 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIrma
Papers and Code
How Can Input Reformulation Improve Tool Usage Accuracy in a Complex Dynamic Environment? A Study on $τ$-bench
Aug 28, 2025Recent advances in reasoning and planning capabilities of large language models (LLMs) have enabled their potential as autonomous agents capable of tool use in dynamic environments. However, in multi-turn conversational environments like $\tau$-bench, these agents often struggle with consistent reasoning, adherence to domain-specific policies, and extracting correct information over a long horizon of tool-calls and conversation. To capture and mitigate these failures, we conduct a comprehensive manual analysis of the common errors occurring in the conversation trajectories. We then experiment with reformulations of inputs to the tool-calling agent for improvement in agent decision making. Finally, we propose the Input-Reformulation Multi-Agent (IRMA) framework, which automatically reformulates user queries augmented with relevant domain rules and tool suggestions for the tool-calling agent to focus on. The results show that IRMA significantly outperforms ReAct, Function Calling, and Self-Reflection by 16.1%, 12.7%, and 19.1%, respectively, in overall pass^5 scores. These findings highlight the superior reliability and consistency of IRMA compared to other methods in dynamic environments.
Potential Paradigm Shift in Hazard Risk Management: AI-Based Weather Forecast for Tropical Cyclone Hazards
Apr 29, 2024



The advents of Artificial Intelligence (AI)-driven models marks a paradigm shift in risk management strategies for meteorological hazards. This study specifically employs tropical cyclones (TCs) as a focal example. We engineer a perturbation-based method to produce ensemble forecasts using the advanced Pangu AI weather model. Unlike traditional approaches that often generate fewer than 20 scenarios from Weather Research and Forecasting (WRF) simulations for one event, our method facilitates the rapid nature of AI-driven model to create thousands of scenarios. We offer open-source access to our model and evaluate its effectiveness through retrospective case studies of significant TC events: Hurricane Irma (2017), Typhoon Mangkhut (2018), and TC Debbie (2017), affecting regions across North America, East Asia, and Australia. Our findings indicate that the AI-generated ensemble forecasts align closely with the European Centre for Medium-Range Weather Forecasts (ECMWF) ensemble predictions up to seven days prior to landfall. This approach could substantially enhance the effectiveness of weather forecast-driven risk analysis and management, providing unprecedented operational speed, user-friendliness, and global applicability.
Iterated Relevance Matrix Analysis (IRMA) for the identification of class-discriminative subspaces
Jan 23, 2024We introduce and investigate the iterated application of Generalized Matrix Learning Vector Quantizaton for the analysis of feature relevances in classification problems, as well as for the construction of class-discriminative subspaces. The suggested Iterated Relevance Matrix Analysis (IRMA) identifies a linear subspace representing the classification specific information of the considered data sets using Generalized Matrix Learning Vector Quantization (GMLVQ). By iteratively determining a new discriminative subspace while projecting out all previously identified ones, a combined subspace carrying all class-specific information can be found. This facilitates a detailed analysis of feature relevances, and enables improved low-dimensional representations and visualizations of labeled data sets. Additionally, the IRMA-based class-discriminative subspace can be used for dimensionality reduction and the training of robust classifiers with potentially improved performance.
A Graphical Model of Hurricane Evacuation Behaviors
Nov 16, 2023Natural disasters such as hurricanes are increasing and causing widespread devastation. People's decisions and actions regarding whether to evacuate or not are critical and have a large impact on emergency planning and response. Our interest lies in computationally modeling complex relationships among various factors influencing evacuation decisions. We conducted a study on the evacuation of Hurricane Irma of the 2017 Atlantic hurricane season. The study was guided by the Protection motivation theory (PMT), a widely-used framework to understand people's responses to potential threats. Graphical models were constructed to represent the complex relationships among the factors involved and the evacuation decision. We evaluated different graphical structures based on conditional independence tests using Irma data. The final model largely aligns with PMT. It shows that both risk perception (threat appraisal) and difficulties in evacuation (coping appraisal) influence evacuation decisions directly and independently. Certain information received from media was found to influence risk perception, and through it influence evacuation behaviors indirectly. In addition, several variables were found to influence both risk perception and evacuation behaviors directly, including family and friends' suggestions, neighbors' evacuation behaviors, and evacuation notices from officials.
Using Twitter Data to Determine Hurricane Category: An Experiment
Aug 10, 2023



Social media posts contain an abundant amount of information about public opinion on major events, especially natural disasters such as hurricanes. Posts related to an event, are usually published by the users who live near the place of the event at the time of the event. Special correlation between the social media data and the events can be obtained using data mining approaches. This paper presents research work to find the mappings between social media data and the severity level of a disaster. Specifically, we have investigated the Twitter data posted during hurricanes Harvey and Irma, and attempted to find the correlation between the Twitter data of a specific area and the hurricane level in that area. Our experimental results indicate a positive correlation between them. We also present a method to predict the hurricane category for a specific area using relevant Twitter data.
