 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegalRikai: Open Benchmark -- Benchmark for Complex Japanese Corporate Legal Tasks
Dec 15, 2025This paper introduces LegalRikai: Open Benchmark, a new benchmark comprising four complex tasks that emulate Japanese corporate legal practices. The benchmark was created by legal professionals under the supervision of an attorney. This benchmark has 100 samples that require long-form, structured outputs, and we evaluated them against multiple practical criteria. We conducted both human and automated evaluations using leading LLMs, including GPT-5, Gemini 2.5 Pro, and Claude Opus 4.1. Our human evaluation revealed that abstract instructions prompted unnecessary modifications, highlighting model weaknesses in document-level editing that were missed by conventional short-text tasks. Furthermore, our analysis reveals that automated evaluation aligns well with human judgment on criteria with clear linguistic grounding, and assessing structural consistency remains a challenge. The result demonstrates the utility of automated evaluation as a screening tool when expert availability is limited. We propose a dataset evaluation framework to promote more practice-oriented research in the legal domain.
Diverse and Non-redundant Answer Set Extraction on Community QA based on DPPs
Nov 18, 2020
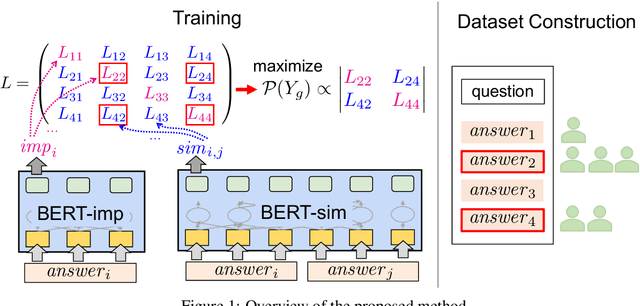

In community-based question answering (CQA) platforms, it takes time for a user to get useful information from among many answers. Although one solution is an answer ranking method, the user still needs to read through the top-ranked answers carefully. This paper proposes a new task of selecting a diverse and non-redundant answer set rather than ranking the answers. Our method is based on determinantal point processes (DPPs), and it calculates the answer importance and similarity between answers by using BERT. We built a dataset focusing on a Japanese CQA site, and the experiments on this dataset demonstrated that the proposed method outperformed several baseline methods.
Pointing to Subwords for Generating Function Names in Source Code
Nov 09, 2020
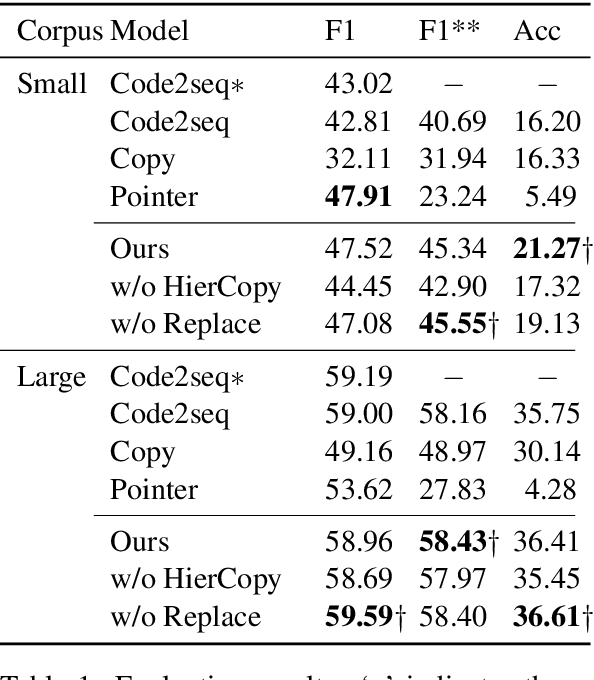
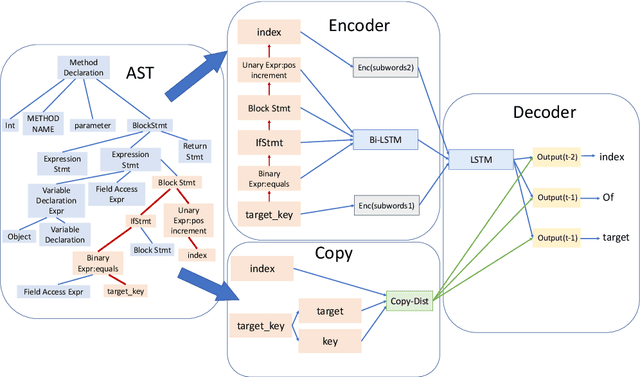
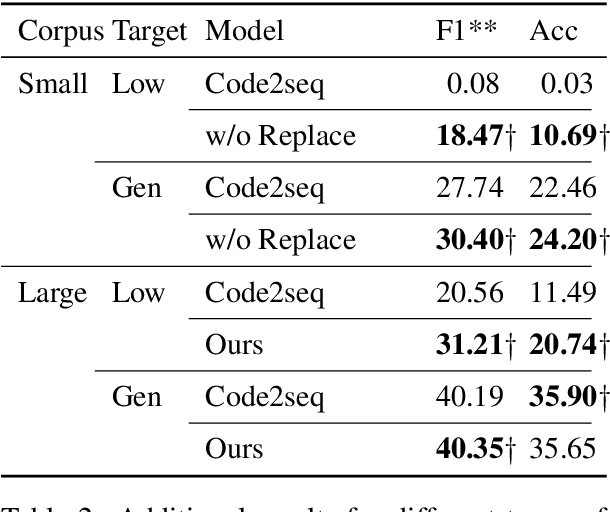
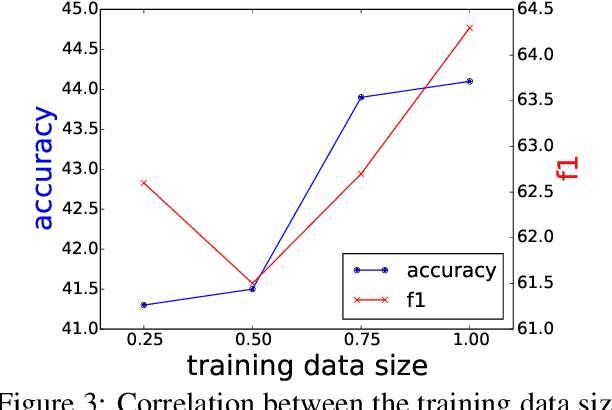
We tackle the task of automatically generating a function name from source code. Existing generators face difficulties in generating low-frequency or out-of-vocabulary subwords. In this paper, we propose two strategies for copying low-frequency or out-of-vocabulary subwords in inputs. Our best performing model showed an improvement over the conventional method in terms of our modified F1 and accuracy on the Java-small and Java-large datasets.