 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdopting State-of-the-Art Pretrained Audio Representations for Music Recommender Systems
Apr 25, 2026Over the years, Music Information Retrieval (MIR) research community has released various models pretrained on large amounts of music data. Transfer learning showcases the proven effectiveness of pretrained backend models for a broad spectrum of downstream tasks, including auto-tagging and genre classification. However, MIR papers generally do not explore the efficiency of pretrained models for Music Recommender Systems (MRS). In addition, the Recommender Systems community tends to favour traditional end-to-end neural network training. Our research addresses this gap and evaluates the performance of nine pretrained backend models (MusicFM, Music2Vec, MERT, EncodecMAE, Jukebox, MusiCNN, MULE, MuQ and MuQ-MuLan) in the context of MRS. We assess them using five recommendation approaches: K-Nearest Neighbours (KNN), Shallow Neural Network, Contrastive Multi-Modal projection, a Hybrid model, and BERT4Rec both for the hot and cold-start scenarios. Our findings suggest that pretrained audio representations exhibit significant performance disparity between traditional MIR tasks and both hot and cold music recommendations, indicating that valuable aspects of musical information captured by backend models may differ depending on the task. This study establishes a foundation for further exploration of pretrained audio representations to enhance music recommendation systems.
Leveraging Artist Catalogs for Cold-Start Music Recommendation
Apr 08, 2026The item cold-start problem poses a fundamental challenge for music recommendation: newly added tracks lack the interaction history that collaborative filtering (CF) requires. Existing approaches often address this problem by learning mappings from content features such as audio, text, and metadata to the CF latent space. However, previous works either omit artist information or treat it as just another input modality, missing the fundamental hierarchy of artists and items. Since most new tracks come from artists with previous history available, we frame cold-start track recommendation as 'semi-cold' by leveraging the rich collaborative signal that exists at the artist level. We show that artist-aware methods can more than double Recall and NDCG compared to content-only baselines, and propose ACARec, an attention-based architecture that generates CF embeddings for new tracks by attending over the artist's existing catalog. We show that our approach has notable advantages in predicting user preferences for new tracks, especially for new artist discovery and more accurate estimation of cold item popularity.
Comparative Analysis of Pretrained Audio Representations in Music Recommender Systems
Sep 13, 2024


Over the years, Music Information Retrieval (MIR) has proposed various models pretrained on large amounts of music data. Transfer learning showcases the proven effectiveness of pretrained backend models with a broad spectrum of downstream tasks, including auto-tagging and genre classification. However, MIR papers generally do not explore the efficiency of pretrained models for Music Recommender Systems (MRS). In addition, the Recommender Systems community tends to favour traditional end-to-end neural network learning over these models. Our research addresses this gap and evaluates the applicability of six pretrained backend models (MusicFM, Music2Vec, MERT, EncodecMAE, Jukebox, and MusiCNN) in the context of MRS. We assess their performance using three recommendation models: K-nearest neighbours (KNN), shallow neural network, and BERT4Rec. Our findings suggest that pretrained audio representations exhibit significant performance variability between traditional MIR tasks and MRS, indicating that valuable aspects of musical information captured by backend models may differ depending on the task. This study establishes a foundation for further exploration of pretrained audio representations to enhance music recommendation systems.
Quality Metrics in Recommender Systems: Do We Calculate Metrics Consistently?
Jun 26, 2022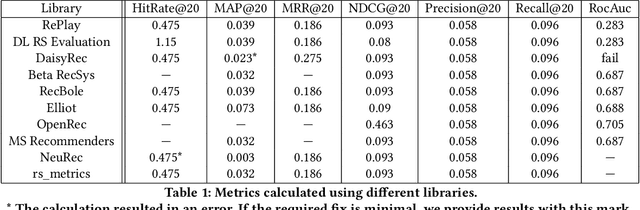
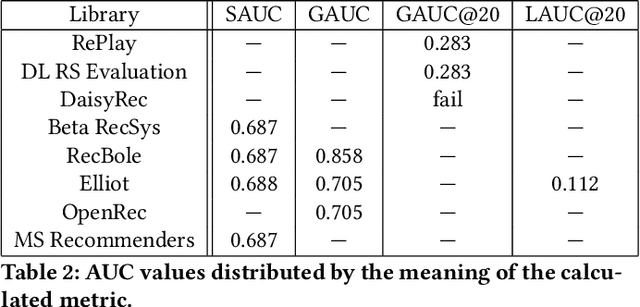

Offline evaluation is a popular approach to determine the best algorithm in terms of the chosen quality metric. However, if the chosen metric calculates something unexpected, this miscommunication can lead to poor decisions and wrong conclusions. In this paper, we thoroughly investigate quality metrics used for recommender systems evaluation. We look at the practical aspect of implementations found in modern RecSys libraries and at the theoretical aspect of definitions in academic papers. We find that Precision is the only metric universally understood among papers and libraries, while other metrics may have different interpretations. Metrics implemented in different libraries sometimes have the same name but measure different things, which leads to different results given the same input. When defining metrics in an academic paper, authors sometimes omit explicit formulations or give references that do not contain explanations either. In 47% of cases, we cannot easily know how the metric is defined because the definition is not clear or absent. These findings highlight yet another difficulty in recommender system evaluation and call for a more detailed description of evaluation protocols.