Transfer Learning and Bias Correction with Pre-trained Audio Embeddings
Jul 20, 2023



Deep neural network models have become the dominant approach to a large variety of tasks within music information retrieval (MIR). These models generally require large amounts of (annotated) training data to achieve high accuracy. Because not all applications in MIR have sufficient quantities of training data, it is becoming increasingly common to transfer models across domains. This approach allows representations derived for one task to be applied to another, and can result in high accuracy with less stringent training data requirements for the downstream task. However, the properties of pre-trained audio embeddings are not fully understood. Specifically, and unlike traditionally engineered features, the representations extracted from pre-trained deep networks may embed and propagate biases from the model's training regime. This work investigates the phenomenon of bias propagation in the context of pre-trained audio representations for the task of instrument recognition. We first demonstrate that three different pre-trained representations (VGGish, OpenL3, and YAMNet) exhibit comparable performance when constrained to a single dataset, but differ in their ability to generalize across datasets (OpenMIC and IRMAS). We then investigate dataset identity and genre distribution as potential sources of bias. Finally, we propose and evaluate post-processing countermeasures to mitigate the effects of bias, and improve generalization across datasets.
Exploring Isolated Musical Notes as Pre-training Data for Predominant Instrument Recognition in Polyphonic Music
Jun 15, 2023With the growing amount of musical data available, automatic instrument recognition, one of the essential problems in Music Information Retrieval (MIR), is drawing more and more attention. While automatic recognition of single instruments has been well-studied, it remains challenging for polyphonic, multi-instrument musical recordings. This work presents our efforts toward building a robust end-to-end instrument recognition system for polyphonic multi-instrument music. We train our model using a pre-training and fine-tuning approach: we use a large amount of monophonic musical data for pre-training and subsequently fine-tune the model for the polyphonic ensemble. In pre-training, we apply data augmentation techniques to alleviate the domain gap between monophonic musical data and real-world music. We evaluate our method on the IRMAS testing data, a polyphonic musical dataset comprising professionally-produced commercial music recordings. Experimental results show that our best model achieves a micro F1-score of 0.674 and an LRAP of 0.814, meaning 10.9% and 8.9% relative improvement compared with the previous state-of-the-art end-to-end approach. Also, we are able to build a lightweight model, achieving competitive performance with only 519K trainable parameters.
Localisation of Mammographic masses by Greedy Backtracking of Activations in the Stacked Auto-Encoders
May 09, 2023Mammographic image analysis requires accurate localisation of salient mammographic masses. In mammographic computer-aided diagnosis, mass or Region of Interest (ROI) is often marked by physicians and features are extracted from the marked ROI. In this paper, we present a novel mammographic mass localisation framework, based on the maximal class activations of the stacked auto-encoders. We hypothesize that the image regions activating abnormal classes in mammographic images will be the breast masses which causes the anomaly. The experiment is conducted using randomly selected 200 mammographic