.
CariMe: Unpaired Caricature Generation with Multiple Exaggerations
Oct 01, 2020



Caricature generation aims to translate real photos into caricatures with artistic styles and shape exaggerations while maintaining the identity of the subject. Different from the generic image-to-image translation, drawing a caricature automatically is a more challenging task due to the existence of various spacial deformations. Previous caricature generation methods are obsessed with predicting definite image warping from a given photo while ignoring the intrinsic representation and distribution for exaggerations in caricatures. This limits their ability on diverse exaggeration generation. In this paper, we generalize the caricature generation problem from instance-level warping prediction to distribution-level deformation modeling. Based on this assumption, we present the first exploration for unpaired CARIcature generation with Multiple Exaggerations (CariMe). Technically, we propose a Multi-exaggeration Warper network to learn the distribution-level mapping from photo to facial exaggerations. This makes it possible to generate diverse and reasonable exaggerations from randomly sampled warp codes given one input photo. To better represent the facial exaggeration and produce fine-grained warping, a deformation-field-based warping method is also proposed, which helps us to capture more detailed exaggerations than other point-based warping methods. Experiments and two perceptual studies prove the superiority of our method comparing with other state-of-the-art methods, showing the improvement of our work on caricature generation.
Unsupervised Domain Attention Adaptation Network for Caricature Attribute Recognition
Jul 18, 2020
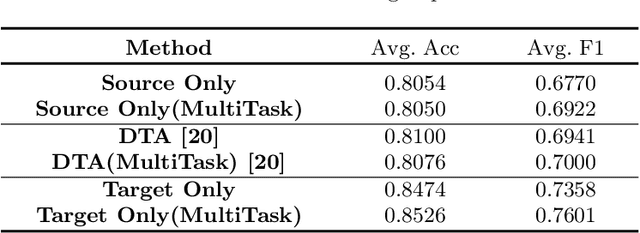
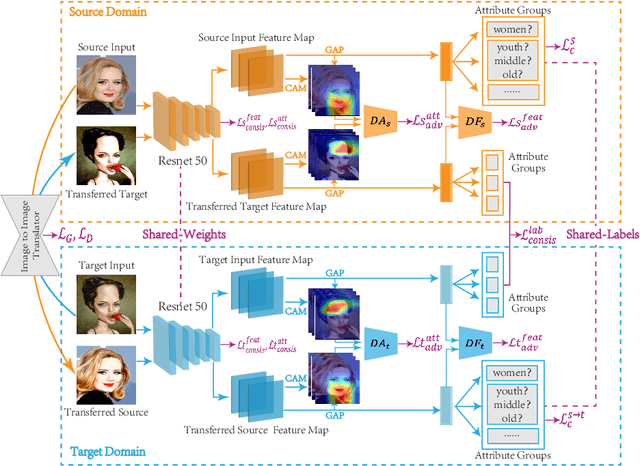
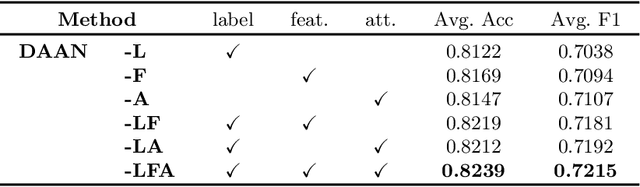
Caricature attributes provide distinctive facial features to help research in Psychology and Neuroscience. However, unlike the facial photo attribute datasets that have a quantity of annotated images, the annotations of caricature attributes are rare. To facility the research in attribute learning of caricatures, we propose a caricature attribute dataset, namely WebCariA. Moreover, to utilize models that trained by face attributes, we propose a novel unsupervised domain adaptation framework for cross-modality (i.e., photos to caricatures) attribute recognition, with an integrated inter- and intra-domain consistency learning scheme. Specifically, the inter-domain consistency learning scheme consisting an image-to-image translator to first fill the domain gap between photos and caricatures by generating intermediate image samples, and a label consistency learning module to align their semantic information. The intra-domain consistency learning scheme integrates the common feature consistency learning module with a novel attribute-aware attention-consistency learning module for a more efficient alignment. We did an extensive ablation study to show the effectiveness of the proposed method. And the proposed method also outperforms the state-of-the-art methods by a margin. The implementation of the proposed method is available at https://github.com/KeleiHe/DAAN.
