 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spatial-Physics Informed Model for 3D Spiral Sample Scanned by SQUID Microscopy
Jul 16, 2025


The development of advanced packaging is essential in the semiconductor manufacturing industry. However, non-destructive testing (NDT) of advanced packaging becomes increasingly challenging due to the depth and complexity of the layers involved. In such a scenario, Magnetic field imaging (MFI) enables the imaging of magnetic fields generated by currents. For MFI to be effective in NDT, the magnetic fields must be converted into current density. This conversion has typically relied solely on a Fast Fourier Transform (FFT) for magnetic field inversion; however, the existing approach does not consider eddy current effects or image misalignment in the test setup. In this paper, we present a spatial-physics informed model (SPIM) designed for a 3D spiral sample scanned using Superconducting QUantum Interference Device (SQUID) microscopy. The SPIM encompasses three key components: i) magnetic image enhancement by aligning all the "sharp" wire field signals to mitigate the eddy current effect using both in-phase (I-channel) and quadrature-phase (Q-channel) images; (ii) magnetic image alignment that addresses skew effects caused by any misalignment of the scanning SQUID microscope relative to the wire segments; and (iii) an inversion method for converting magnetic fields to magnetic currents by integrating the Biot-Savart Law with FFT. The results show that the SPIM improves I-channel sharpness by 0.3% and reduces Q-channel sharpness by 25%. Also, we were able to remove rotational and skew misalignments of 0.30 in a real image. Overall, SPIM highlights the potential of combining spatial analysis with physics-driven models in practical applications.
* copyright 2025 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Double Oracle Neural Architecture Search for Game Theoretic Deep Learning Models
Oct 07, 2024



In this paper, we propose a new approach to train deep learning models using game theory concepts including Generative Adversarial Networks (GANs) and Adversarial Training (AT) where we deploy a double-oracle framework using best response oracles. GAN is essentially a two-player zero-sum game between the generator and the discriminator. The same concept can be applied to AT with attacker and classifier as players. Training these models is challenging as a pure Nash equilibrium may not exist and even finding the mixed Nash equilibrium is difficult as training algorithms for both GAN and AT have a large-scale strategy space. Extending our preliminary model DO-GAN, we propose the methods to apply the double oracle framework concept to Adversarial Neural Architecture Search (NAS for GAN) and Adversarial Training (NAS for AT) algorithms. We first generalize the players' strategies as the trained models of generator and discriminator from the best response oracles. We then compute the meta-strategies using a linear program. For scalability of the framework where multiple network models of best responses are stored in the memory, we prune the weakly-dominated players' strategies to keep the oracles from becoming intractable. Finally, we conduct experiments on MNIST, CIFAR-10 and TinyImageNet for DONAS-GAN. We also evaluate the robustness under FGSM and PGD attacks on CIFAR-10, SVHN and TinyImageNet for DONAS-AT. We show that all our variants have significant improvements in both subjective qualitative evaluation and quantitative metrics, compared with their respective base architectures.
Continual learning with task specialist
Sep 26, 2024



Continual learning (CL) adapt the deep learning scenarios with timely updated datasets. However, existing CL models suffer from the catastrophic forgetting issue, where new knowledge replaces past learning. In this paper, we propose Continual Learning with Task Specialists (CLTS) to address the issues of catastrophic forgetting and limited labelled data in real-world datasets by performing class incremental learning of the incoming stream of data. The model consists of Task Specialists (T S) and Task Predictor (T P ) with pre-trained Stable Diffusion (SD) module. Here, we introduce a new specialist to handle a new task sequence and each T S has three blocks; i) a variational autoencoder (V AE) to learn the task distribution in a low dimensional latent space, ii) a K-Means block to perform data clustering and iii) Bootstrapping Language-Image Pre-training (BLIP ) model to generate a small batch of captions from the input data. These captions are fed as input to the pre-trained stable diffusion model (SD) for the generation of task samples. The proposed model does not store any task samples for replay, instead uses generated samples from SD to train the T P module. A comparison study with four SOTA models conducted on three real-world datasets shows that the proposed model outperforms all the selected baselines
XMOL: Explainable Multi-property Optimization of Molecules
Sep 12, 2024


Molecular optimization is a key challenge in drug discovery and material science domain, involving the design of molecules with desired properties. Existing methods focus predominantly on single-property optimization, necessitating repetitive runs to target multiple properties, which is inefficient and computationally expensive. Moreover, these methods often lack transparency, making it difficult for researchers to understand and control the optimization process. To address these issues, we propose a novel framework, Explainable Multi-property Optimization of Molecules (XMOL), to optimize multiple molecular properties simultaneously while incorporating explainability. Our approach builds on state-of-the-art geometric diffusion models, extending them to multi-property optimization through the introduction of spectral normalization and enhanced molecular constraints for stabilized training. Additionally, we integrate interpretive and explainable techniques throughout the optimization process. We evaluated XMOL on the real-world molecular datasets i.e., QM9, demonstrating its effectiveness in both single property and multiple properties optimization while offering interpretable results, paving the way for more efficient and reliable molecular design.
U-TELL: Unsupervised Task Expert Lifelong Learning
May 23, 2024



