 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Genre Transfer
Music genre transfer is the process of transforming the genre of a music audio clip from one genre to another.
Papers and Code
Adopting State-of-the-Art Pretrained Audio Representations for Music Recommender Systems
Apr 25, 2026Over the years, Music Information Retrieval (MIR) research community has released various models pretrained on large amounts of music data. Transfer learning showcases the proven effectiveness of pretrained backend models for a broad spectrum of downstream tasks, including auto-tagging and genre classification. However, MIR papers generally do not explore the efficiency of pretrained models for Music Recommender Systems (MRS). In addition, the Recommender Systems community tends to favour traditional end-to-end neural network training. Our research addresses this gap and evaluates the performance of nine pretrained backend models (MusicFM, Music2Vec, MERT, EncodecMAE, Jukebox, MusiCNN, MULE, MuQ and MuQ-MuLan) in the context of MRS. We assess them using five recommendation approaches: K-Nearest Neighbours (KNN), Shallow Neural Network, Contrastive Multi-Modal projection, a Hybrid model, and BERT4Rec both for the hot and cold-start scenarios. Our findings suggest that pretrained audio representations exhibit significant performance disparity between traditional MIR tasks and both hot and cold music recommendations, indicating that valuable aspects of musical information captured by backend models may differ depending on the task. This study establishes a foundation for further exploration of pretrained audio representations to enhance music recommendation systems.
Echoes: A semantically-aligned music deepfake detection dataset
Mar 24, 2026We introduce Echoes, a new dataset for music deepfake detection designed for training and benchmarking detectors under realistic and provider-diverse conditions. Echoes comprises 3,577 tracks (110 hours of audio) spanning multiple genres (pop, rock, electronic), and includes content generated by ten popular AI music generation systems. To prevent shortcut learning and promote robust generalization, the dataset is deliberately constructed to be challenging, enforcing semantic-level alignment between spoofed audio and bona fide references. This alignment is achieved by conditioning generated audio samples directly on bona-fide waveforms or song descriptors. We evaluate Echoes in a cross-dataset setting against three existing AI-generated music datasets using state-of-the-art Wav2Vec2 XLS-R 2B representations. Results show that (i) Echoes is the hardest in-domain dataset; (ii) detectors trained on existing datasets transfer poorly to Echoes; (iii) training on Echoes yields the strongest generalization performance. These findings suggest that provider diversity and semantic alignment help learn more transferable detection cues.
MuseCPBench: an Empirical Study of Music Editing Methods through Music Context Preservation
Dec 16, 2025Music editing plays a vital role in modern music production, with applications in film, broadcasting, and game development. Recent advances in music generation models have enabled diverse editing tasks such as timbre transfer, instrument substitution, and genre transformation. However, many existing works overlook the evaluation of their ability to preserve musical facets that should remain unchanged during editing a property we define as Music Context Preservation (MCP). While some studies do consider MCP, they adopt inconsistent evaluation protocols and metrics, leading to unreliable and unfair comparisons. To address this gap, we introduce the first MCP evaluation benchmark, MuseCPBench, which covers four categories of musical facets and enables comprehensive comparisons across five representative music editing baselines. Through systematic analysis along musical facets, methods, and models, we identify consistent preservation gaps in current music editing methods and provide insightful explanations. We hope our findings offer practical guidance for developing more effective and reliable music editing strategies with strong MCP capability
Tune It Up: Music Genre Transfer and Prediction
Mar 27, 2025Deep generative models have been used in style transfer tasks for images. In this study, we adapt and improve CycleGAN model to perform music style transfer on Jazz and Classic genres. By doing so, we aim to easily generate new songs, cover music to different music genres and reduce the arrangements needed in those processes. We train and use music genre classifier to assess the performance of the transfer models. To that end, we obtain 87.7% accuracy with Multi-layer Perceptron algorithm. To improve our style transfer baseline, we add auxiliary discriminators and triplet loss to our model. According to our experiments, we obtain the best accuracies as 69.4% in Jazz to Classic task and 39.3% in Classic to Jazz task with our developed genre classifier. We also run a subjective experiment and results of it show that the overall performance of our transfer model is good and it manages to conserve melody of inputs on the transferred outputs. Our code is available at https://github.com/ fidansamet/tune-it-up
Fine-Grained control over Music Generation with Activation Steering
Jun 11, 2025We present a method for fine-grained control over music generation through inference-time interventions on an autoregressive generative music transformer called MusicGen. Our approach enables timbre transfer, style transfer, and genre fusion by steering the residual stream using weights of linear probes trained on it, or by steering the attention layer activations in a similar manner. We observe that modelling this as a regression task provides improved performance, hypothesizing that the mean-squared-error better preserve meaningful directional information in the activation space. Combined with the global conditioning offered by text prompts in MusicGen, our method provides both global and local control over music generation. Audio samples illustrating our method are available at our demo page.
