 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListops
Papers and Code
NRGPT: An Energy-based Alternative for GPT
Dec 18, 2025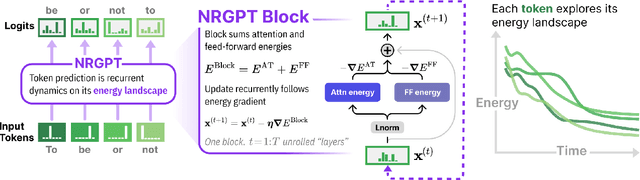
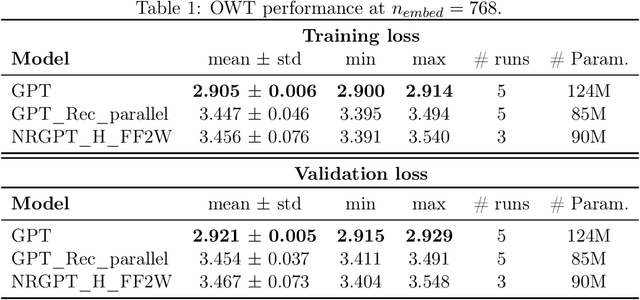
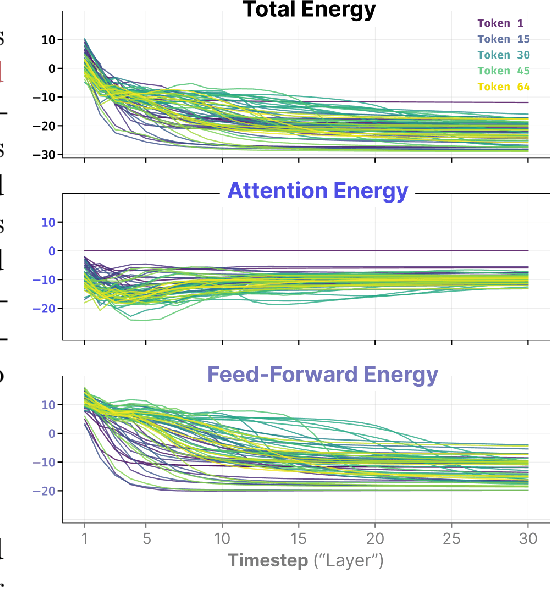

