 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOracle MNIST
Papers and Code
Machine Unlearning in the Era of Quantum Machine Learning: An Empirical Study
Dec 23, 2025



We present the first comprehensive empirical study of machine unlearning (MU) in hybrid quantum-classical neural networks. While MU has been extensively explored in classical deep learning, its behavior within variational quantum circuits (VQCs) and quantum-augmented architectures remains largely unexplored. First, we adapt a broad suite of unlearning methods to quantum settings, including gradient-based, distillation-based, regularization-based and certified techniques. Second, we introduce two new unlearning strategies tailored to hybrid models. Experiments across Iris, MNIST, and Fashion-MNIST, under both subset removal and full-class deletion, reveal that quantum models can support effective unlearning, but outcomes depend strongly on circuit depth, entanglement structure, and task complexity. Shallow VQCs display high intrinsic stability with minimal memorization, whereas deeper hybrid models exhibit stronger trade-offs between utility, forgetting strength, and alignment with retrain oracle. We find that certain methods, e.g. EU-k, LCA, and Certified Unlearning, consistently provide the best balance across metrics. These findings establish baseline empirical insights into quantum machine unlearning and highlight the need for quantum-aware algorithms and theoretical guarantees, as quantum machine learning systems continue to expand in scale and capability. We publicly release our code at: https://github.com/CrivoiCarla/HQML.
RBR4DNN: Requirements-based Testing of Neural Networks
Apr 03, 2025



Deep neural network (DNN) testing is crucial for the reliability and safety of critical systems, where failures can have severe consequences. Although various techniques have been developed to create robustness test suites, requirements-based testing for DNNs remains largely unexplored -- yet such tests are recognized as an essential component of software validation of critical systems. In this work, we propose a requirements-based test suite generation method that uses structured natural language requirements formulated in a semantic feature space to create test suites by prompting text-conditional latent diffusion models with the requirement precondition and then using the associated postcondition to define a test oracle to judge outputs of the DNN under test. We investigate the approach using fine-tuned variants of pre-trained generative models. Our experiments on the MNIST, CelebA-HQ, ImageNet, and autonomous car driving datasets demonstrate that the generated test suites are realistic, diverse, consistent with preconditions, and capable of revealing faults.
Is Oracle Pruning the True Oracle?
Nov 28, 2024Oracle pruning, which selects unimportant weights by minimizing the pruned train loss, has been taken as the foundation for most neural network pruning methods for over 35 years, while few (if not none) have thought about how much the foundation really holds. This paper, for the first time, attempts to examine its validity on modern deep models through empirical correlation analyses and provide reflections on the field of neural network pruning. Specifically, for a typical pruning algorithm with three stages (pertaining, pruning, and retraining), we analyze the model performance correlation before and after retraining. Extensive experiments (37K models are trained) across a wide spectrum of models (LeNet5, VGG, ResNets, ViT, MLLM) and datasets (MNIST and its variants, CIFAR10/CIFAR100, ImageNet-1K, MLLM data) are conducted. The results lead to a surprising conclusion: on modern deep learning models, the performance before retraining is barely correlated with the performance after retraining. Namely, the weights selected by oracle pruning can hardly guarantee a good performance after retraining. This further implies that existing works using oracle pruning to derive pruning criteria may be groundless from the beginning. Further studies suggest the rising task complexity is one factor that makes oracle pruning invalid nowadays. Finally, given the evidence, we argue that the retraining stage in a pruning algorithm should be accounted for when developing any pruning criterion.
Double Oracle Neural Architecture Search for Game Theoretic Deep Learning Models
Oct 07, 2024