ImprovNet: Generating Controllable Musical Improvisations with Iterative Corruption Refinement
Feb 06, 2025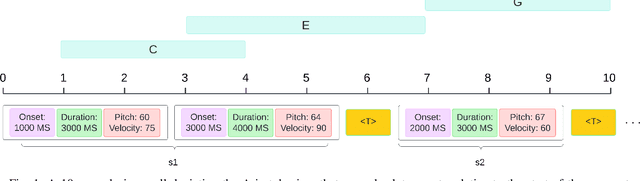
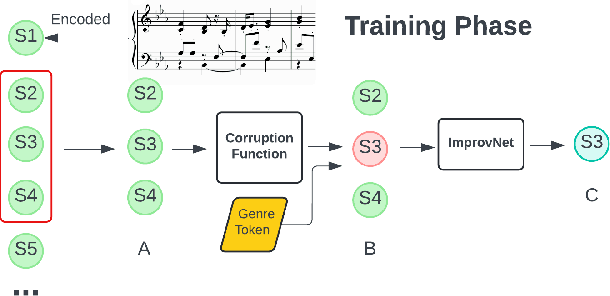
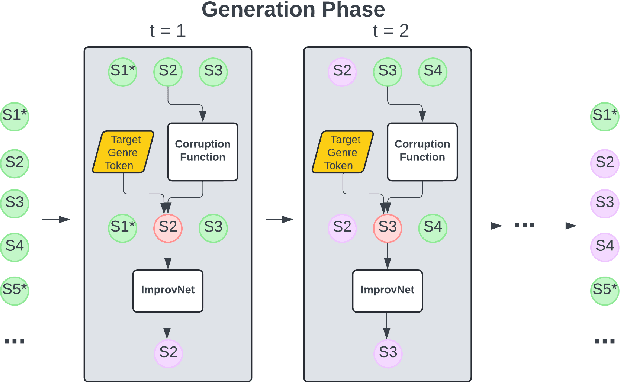
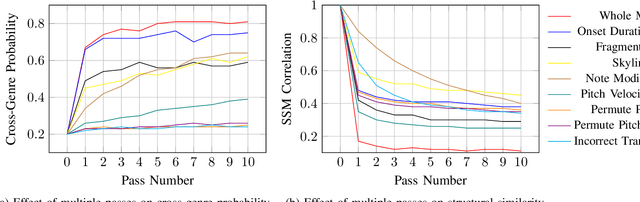
Deep learning has enabled remarkable advances in style transfer across various domains, offering new possibilities for creative content generation. However, in the realm of symbolic music, generating controllable and expressive performance-level style transfers for complete musical works remains challenging due to limited datasets, especially for genres such as jazz, and the lack of unified models that can handle multiple music generation tasks. This paper presents ImprovNet, a transformer-based architecture that generates expressive and controllable musical improvisations through a self-supervised corruption-refinement training strategy. ImprovNet unifies multiple capabilities within a single model: it can perform cross-genre and intra-genre improvisations, harmonize melodies with genre-specific styles, and execute short prompt continuation and infilling tasks. The model's iterative generation framework allows users to control the degree of style transfer and structural similarity to the original composition. Objective and subjective evaluations demonstrate ImprovNet's effectiveness in generating musically coherent improvisations while maintaining structural relationships with the original pieces. The model outperforms Anticipatory Music Transformer in short continuation and infilling tasks and successfully achieves recognizable genre conversion, with 79\% of participants correctly identifying jazz-style improvisations. Our code and demo page can be found at https://github.com/keshavbhandari/improvnet.