Generative Pre-trained Transformer (GPT) architectures are the most popular design for language modeling. Energy-based modeling is a different paradigm that views inference as a dynamical process operating on an energy landscape. We propose a minimal modification of the GPT setting to unify it with the EBM framework. The inference step of our model, which we call eNeRgy-GPT (NRGPT), is conceptualized as an exploration of the tokens on the energy landscape. We prove, and verify empirically, that under certain circumstances this exploration becomes gradient descent, although they don't necessarily lead to the best performing models. We demonstrate that our model performs well for simple language (Shakespeare dataset), algebraic ListOPS tasks, and richer settings such as OpenWebText language modeling. We also observe that our models may be more resistant to overfitting, doing so only during very long training.
Context Is Not Comprehension
Jun 08, 2025The dominant evaluation of Large Language Models has centered on their ability to surface explicit facts from increasingly vast contexts. While today's best models demonstrate near-perfect recall on these tasks, this apparent success masks a fundamental failure in multi-step computation when information is embedded in a narrative. We introduce Verbose ListOps (VLO), a novel benchmark designed to isolate this failure. VLO programmatically weaves deterministic, nested computations into coherent stories, forcing models to track and update internal state rather than simply locate explicit values. Our experiments show that leading LLMs, capable of solving the raw ListOps equations with near-perfect accuracy, collapse in performance on VLO at just 10k tokens. The VLO framework is extensible to any verifiable reasoning task, providing a critical tool to move beyond simply expanding context windows and begin building models with the robust, stateful comprehension required for complex knowledge work.
Verbose ListOps (VLO): Beyond Long Context -- Unmasking LLM's Reasoning Blind Spots
Jun 05, 2025Large Language Models (LLMs), whilst great at extracting facts from text, struggle with nested narrative reasoning. Existing long context and multi-hop QA benchmarks inadequately test this, lacking realistic distractors or failing to decouple context length from reasoning complexity, masking a fundamental LLM limitation. We introduce Verbose ListOps, a novel benchmark that programmatically transposes ListOps computations into lengthy, coherent stories. This uniquely forces internal computation and state management of nested reasoning problems by withholding intermediate results, and offers fine-grained controls for both narrative size \emph{and} reasoning difficulty. Whilst benchmarks like LongReason (2025) advance approaches for synthetically expanding the context size of multi-hop QA problems, Verbose ListOps pinpoints a specific LLM vulnerability: difficulty in state management for nested sub-reasoning amongst semantically-relevant, distracting narrative. Our experiments show that leading LLMs (e.g., OpenAI o4, Gemini 2.5 Pro) collapse in performance on Verbose ListOps at modest (~10k token) narrative lengths, despite effortlessly solving raw ListOps equations. Addressing this failure is paramount for real-world text interpretation which requires identifying key reasoning points, tracking conceptual intermediate results, and filtering irrelevant information. Verbose ListOps, and its extensible generation framework thus enables targeted reasoning enhancements beyond mere context-window expansion; a critical step to automating the world's knowledge work.
Small Models, Smarter Learning: The Power of Joint Task Training
May 23, 2025The ability of a model to learn a task depends strongly on both the task difficulty and the model size. We aim to understand how task difficulty relates to the minimum number of parameters required for learning specific tasks in small transformer models. Our study focuses on the ListOps dataset, which consists of nested mathematical operations. We gradually increase task difficulty by introducing new operations or combinations of operations into the training data. We observe that sum modulo n is the hardest to learn. Curiously, when combined with other operations such as maximum and median, the sum operation becomes easier to learn and requires fewer parameters. We show that joint training not only improves performance but also leads to qualitatively different model behavior. We show evidence that models trained only on SUM might be memorizing and fail to capture the number structure in the embeddings. In contrast, models trained on a mixture of SUM and other operations exhibit number-like representations in the embedding space, and a strong ability to distinguish parity. Furthermore, the SUM-only model relies more heavily on its feedforward layers, while the jointly trained model activates the attention mechanism more. Finally, we show that learning pure SUM can be induced in models below the learning threshold of pure SUM, by pretraining them on MAX+MED. Our findings indicate that emergent abilities in language models depend not only on model size, but also the training curriculum.
Recurrent Transformers with Dynamic Halt
Feb 01, 2024In this paper, we study the inductive biases of two major approaches to augmenting Transformers with a recurrent mechanism - (1) the approach of incorporating a depth-wise recurrence similar to Universal Transformers; and (2) the approach of incorporating a chunk-wise temporal recurrence like Temporal Latent Bottleneck. Furthermore, we propose and investigate novel ways to extend and combine the above methods - for example, we propose a global mean-based dynamic halting mechanism for Universal Transformer and an augmentation of Temporal Latent Bottleneck with elements from Universal Transformer. We compare the models and probe their inductive biases in several diagnostic tasks such as Long Range Arena (LRA), flip-flop language modeling, ListOps, and Logical Inference.
Cached Transformers: Improving Transformers with Differentiable Memory Cache
Dec 20, 2023This work introduces a new Transformer model called Cached Transformer, which uses Gated Recurrent Cached (GRC) attention to extend the self-attention mechanism with a differentiable memory cache of tokens. GRC attention enables attending to both past and current tokens, increasing the receptive field of attention and allowing for exploring long-range dependencies. By utilizing a recurrent gating unit to continuously update the cache, our model achieves significant advancements in \textbf{six} language and vision tasks, including language modeling, machine translation, ListOPs, image classification, object detection, and instance segmentation. Furthermore, our approach surpasses previous memory-based techniques in tasks such as language modeling and displays the ability to be applied to a broader range of situations.
Recursion in Recursion: Two-Level Nested Recursion for Length Generalization with Scalability
Nov 08, 2023



Binary Balanced Tree RvNNs (BBT-RvNNs) enforce sequence composition according to a preset balanced binary tree structure. Thus, their non-linear recursion depth is just $\log_2 n$ ($n$ being the sequence length). Such logarithmic scaling makes BBT-RvNNs efficient and scalable on long sequence tasks such as Long Range Arena (LRA). However, such computational efficiency comes at a cost because BBT-RvNNs cannot solve simple arithmetic tasks like ListOps. On the flip side, RvNNs (e.g., Beam Tree RvNN) that do succeed on ListOps (and other structure-sensitive tasks like formal logical inference) are generally several times more expensive than even RNNs. In this paper, we introduce a novel framework -- Recursion in Recursion (RIR) to strike a balance between the two sides - getting some of the benefits from both worlds. In RIR, we use a form of two-level nested recursion - where the outer recursion is a $k$-ary balanced tree model with another recursive model (inner recursion) implementing its cell function. For the inner recursion, we choose Beam Tree RvNNs (BT-RvNN). To adjust BT-RvNNs within RIR we also propose a novel strategy of beam alignment. Overall, this entails that the total recursive depth in RIR is upper-bounded by $k \log_k n$. Our best RIR-based model is the first model that demonstrates high ($\geq 90\%$) length-generalization performance on ListOps while at the same time being scalable enough to be trainable on long sequence inputs from LRA. Moreover, in terms of accuracy in the LRA language tasks, it performs competitively with Structured State Space Models (SSMs) without any special initialization - outperforming Transformers by a large margin. On the other hand, while SSMs can marginally outperform RIR on LRA, they (SSMs) fail to length-generalize on ListOps. Our code is available at: \url{https://github.com/JRC1995/BeamRecursionFamily/}.
Efficient Beam Tree Recursion
Jul 20, 2023