In this paper, we propose a new approach to train deep learning models using game theory concepts including Generative Adversarial Networks (GANs) and Adversarial Training (AT) where we deploy a double-oracle framework using best response oracles. GAN is essentially a two-player zero-sum game between the generator and the discriminator. The same concept can be applied to AT with attacker and classifier as players. Training these models is challenging as a pure Nash equilibrium may not exist and even finding the mixed Nash equilibrium is difficult as training algorithms for both GAN and AT have a large-scale strategy space. Extending our preliminary model DO-GAN, we propose the methods to apply the double oracle framework concept to Adversarial Neural Architecture Search (NAS for GAN) and Adversarial Training (NAS for AT) algorithms. We first generalize the players' strategies as the trained models of generator and discriminator from the best response oracles. We then compute the meta-strategies using a linear program. For scalability of the framework where multiple network models of best responses are stored in the memory, we prune the weakly-dominated players' strategies to keep the oracles from becoming intractable. Finally, we conduct experiments on MNIST, CIFAR-10 and TinyImageNet for DONAS-GAN. We also evaluate the robustness under FGSM and PGD attacks on CIFAR-10, SVHN and TinyImageNet for DONAS-AT. We show that all our variants have significant improvements in both subjective qualitative evaluation and quantitative metrics, compared with their respective base architectures.
Variance-Aware Linear UCB with Deep Representation for Neural Contextual Bandits
Nov 08, 2024By leveraging the representation power of deep neural networks, neural upper confidence bound (UCB) algorithms have shown success in contextual bandits. To further balance the exploration and exploitation, we propose Neural-$\sigma^2$-LinearUCB, a variance-aware algorithm that utilizes $\sigma^2_t$, i.e., an upper bound of the reward noise variance at round $t$, to enhance the uncertainty quantification quality of the UCB, resulting in a regret performance improvement. We provide an oracle version for our algorithm characterized by an oracle variance upper bound $\sigma^2_t$ and a practical version with a novel estimation for this variance bound. Theoretically, we provide rigorous regret analysis for both versions and prove that our oracle algorithm achieves a better regret guarantee than other neural-UCB algorithms in the neural contextual bandits setting. Empirically, our practical method enjoys a similar computational efficiency, while outperforming state-of-the-art techniques by having a better calibration and lower regret across multiple standard settings, including on the synthetic, UCI, MNIST, and CIFAR-10 datasets.
Oracle Bone Inscriptions Multi-modal Dataset
Jul 04, 2024

Oracle bone inscriptions(OBI) is the earliest developed writing system in China, bearing invaluable written exemplifications of early Shang history and paleography. However, the task of deciphering OBI, in the current climate of the scholarship, can prove extremely challenging. Out of the 4,500 oracle bone characters excavated, only a third have been successfully identified. Therefore, leveraging the advantages of advanced AI technology to assist in the decipherment of OBI is a highly essential research topic. However, fully utilizing AI's capabilities in these matters is reliant on having a comprehensive and high-quality annotated OBI dataset at hand whereas most existing datasets are only annotated in just a single or a few dimensions, limiting the value of their potential application. For instance, the Oracle-MNIST dataset only offers 30k images classified into 10 categories. Therefore, this paper proposes an Oracle Bone Inscriptions Multi-modal Dataset(OBIMD), which includes annotation information for 10,077 pieces of oracle bones. Each piece has two modalities: pixel-level aligned rubbings and facsimiles. The dataset annotates the detection boxes, character categories, transcriptions, corresponding inscription groups, and reading sequences in the groups of each oracle bone character, providing a comprehensive and high-quality level of annotations. This dataset can be used for a variety of AI-related research tasks relevant to the field of OBI, such as OBI Character Detection and Recognition, Rubbing Denoising, Character Matching, Character Generation, Reading Sequence Prediction, Missing Characters Completion task and so on. We believe that the creation and publication of a dataset like this will help significantly advance the application of AI algorithms in the field of OBI research.
FAIRM: Learning invariant representations for algorithmic fairness and domain generalization with minimax optimality
Apr 02, 2024



