 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpus 100
Papers and Code
Regional Bias in Large Language Models
Jan 22, 2026This study investigates regional bias in large language models (LLMs), an emerging concern in AI fairness and global representation. We evaluate ten prominent LLMs: GPT-3.5, GPT-4o, Gemini 1.5 Flash, Gemini 1.0 Pro, Claude 3 Opus, Claude 3.5 Sonnet, Llama 3, Gemma 7B, Mistral 7B, and Vicuna-13B using a dataset of 100 carefully designed prompts that probe forced-choice decisions between regions under contextually neutral scenarios. We introduce FAZE, a prompt-based evaluation framework that measures regional bias on a 10-point scale, where higher scores indicate a stronger tendency to favor specific regions. Experimental results reveal substantial variation in bias levels across models, with GPT-3.5 exhibiting the highest bias score (9.5) and Claude 3.5 Sonnet scoring the lowest (2.5). These findings indicate that regional bias can meaningfully undermine the reliability, fairness, and inclusivity of LLM outputs in real-world, cross-cultural applications. This work contributes to AI fairness research by highlighting the importance of inclusive evaluation frameworks and systematic approaches for identifying and mitigating geographic biases in language models.
Does Inference Scaling Improve Reasoning Faithfulness? A Multi-Model Analysis of Self-Consistency Tradeoffs
Jan 10, 2026Self-consistency has emerged as a popular technique for improving large language model accuracy on reasoning tasks. The approach is straightforward: generate multiple reasoning paths and select the most common answer through majority voting. While this reliably boosts accuracy, it remains unclear whether these gains reflect genuine improvements in reasoning quality. We investigate a fundamental question that has not been studied before: does inference scaling improve reasoning faithfulness? We conduct a comprehensive empirical study across four frontier models (GPT-5.2, Claude Opus 4.5, Gemini-3-flash-preview, and DeepSeek-v3.2) on 100 GSM8K mathematical reasoning problems. Our analysis employs bootstrap confidence intervals, McNemar's tests for paired comparisons, and Cohen's d effect sizes to quantify the effects rigorously. The results reveal striking differences across models that challenge common assumptions about self-consistency. GPT-5.2 shows the expected pattern: accuracy improves from 78% to 90% at N=5, with faithfulness remaining relatively stable (0.540 to 0.510). Claude Opus 4.5 tells a completely different story. Its accuracy actually drops from 78% to 74.3% while faithfulness jumps dramatically from 0.270 to 0.891 at N=5. DeepSeek-v3.2, already at 98% accuracy, shows ceiling effects with modest faithfulness gains (0.440 to 0.541). Gemini-3-flash improves from 81% to 86% accuracy with a slight faithfulness decrease (0.260 to 0.212). Problem difficulty analysis reveals that GPT-5.2 solves 82% of hard problems while breaking only 13% of easy ones. Claude, in contrast, breaks 23% of easy problems, explaining its accuracy decrease. These findings matter for practitioners: self-consistency is not universally beneficial, and teams should test their specific models before deployment. We release our code and provide practical recommendations for navigating these tradeoffs.
Can Large Language Models Solve Engineering Equations? A Systematic Comparison of Direct Prediction and Solver-Assisted Approaches
Jan 05, 2026Transcendental equations requiring iterative numerical solution pervade engineering practice, from fluid mechanics friction factor calculations to orbital position determination. We systematically evaluate whether Large Language Models can solve these equations through direct numerical prediction or whether a hybrid architecture combining LLM symbolic manipulation with classical iterative solvers proves more effective. Testing six state-of-the-art models (GPT-5.1, GPT-5.2, Gemini-3-Flash, Gemini-2.5-Lite, Claude-Sonnet-4.5, Claude-Opus-4.5) on 100 problems spanning seven engineering domains, we compare direct prediction against solver-assisted computation where LLMs formulate governing equations and provide initial conditions while Newton-Raphson iteration performs numerical solution. Direct prediction yields mean relative errors of 0.765 to 1.262 across models, while solver-assisted computation achieves 0.225 to 0.301, representing error reductions of 67.9% to 81.8%. Domain-specific analysis reveals dramatic improvements in Electronics (93.1%) due to exponential equation sensitivity, contrasted with modest gains in Fluid Mechanics (7.2%) where LLMs exhibit effective pattern recognition. These findings establish that contemporary LLMs excel at symbolic manipulation and domain knowledge retrieval but struggle with precision-critical iterative arithmetic, suggesting their optimal deployment as intelligent interfaces to classical numerical solvers rather than standalone computational engines.