Beam Tree Recursive Neural Network (BT-RvNN) was recently proposed as a simple extension of Gumbel Tree RvNN and it was shown to achieve state-of-the-art length generalization performance in ListOps while maintaining comparable performance on other tasks. However, although not the worst in its kind, BT-RvNN can be still exorbitantly expensive in memory usage. In this paper, we identify the main bottleneck in BT-RvNN's memory usage to be the entanglement of the scorer function and the recursive cell function. We propose strategies to remove this bottleneck and further simplify its memory usage. Overall, our strategies not only reduce the memory usage of BT-RvNN by $10$-$16$ times but also create a new state-of-the-art in ListOps while maintaining similar performance in other tasks. In addition, we also propose a strategy to utilize the induced latent-tree node representations produced by BT-RvNN to turn BT-RvNN from a sentence encoder of the form $f:\mathbb{R}^{n \times d} \rightarrow \mathbb{R}^{d}$ into a sequence contextualizer of the form $f:\mathbb{R}^{n \times d} \rightarrow \mathbb{R}^{n \times d}$. Thus, our proposals not only open up a path for further scalability of RvNNs but also standardize a way to use BT-RvNNs as another building block in the deep learning toolkit that can be easily stacked or interfaced with other popular models such as Transformers and Structured State Space models.
Investigating Pre-trained Language Models on Cross-Domain Datasets, a Step Closer to General AI
Jun 21, 2023



Pre-trained language models have recently emerged as a powerful tool for fine-tuning a variety of language tasks. Ideally, when models are pre-trained on large amount of data, they are expected to gain implicit knowledge. In this paper, we investigate the ability of pre-trained language models to generalize to different non-language tasks. In particular, we test them on tasks from different domains such as computer vision, reasoning on hierarchical data, and protein fold prediction. The four pre-trained models that we used, T5, BART, BERT, and GPT-2 achieve outstanding results. They all have similar performance and they outperform transformers that are trained from scratch by a large margin. For instance, pre-trained language models perform better on the Listops dataset, with an average accuracy of 58.7\%, compared to transformers trained from scratch, which have an average accuracy of 29.0\%. The significant improvement demonstrated across three types of datasets suggests that pre-training on language helps the models to acquire general knowledge, bringing us a step closer to general AI. We also showed that reducing the number of parameters in pre-trained language models does not have a great impact as the performance drops slightly when using T5-Small instead of T5-Base. In fact, when using only 2\% of the parameters, we achieved a great improvement compared to training from scratch. Finally, in contrast to prior work, we find out that using pre-trained embeddings for the input layer is necessary to achieve the desired results.
Opening the Black Box: Analyzing Attention Weights and Hidden States in Pre-trained Language Models for Non-language Tasks
Jun 21, 2023



Investigating deep learning language models has always been a significant research area due to the ``black box" nature of most advanced models. With the recent advancements in pre-trained language models based on transformers and their increasing integration into daily life, addressing this issue has become more pressing. In order to achieve an explainable AI model, it is essential to comprehend the procedural steps involved and compare them with human thought processes. Thus, in this paper, we use simple, well-understood non-language tasks to explore these models' inner workings. Specifically, we apply a pre-trained language model to constrained arithmetic problems with hierarchical structure, to analyze their attention weight scores and hidden states. The investigation reveals promising results, with the model addressing hierarchical problems in a moderately structured manner, similar to human problem-solving strategies. Additionally, by inspecting the attention weights layer by layer, we uncover an unconventional finding that layer 10, rather than the model's final layer, is the optimal layer to unfreeze for the least parameter-intensive approach to fine-tune the model. We support these findings with entropy analysis and token embeddings similarity analysis. The attention analysis allows us to hypothesize that the model can generalize to longer sequences in ListOps dataset, a conclusion later confirmed through testing on sequences longer than those in the training set. Lastly, by utilizing a straightforward task in which the model predicts the winner of a Tic Tac Toe game, we identify limitations in attention analysis, particularly its inability to capture 2D patterns.