 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Clustering with Associative Memories
Jan 02, 2026Deep clustering - joint representation learning and latent space clustering - is a well studied problem especially in computer vision and text processing under the deep learning framework. While the representation learning is generally differentiable, clustering is an inherently discrete optimization task, requiring various approximations and regularizations to fit in a standard differentiable pipeline. This leads to a somewhat disjointed representation learning and clustering. In this work, we propose a novel loss function utilizing energy-based dynamics via Associative Memories to formulate a new deep clustering method, DCAM, which ties together the representation learning and clustering aspects more intricately in a single objective. Our experiments showcase the advantage of DCAM, producing improved clustering quality for various architecture choices (convolutional, residual or fully-connected) and data modalities (images or text).
NRGPT: An Energy-based Alternative for GPT
Dec 18, 2025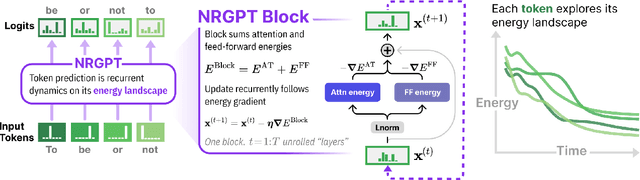
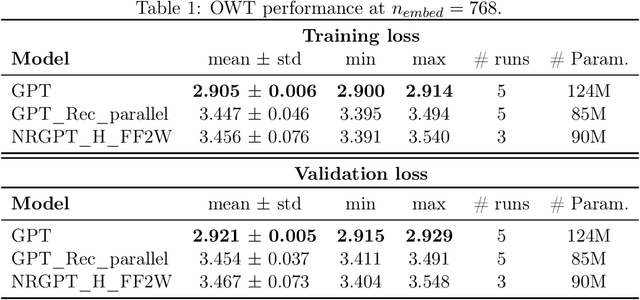
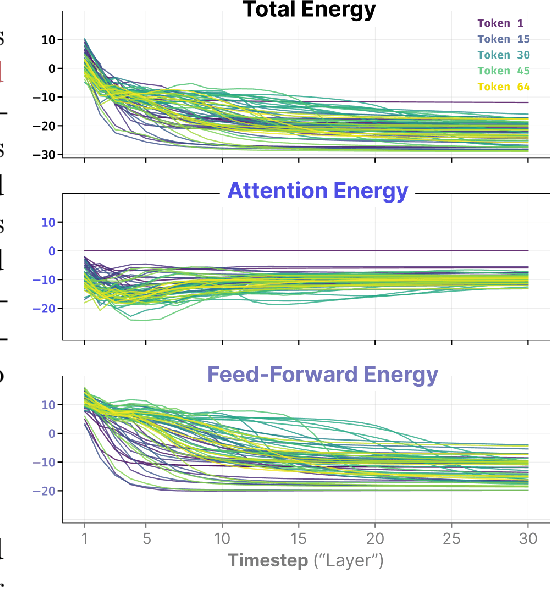

Generative Pre-trained Transformer (GPT) architectures are the most popular design for language modeling. Energy-based modeling is a different paradigm that views inference as a dynamical process operating on an energy landscape. We propose a minimal modification of the GPT setting to unify it with the EBM framework. The inference step of our model, which we call eNeRgy-GPT (NRGPT), is conceptualized as an exploration of the tokens on the energy landscape. We prove, and verify empirically, that under certain circumstances this exploration becomes gradient descent, although they don't necessarily lead to the best performing models. We demonstrate that our model performs well for simple language (Shakespeare dataset), algebraic ListOPS tasks, and richer settings such as OpenWebText language modeling. We also observe that our models may be more resistant to overfitting, doing so only during very long training.
Early diagnosis of autism spectrum disorder using machine learning approaches
Sep 20, 2023



Autistic Spectrum Disorder (ASD) is a neurological disease characterized by difficulties with social interaction, communication, and repetitive activities. The severity of these difficulties varies, and those with this diagnosis face unique challenges. While its primary origin lies in genetics, identifying and addressing it early can contribute to the enhancement of the condition. In recent years, machine learning-driven intelligent diagnosis has emerged as a supplement to conventional clinical approaches, aiming to address the potential drawbacks of time-consuming and costly traditional methods. In this work, we utilize different machine learning algorithms to find the most significant traits responsible for ASD and to automate the diagnostic process. We study six classification models to see which model works best to identify ASD and also study five popular clustering methods to get a meaningful insight of these ASD datasets. To find the best classifier for these binary datasets, we evaluate the models using accuracy, precision, recall, specificity, F1-score, AUC, kappa and log loss metrics. Our evaluation demonstrates that five out of the six selected models perform exceptionally, achieving a 100% accuracy rate on the ASD datasets when hyperparameters are meticulously tuned for each model. As almost all classification models are able to get 100% accuracy, we become interested in observing the underlying insights of the datasets by implementing some popular clustering algorithms on these datasets. We calculate Normalized Mutual Information (NMI), Adjusted Rand Index (ARI) & Silhouette Coefficient (SC) metrics to select the best clustering models. Our evaluation finds that spectral clustering outperforms all other benchmarking clustering models in terms of NMI & ARI metrics and it also demonstrates comparability to the optimal SC achieved by k-means.
End-to-end Differentiable Clustering with Associative Memories
Jun 05, 2023



Clustering is a widely used unsupervised learning technique involving an intensive discrete optimization problem. Associative Memory models or AMs are differentiable neural networks defining a recursive dynamical system, which have been integrated with various deep learning architectures. We uncover a novel connection between the AM dynamics and the inherent discrete assignment necessary in clustering to propose a novel unconstrained continuous relaxation of the discrete clustering problem, enabling end-to-end differentiable clustering with AM, dubbed ClAM. Leveraging the pattern completion ability of AMs, we further develop a novel self-supervised clustering loss. Our evaluations on varied datasets demonstrate that ClAM benefits from the self-supervision, and significantly improves upon both the traditional Lloyd's k-means algorithm, and more recent continuous clustering relaxations (by upto 60% in terms of the Silhouette Coefficient).