LegalRikai: Open Benchmark -- Benchmark for Complex Japanese Corporate Legal Tasks
Dec 15, 2025This paper introduces LegalRikai: Open Benchmark, a new benchmark comprising four complex tasks that emulate Japanese corporate legal practices. The benchmark was created by legal professionals under the supervision of an attorney. This benchmark has 100 samples that require long-form, structured outputs, and we evaluated them against multiple practical criteria. We conducted both human and automated evaluations using leading LLMs, including GPT-5, Gemini 2.5 Pro, and Claude Opus 4.1. Our human evaluation revealed that abstract instructions prompted unnecessary modifications, highlighting model weaknesses in document-level editing that were missed by conventional short-text tasks. Furthermore, our analysis reveals that automated evaluation aligns well with human judgment on criteria with clear linguistic grounding, and assessing structural consistency remains a challenge. The result demonstrates the utility of automated evaluation as a screening tool when expert availability is limited. We propose a dataset evaluation framework to promote more practice-oriented research in the legal domain.
AA-Omniscience: Evaluating Cross-Domain Knowledge Reliability in Large Language Models
Nov 17, 2025



Existing language model evaluations primarily measure general capabilities, yet reliable use of these models across a range of domains demands factual accuracy and recognition of knowledge gaps. We introduce AA-Omniscience, a benchmark designed to measure both factual recall and knowledge calibration across 6,000 questions. Questions are derived from authoritative academic and industry sources, and cover 42 economically relevant topics within six different domains. The evaluation measures a model's Omniscience Index, a bounded metric (-100 to 100) measuring factual recall that jointly penalizes hallucinations and rewards abstention when uncertain, with 0 equating to a model that answers questions correctly as much as it does incorrectly. Among evaluated models, Claude 4.1 Opus attains the highest score (4.8), making it one of only three models to score above zero. These results reveal persistent factuality and calibration weaknesses across frontier models. Performance also varies by domain, with the models from three different research labs leading across the six domains. This performance variability suggests models should be chosen according to the demands of the use case rather than general performance for tasks where knowledge is important.
ORGEval: Graph-Theoretic Evaluation of LLMs in Optimization Modeling
Oct 31, 2025Formulating optimization problems for industrial applications demands significant manual effort and domain expertise. While Large Language Models (LLMs) show promise in automating this process, evaluating their performance remains difficult due to the absence of robust metrics. Existing solver-based approaches often face inconsistency, infeasibility issues, and high computational costs. To address these issues, we propose ORGEval, a graph-theoretic evaluation framework for assessing LLMs' capabilities in formulating linear and mixed-integer linear programs. ORGEval represents optimization models as graphs, reducing equivalence detection to graph isomorphism testing. We identify and prove a sufficient condition, when the tested graphs are symmetric decomposable (SD), under which the Weisfeiler-Lehman (WL) test is guaranteed to correctly detect isomorphism. Building on this, ORGEval integrates a tailored variant of the WL-test with an SD detection algorithm to evaluate model equivalence. By focusing on structural equivalence rather than instance-level configurations, ORGEval is robust to numerical variations. Experimental results show that our method can successfully detect model equivalence and produce 100\% consistent results across random parameter configurations, while significantly outperforming solver-based methods in runtime, especially on difficult problems. Leveraging ORGEval, we construct the Bench4Opt dataset and benchmark state-of-the-art LLMs on optimization modeling. Our results reveal that although optimization modeling remains challenging for all LLMs, DeepSeek-V3 and Claude-Opus-4 achieve the highest accuracies under direct prompting, outperforming even leading reasoning models.
Reactor Mk.1 performances: MMLU, HumanEval and BBH test results
Jun 15, 2024
The paper presents the performance results of Reactor Mk.1, ARCs flagship large language model, through a benchmarking process analysis. The model utilizes the Lychee AI engine and possesses less than 100 billion parameters, resulting in a combination of efficiency and potency. The Reactor Mk.1 outperformed models such as GPT-4o, Claude Opus, and Llama 3, with achieved scores of 92% on the MMLU dataset, 91% on HumanEval dataset, and 88% on BBH dataset. It excels in both managing difficult jobs and reasoning, establishing as a prominent AI solution in the present cutting-edge AI technology.
LACE: A light-weight, causal model for enhancing coded speech through adaptive convolutions
Jul 13, 2023



Classical speech coding uses low-complexity postfilters with zero lookahead to enhance the quality of coded speech, but their effectiveness is limited by their simplicity. Deep Neural Networks (DNNs) can be much more effective, but require high complexity and model size, or added delay. We propose a DNN model that generates classical filter kernels on a per-frame basis with a model of just 300~K parameters and 100~MFLOPS complexity, which is a practical complexity for desktop or mobile device CPUs. The lack of added delay allows it to be integrated into the Opus codec, and we demonstrate that it enables effective wideband encoding for bitrates down to 6 kb/s.