Machine learning methods often assume that the test data have the same distribution as the training data. However, this assumption may not hold due to multiple levels of heterogeneity in applications, raising issues in algorithmic fairness and domain generalization. In this work, we address the problem of fair and generalizable machine learning by invariant principles. We propose a training environment-based oracle, FAIRM, which has desirable fairness and domain generalization properties under a diversity-type condition. We then provide an empirical FAIRM with finite-sample theoretical guarantees under weak distributional assumptions. We then develop efficient algorithms to realize FAIRM in linear models and demonstrate the nonasymptotic performance with minimax optimality. We evaluate our method in numerical experiments with synthetic data and MNIST data and show that it outperforms its counterparts.
GQHAN: A Grover-inspired Quantum Hard Attention Network
Jan 25, 2024Numerous current Quantum Machine Learning (QML) models exhibit an inadequacy in discerning the significance of quantum data, resulting in diminished efficacy when handling extensive quantum datasets. Hard Attention Mechanism (HAM), anticipated to efficiently tackle the above QML bottlenecks, encounters the substantial challenge of non-differentiability, consequently constraining its extensive applicability. In response to the dilemma of HAM and QML, a Grover-inspired Quantum Hard Attention Mechanism (GQHAM) consisting of a Flexible Oracle (FO) and an Adaptive Diffusion Operator (ADO) is proposed. Notably, the FO is designed to surmount the non-differentiable issue by executing the activation or masking of Discrete Primitives (DPs) with Flexible Control (FC) to weave various discrete destinies. Based on this, such discrete choice can be visualized with a specially defined Quantum Hard Attention Score (QHAS). Furthermore, a trainable ADO is devised to boost the generality and flexibility of GQHAM. At last, a Grover-inspired Quantum Hard Attention Network (GQHAN) based on QGHAM is constructed on PennyLane platform for Fashion MNIST binary classification. Experimental findings demonstrate that GQHAN adeptly surmounts the non-differentiability hurdle, surpassing the efficacy of extant quantum soft self-attention mechanisms in accuracies and learning ability. In noise experiments, GQHAN is robuster to bit-flip noise in accuracy and amplitude damping noise in learning performance. Predictably, the proposal of GQHAN enriches the Quantum Attention Mechanism (QAM), lays the foundation for future quantum computers to process large-scale data, and promotes the development of quantum computer vision.
Learning Diverse Features in Vision Transformers for Improved Generalization
Aug 30, 2023Deep learning models often rely only on a small set of features even when there is a rich set of predictive signals in the training data. This makes models brittle and sensitive to distribution shifts. In this work, we first examine vision transformers (ViTs) and find that they tend to extract robust and spurious features with distinct attention heads. As a result of this modularity, their performance under distribution shifts can be significantly improved at test time by pruning heads corresponding to spurious features, which we demonstrate using an "oracle selection" on validation data. Second, we propose a method to further enhance the diversity and complementarity of the learned features by encouraging orthogonality of the attention heads' input gradients. We observe improved out-of-distribution performance on diagnostic benchmarks (MNIST-CIFAR, Waterbirds) as a consequence of the enhanced diversity of features and the pruning of undesirable heads.
Oracle-MNIST: a Realistic Image Dataset for Benchmarking Machine Learning Algorithms
May 19, 2022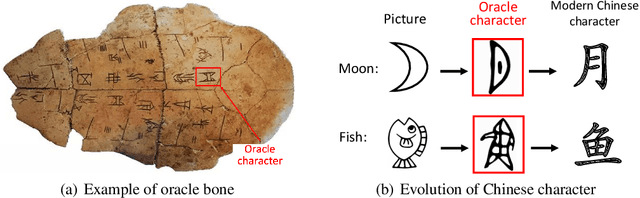
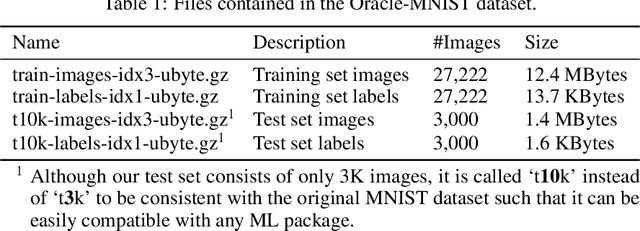


We introduce the Oracle-MNIST dataset, comprising of 28$\times $28 grayscale images of 30,222 ancient characters from 10 categories, for benchmarking pattern classification, with particular challenges on image noise and distortion. The training set totally consists of 27,222 images, and the test set contains 300 images per class. Oracle-MNIST shares the same data format with the original MNIST dataset, allowing for direct compatibility with all existing classifiers and systems, but it constitutes a more challenging classification task than MNIST. The images of ancient characters suffer from 1) extremely serious and unique noises caused by three-thousand years of burial and aging and 2) dramatically variant writing styles by ancient Chinese, which all make them realistic for machine learning research. The dataset is freely available at https://github.com/wm-bupt/oracle-mnist.