3D Magic Mirror: Automatic Video to 3D Caricature Translation
Jun 03, 2019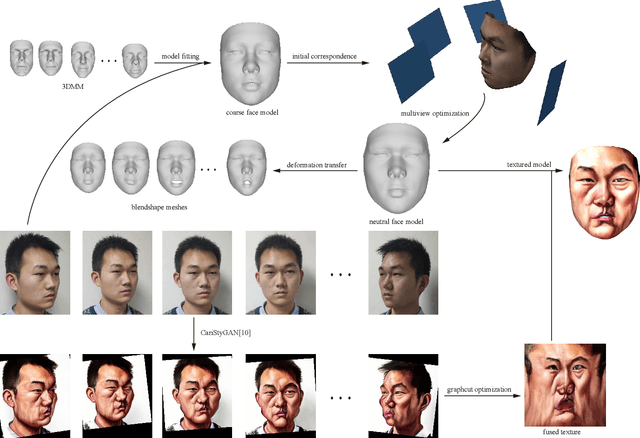
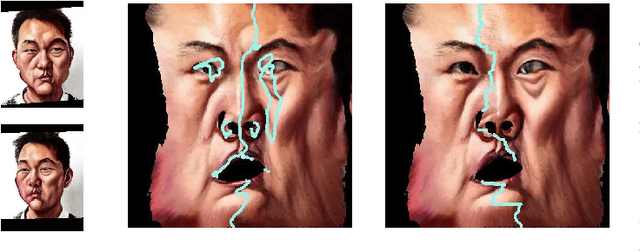
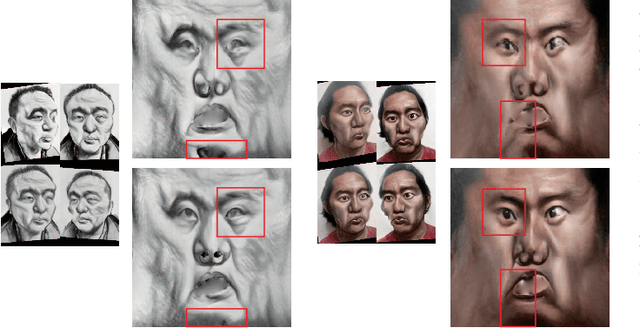
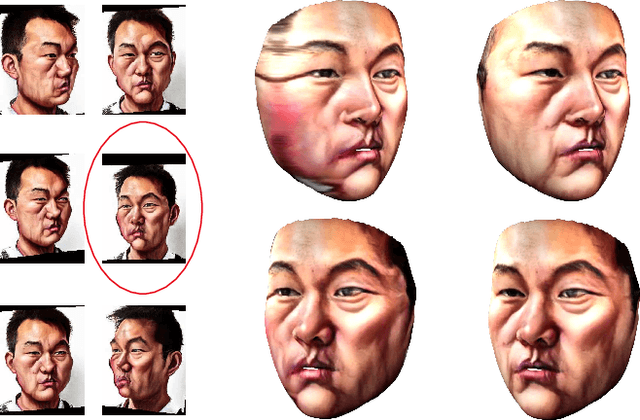
Caricature is an abstraction of a real person which distorts or exaggerates certain features, but still retains a likeness. While most existing works focus on 3D caricature reconstruction from 2D caricatures or translating 2D photos to 2D caricatures, this paper presents a real-time and automatic algorithm for creating expressive 3D caricatures with caricature style texture map from 2D photos or videos. To solve this challenging ill-posed reconstruction problem and cross-domain translation problem, we first reconstruct the 3D face shape for each frame, and then translate 3D face shape from normal style to caricature style by a novel identity and expression preserving VAE-CycleGAN. Based on a labeling formulation, the caricature texture map is constructed from a set of multi-view caricature images generated by CariGANs. The effectiveness and efficiency of our method are demonstrated by comparison with baseline implementations. The perceptual study shows that the 3D caricatures generated by our method meet people's expectations of 3D caricature style.
CariGANs: Unpaired Photo-to-Caricature Translation
Nov 02, 2018
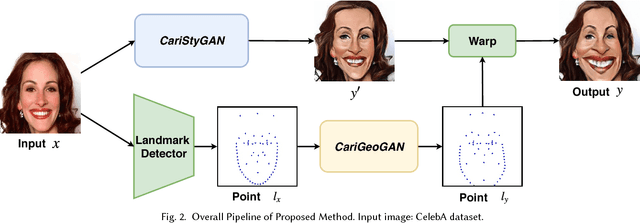
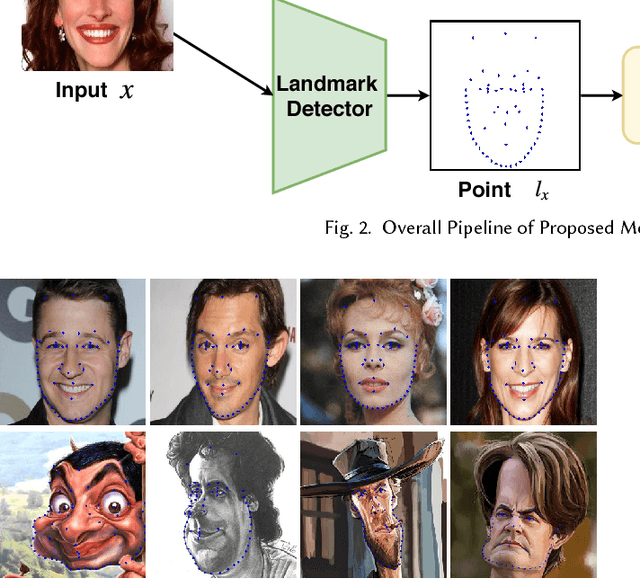
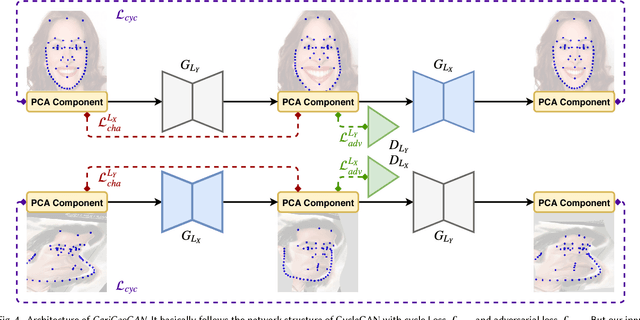
Facial caricature is an art form of drawing faces in an exaggerated way to convey humor or sarcasm. In this paper, we propose the first Generative Adversarial Network (GAN) for unpaired photo-to-caricature translation, which we call "CariGANs". It explicitly models geometric exaggeration and appearance stylization using two components: CariGeoGAN, which only models the geometry-to-geometry transformation from face photos to caricatures, and CariStyGAN, which transfers the style appearance from caricatures to face photos without any geometry