Who is Speaking Actually? Robust and Versatile Speaker Traceability for Voice Conversion
May 09, 2023



Voice conversion (VC), as a voice style transfer technology, is becoming increasingly prevalent while raising serious concerns about its illegal use. Proactively tracing the origins of VC-generated speeches, i.e., speaker traceability, can prevent the misuse of VC, but unfortunately has not been extensively studied. In this paper, we are the first to investigate the speaker traceability for VC and propose a traceable VC framework named VoxTracer. Our VoxTracer is similar to but beyond the paradigm of audio watermarking. We first use unique speaker embedding to represent speaker identity. Then we design a VAE-Glow structure, in which the hiding process imperceptibly integrates the source speaker identity into the VC, and the tracing process accurately recovers the source speaker identity and even the source speech in spite of severe speech quality degradation. To address the speech mismatch between the hiding and tracing processes affected by different distortions, we also adopt an asynchronous training strategy to optimize the VAE-Glow models. The VoxTracer is versatile enough to be applied to arbitrary VC methods and popular audio coding standards. Extensive experiments demonstrate that the VoxTracer achieves not only high imperceptibility in hiding, but also nearly 100% tracing accuracy against various types of audio lossy compressions (AAC, MP3, Opus and SILK) with a broad range of bitrates (16 kbps - 128 kbps) even in a very short time duration (0.74s). Our speech demo is available at https://anonymous.4open.science/w/DEMOofVoxTracer.
Demystify Optimization Challenges in Multilingual Transformers
Apr 20, 2021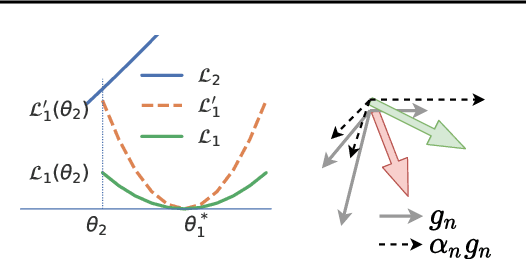
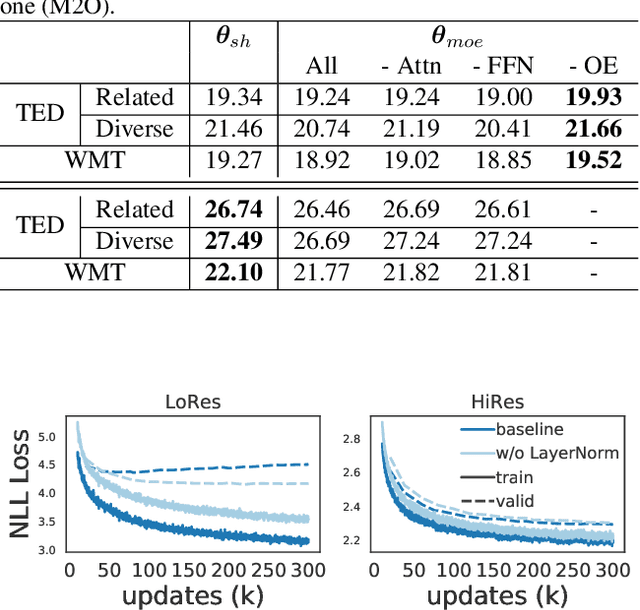
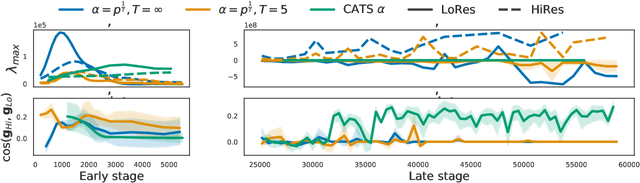
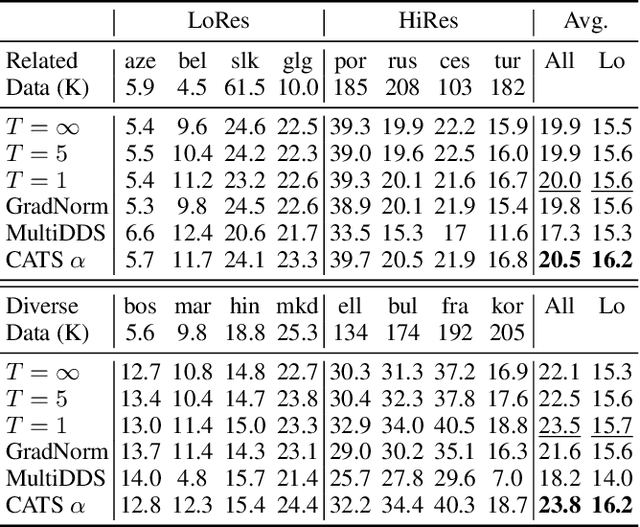
Multilingual Transformer improves parameter efficiency and crosslingual transfer. How to effectively train multilingual models has not been well studied. Using multilingual machine translation as a testbed, we study optimization challenges from loss landscape and parameter plasticity perspectives. We found that imbalanced training data poses task interference between high and low resource languages, characterized by nearly orthogonal gradients for major parameters and the optimization trajectory being mostly dominated by high resource. We show that local curvature of the loss surface affects the degree of interference, and existing heuristics of data subsampling implicitly reduces the sharpness, although still face a trade-off between high and low resource languages. We propose a principled multi-objective optimization algorithm, Curvature Aware Task Scaling (CATS), which improves both optimization and generalization especially for low resource. Experiments on TED, WMT and OPUS-100 benchmarks demonstrate that CATS advances the Pareto front of accuracy while being efficient to apply to massive multilingual settings at the scale of 100 languages.