Continual learning (CL) models are designed to learn new tasks arriving sequentially without re-training the network. However, real-world ML applications have very limited label information and these models suffer from catastrophic forgetting. To address these issues, we propose an unsupervised CL model with task experts called Unsupervised Task Expert Lifelong Learning (U-TELL) to continually learn the data arriving in a sequence addressing catastrophic forgetting. During training of U-TELL, we introduce a new expert on arrival of a new task. Our proposed architecture has task experts, a structured data generator and a task assigner. Each task expert is composed of 3 blocks; i) a variational autoencoder to capture the task distribution and perform data abstraction, ii) a k-means clustering module, and iii) a structure extractor to preserve latent task data signature. During testing, task assigner selects a suitable expert to perform clustering. U-TELL does not store or replay task samples, instead, we use generated structured samples to train the task assigner. We compared U-TELL with five SOTA unsupervised CL methods. U-TELL outperformed all baselines on seven benchmarks and one industry dataset for various CL scenarios with a training time over 6 times faster than the best performing baseline.
Self-evolving Autoencoder Embedded Q-Network
Feb 18, 2024



In the realm of sequential decision-making tasks, the exploration capability of a reinforcement learning (RL) agent is paramount for achieving high rewards through interactions with the environment. To enhance this crucial ability, we propose SAQN, a novel approach wherein a self-evolving autoencoder (SA) is embedded with a Q-Network (QN). In SAQN, the self-evolving autoencoder architecture adapts and evolves as the agent explores the environment. This evolution enables the autoencoder to capture a diverse range of raw observations and represent them effectively in its latent space. By leveraging the disentangled states extracted from the encoder generated latent space, the QN is trained to determine optimal actions that improve rewards. During the evolution of the autoencoder architecture, a bias-variance regulatory strategy is employed to elicit the optimal response from the RL agent. This strategy involves two key components: (i) fostering the growth of nodes to retain previously acquired knowledge, ensuring a rich representation of the environment, and (ii) pruning the least contributing nodes to maintain a more manageable and tractable latent space. Extensive experimental evaluations conducted on three distinct benchmark environments and a real-world molecular environment demonstrate that the proposed SAQN significantly outperforms state-of-the-art counterparts. The results highlight the effectiveness of the self-evolving autoencoder and its collaboration with the Q-Network in tackling sequential decision-making tasks.
DO-GAN: A Double Oracle Framework for Generative Adversarial Networks
Feb 17, 2021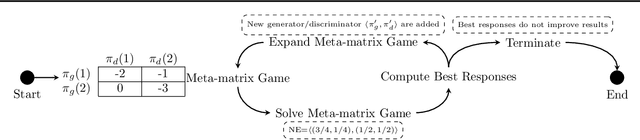
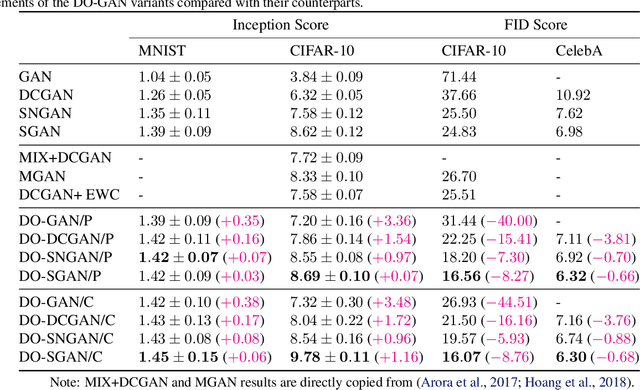

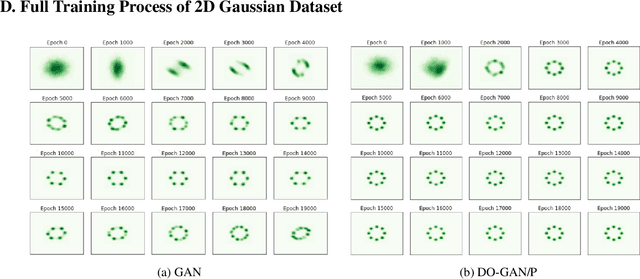
In this paper, we propose a new approach to train Generative Adversarial Networks (GANs) where we deploy a double-oracle framework using the generator and discriminator oracles. GAN is essentially a two-player zero-sum game between the generator and the discriminator. Training GANs is challenging as a pure Nash equilibrium may not exist and even finding the mixed Nash equilibrium is difficult as GANs have a large-scale strategy space. In DO-GAN, we extend the double oracle framework to GANs. We first generalize the players' strategies as the trained models of generator and discriminator from the best response oracles. We then compute the meta-strategies using a linear program. For scalability of the framework where multiple generators and discriminator best responses are stored in the memory, we propose two solutions: 1) pruning the weakly-dominated players' strategies to keep the oracles from becoming intractable; 2) applying continual learning to retain the previous knowledge of the networks. We apply our framework to established GAN architectures such as vanilla GAN, Deep Convolutional GAN, Spectral Normalization GAN and Stacked GAN. Finally, we conduct experiments on MNIST, CIFAR-10 and CelebA datasets and show that DO-GAN variants have significant improvements in both subjective qualitative evaluation and quantitative metrics, compared with their respective GAN architectures.