deformation. In this way, a difficult cross-domain translation problem is decoupled into two easier tasks. The perceptual study shows that caricatures generated by our CariGANs are closer to the hand-drawn ones, and at the same time better persevere the identity, compared to state-of-the-art methods. Moreover, our CariGANs allow users to control the shape exaggeration degree and change the color/texture style by tuning the parameters or giving an example caricature.
* To appear at SIGGRAPH Asia 2018
Unpaired Photo-to-Caricature Translation on Faces in the Wild
Jul 25, 2018
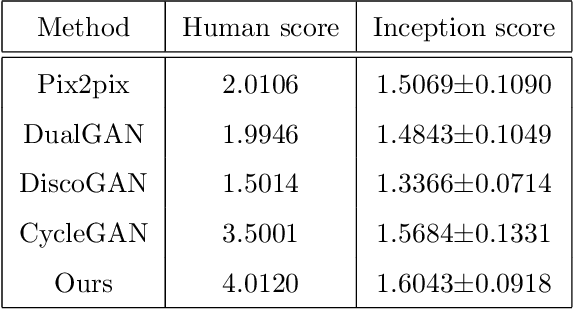
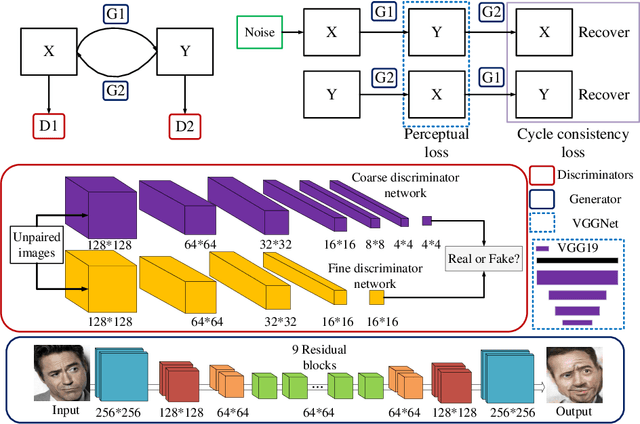
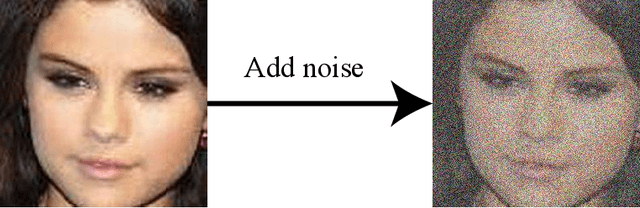
Recently, image-to-image translation has been made much progress owing to the success of conditional Generative Adversarial Networks (cGANs). And some unpaired methods based on cycle consistency loss such as DualGAN, CycleGAN and DiscoGAN are really popular. However, it's still very challenging for translation tasks with the requirement of high-level visual information conversion, such as photo-to-caricature translation that requires satire, exaggeration, lifelikeness and artistry. We present an approach for learning to translate faces in the wild from the source photo domain to the target caricature domain with different styles, which can also be used for other high-level image-to-image translation tasks. In order to capture global structure with local statistics while translation, we design a dual pathway model with one coarse discriminator and one fine discriminator. For generator, we provide one extra perceptual loss in association with adversarial loss and cycle consistency loss to achieve representation learning for two different domains. Also the style can be learned by the auxiliary noise input. Experiments on photo-to-caricature translation of faces in the wild show considerable performance gain of our proposed method over state-of-the-art translation methods as well as its potential real applications.