 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanact12
Papers and Code
Few-shot Human Action Anomaly Detection via a Unified Contrastive Learning Framework
Aug 25, 2025



Human Action Anomaly Detection (HAAD) aims to identify anomalous actions given only normal action data during training. Existing methods typically follow a one-model-per-category paradigm, requiring separate training for each action category and a large number of normal samples. These constraints hinder scalability and limit applicability in real-world scenarios, where data is often scarce or novel categories frequently appear. To address these limitations, we propose a unified framework for HAAD that is compatible with few-shot scenarios. Our method constructs a category-agnostic representation space via contrastive learning, enabling AD by comparing test samples with a given small set of normal examples (referred to as the support set). To improve inter-category generalization and intra-category robustness, we introduce a generative motion augmentation strategy harnessing a diffusion-based foundation model for creating diverse and realistic training samples. Notably, to the best of our knowledge, our work is the first to introduce such a strategy specifically tailored to enhance contrastive learning for action AD. Extensive experiments on the HumanAct12 dataset demonstrate the state-of-the-art effectiveness of our approach under both seen and unseen category settings, regarding training efficiency and model scalability for few-shot HAAD.
LS-GAN: Human Motion Synthesis with Latent-space GANs
Dec 30, 2024



Human motion synthesis conditioned on textual input has gained significant attention in recent years due to its potential applications in various domains such as gaming, film production, and virtual reality. Conditioned Motion synthesis takes a text input and outputs a 3D motion corresponding to the text. While previous works have explored motion synthesis using raw motion data and latent space representations with diffusion models, these approaches often suffer from high training and inference times. In this paper, we introduce a novel framework that utilizes Generative Adversarial Networks (GANs) in the latent space to enable faster training and inference while achieving results comparable to those of the state-of-the-art diffusion methods. We perform experiments on the HumanML3D, HumanAct12 benchmarks and demonstrate that a remarkably simple GAN in the latent space achieves a FID of 0.482 with more than 91% in FLOPs reduction compared to latent diffusion model. Our work opens up new possibilities for efficient and high-quality motion synthesis using latent space GANs.
PoseGPT: Quantization-based 3D Human Motion Generation and Forecasting
Oct 19, 2022