Music for All: Exploring Multicultural Representations in Music Generation Models
Feb 12, 2025



The advent of Music-Language Models has greatly enhanced the automatic music generation capability of AI systems, but they are also limited in their coverage of the musical genres and cultures of the world. We present a study of the datasets and research papers for music generation and quantify the bias and under-representation of genres. We find that only 5.7% of the total hours of existing music datasets come from non-Western genres, which naturally leads to disparate performance of the models across genres. We then investigate the efficacy of Parameter-Efficient Fine-Tuning (PEFT) techniques in mitigating this bias. Our experiments with two popular models -- MusicGen and Mustango, for two underrepresented non-Western music traditions -- Hindustani Classical and Turkish Makam music, highlight the promises as well as the non-triviality of cross-genre adaptation of music through small datasets, implying the need for more equitable baseline music-language models that are designed for cross-cultural transfer learning.
Comparative Analysis of Pretrained Audio Representations in Music Recommender Systems
Sep 13, 2024


Over the years, Music Information Retrieval (MIR) has proposed various models pretrained on large amounts of music data. Transfer learning showcases the proven effectiveness of pretrained backend models with a broad spectrum of downstream tasks, including auto-tagging and genre classification. However, MIR papers generally do not explore the efficiency of pretrained models for Music Recommender Systems (MRS). In addition, the Recommender Systems community tends to favour traditional end-to-end neural network learning over these models. Our research addresses this gap and evaluates the applicability of six pretrained backend models (MusicFM, Music2Vec, MERT, EncodecMAE, Jukebox, and MusiCNN) in the context of MRS. We assess their performance using three recommendation models: K-nearest neighbours (KNN), shallow neural network, and BERT4Rec. Our findings suggest that pretrained audio representations exhibit significant performance variability between traditional MIR tasks and MRS, indicating that valuable aspects of musical information captured by backend models may differ depending on the task. This study establishes a foundation for further exploration of pretrained audio representations to enhance music recommendation systems.
Audio Prompt Adapter: Unleashing Music Editing Abilities for Text-to-Music with Lightweight Finetuning
Jul 24, 2024



Text-to-music models allow users to generate nearly realistic musical audio with textual commands. However, editing music audios remains challenging due to the conflicting desiderata of performing fine-grained alterations on the audio while maintaining a simple user interface. To address this challenge, we propose Audio Prompt Adapter (or AP-Adapter), a lightweight addition to pretrained text-to-music models. We utilize AudioMAE to extract features from the input audio, and construct attention-based adapters to feedthese features into the internal layers of AudioLDM2, a diffusion-based text-to-music model. With 22M trainable parameters, AP-Adapter empowers users to harness both global (e.g., genre and timbre) and local (e.g., melody) aspects of music, using the original audio and a short text as inputs. Through objective and subjective studies, we evaluate AP-Adapter on three tasks: timbre transfer, genre transfer, and accompaniment generation. Additionally, we demonstrate its effectiveness on out-of-domain audios containing unseen instruments during training.
Combining audio control and style transfer using latent diffusion
Jul 31, 2024



Deep generative models are now able to synthesize high-quality audio signals, shifting the critical aspect in their development from audio quality to control capabilities. Although text-to-music generation is getting largely adopted by the general public, explicit control and example-based style transfer are more adequate modalities to capture the intents of artists and musicians. In this paper, we aim to unify explicit control and style transfer within a single model by separating local and global information to capture musical structure and timbre respectively. To do so, we leverage the capabilities of diffusion autoencoders to extract semantic features, in order to build two representation spaces. We enforce disentanglement between those spaces using an adversarial criterion and a two-stage training strategy. Our resulting model can generate audio matching a timbre target, while specifying structure either with explicit controls or through another audio example. We evaluate our model on one-shot timbre transfer and MIDI-to-audio tasks on instrumental recordings and show that we outperform existing baselines in terms of audio quality and target fidelity. Furthermore, we show that our method can generate cover versions of complete musical pieces by transferring rhythmic and melodic content to the style of a target audio in a different genre.
* ISMIR 2024