images (100 normal and 100 abnormal) from IRMA mammographic dataset. Abnormal mass regions marked by an expert radiologist are used as the ground truth. The proposed method outperforms existing Deep Convolutional Neural Network (DCNN) based techniques in terms of salient region detection accuracy. The proposed greedy backtracking method is more efficient and does not require a vast number of labelled training images as in DCNN based method. Such automatic localisation method will assist physicians to make accurate decisions on biopsy recommendations and treatment evaluations.
Constructing Evacuation Evolution Patterns and Decisions Using Mobile Device Location Data: A Case Study of Hurricane Irma
Feb 24, 2021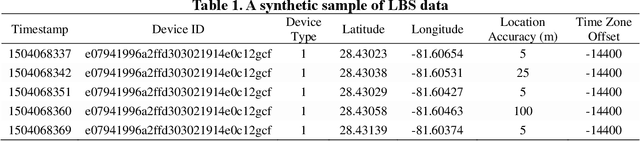
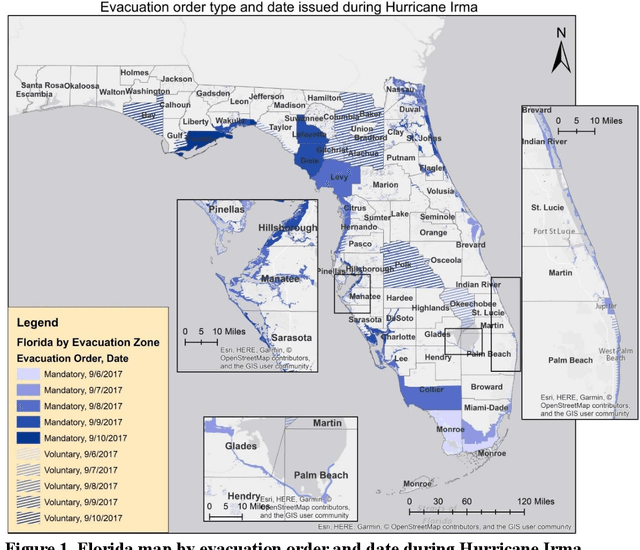
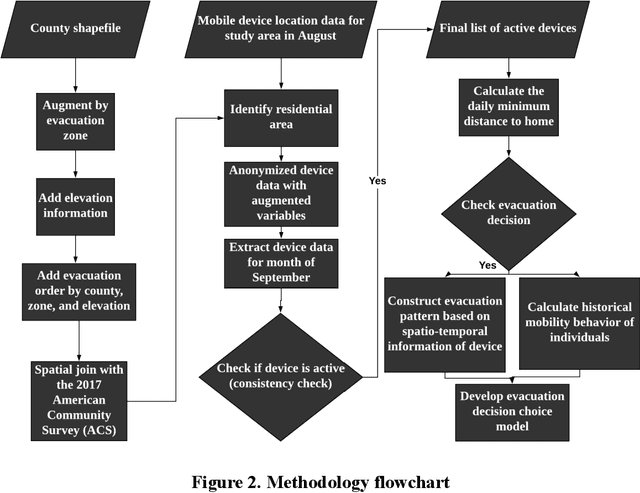
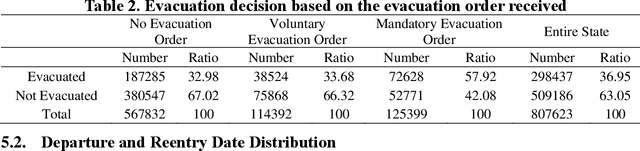
Understanding individuals' behavior during hurricane evacuation is of paramount importance for local, state, and government agencies hoping to be prepared for natural disasters. Complexities involved with human decision-making procedures and lack of data for such disasters are the main reasons that make hurricane evacuation studies challenging. In this paper, we utilized a large mobile phone Location-Based Services (LBS) data to construct the evacuation pattern during the landfall of Hurricane Irma. By employing our proposed framework on more than 11 billion mobile phone location sightings, we were able to capture the evacuation decision of 807,623 smartphone users who were living within the state of Florida. We studied users' evacuation decisions, departure and reentry date distribution, and destination choice. In addition to these decisions, we empirically examined the influence of evacuation order and low-lying residential areas on individuals' evacuation decisions. Our analysis revealed that 57.92% of people living in mandatory evacuation zones evacuated their residences while this ratio was 32.98% and 33.68% for people living in areas with no evacuation order and voluntary evacuation order, respectively. Moreover, our analysis revealed the importance of the individuals' mobility behavior in modeling the evacuation decision choice. Historical mobility behavior information such as number of trips taken by each individual and the spatial area covered by individuals' location trajectory estimated significant in our choice model and improve the overall accuracy of the model significantly.
Deep Convolutional and Recurrent Networks for Polyphonic Instrument Classification from Monophonic Raw Audio Waveforms
Feb 13, 2021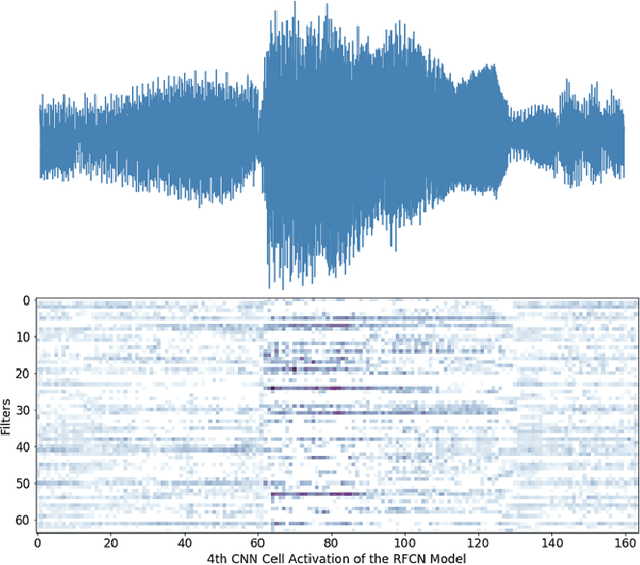
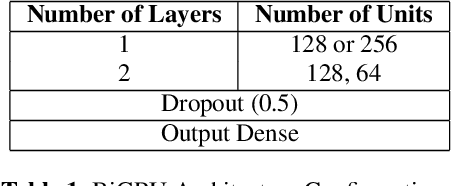
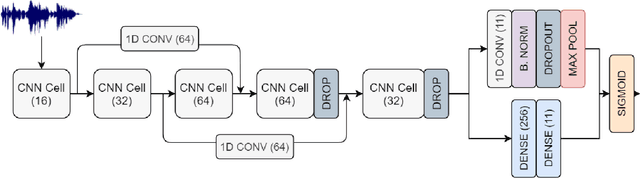

Sound Event Detection and Audio Classification tasks are traditionally addressed through time-frequency representations of audio signals such as spectrograms. However, the emergence of deep neural networks as efficient feature extractors has enabled the direct use of audio signals for classification purposes. In this paper, we attempt to recognize musical instruments in polyphonic audio by only feeding their raw waveforms into deep learning models. Various recurrent and convolutional architectures incorporating residual connections are examined and parameterized in order to build end-to-end classi-fiers with low computational cost and only minimal preprocessing. We obtain competitive classification scores and useful instrument-wise insight through the IRMAS test set, utilizing a parallel CNN-BiGRU model with multiple residual connections, while maintaining a significantly reduced number of trainable parameters.