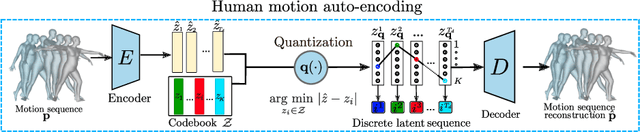
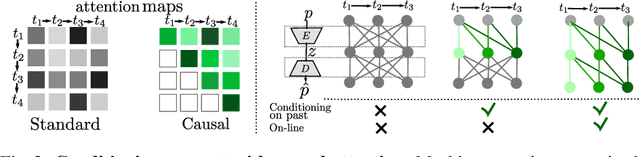
We address the problem of action-conditioned generation of human motion sequences. Existing work falls into two categories: forecast models conditioned on observed past motions, or generative models conditioned on action labels and duration only. In contrast, we generate motion conditioned on observations of arbitrary length, including none. To solve this generalized problem, we propose PoseGPT, an auto-regressive transformer-based approach which internally compresses human motion into quantized latent sequences. An auto-encoder first maps human motion to latent index sequences in a discrete space, and vice-versa. Inspired by the Generative Pretrained Transformer (GPT), we propose to train a GPT-like model for next-index prediction in that space; this allows PoseGPT to output distributions on possible futures, with or without conditioning on past motion. The discrete and compressed nature of the latent space allows the GPT-like model to focus on long-range signal, as it removes low-level redundancy in the input signal. Predicting discrete indices also alleviates the common pitfall of predicting averaged poses, a typical failure case when regressing continuous values, as the average of discrete targets is not a target itself. Our experimental results show that our proposed approach achieves state-of-the-art results on HumanAct12, a standard but small scale dataset, as well as on BABEL, a recent large scale MoCap dataset, and on GRAB, a human-object interactions dataset.
Action-conditioned On-demand Motion Generation
Jul 17, 2022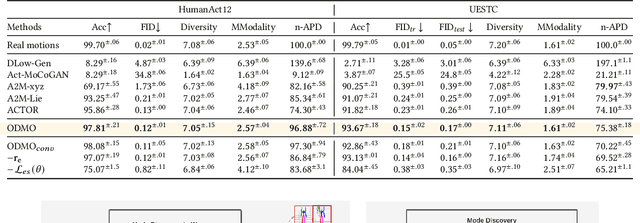
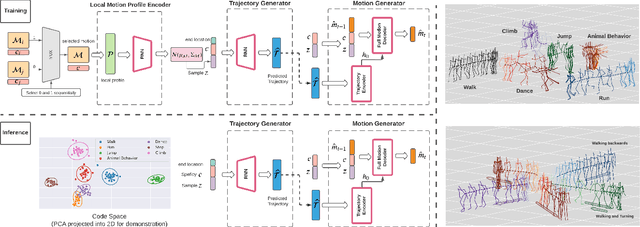
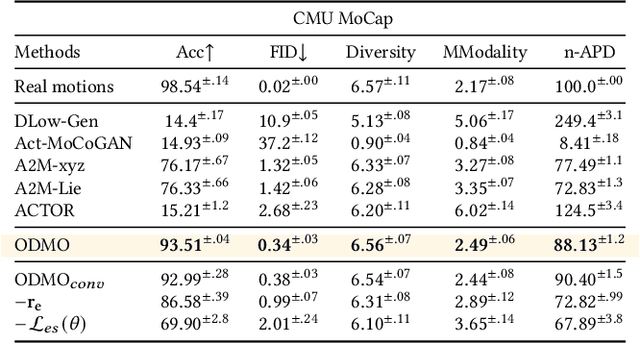
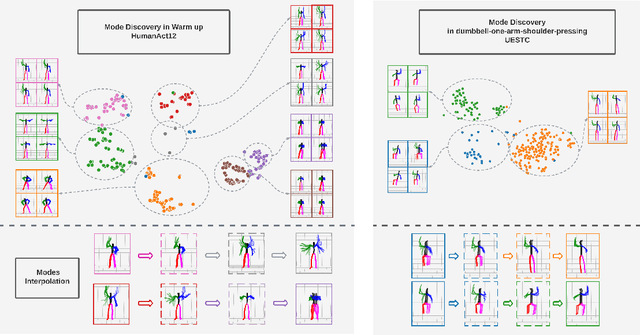
We propose a novel framework, On-Demand MOtion Generation (ODMO), for generating realistic and diverse long-term 3D human motion sequences conditioned only on action types with an additional capability of customization. ODMO shows improvements over SOTA approaches on all traditional motion evaluation metrics when evaluated on three public datasets (HumanAct12, UESTC, and MoCap). Furthermore, we provide both qualitative evaluations and quantitative metrics demonstrating several first-known customization capabilities afforded by our framework, including mode discovery, interpolation, and trajectory customization. These capabilities significantly widen the spectrum of potential applications of such motion generation models. The novel on-demand generative capabilities are enabled by innovations in both the encoder and decoder architectures: (i) Encoder: Utilizing contrastive learning in low-dimensional latent space to create a hierarchical embedding of motion sequences, where not only the codes of different action types form different groups, but within an action type, codes of similar inherent patterns (motion styles) cluster together, making them readily discoverable; (ii) Decoder: Using a hierarchical decoding strategy where the motion trajectory is reconstructed first and then used to reconstruct the whole motion sequence. Such an architecture enables effective trajectory control. Our code is released on the Github page: https://github.com/roychowdhuryresearch/ODMO
Implicit Neural Representations for Variable Length Human Motion Generation
Mar 25, 2022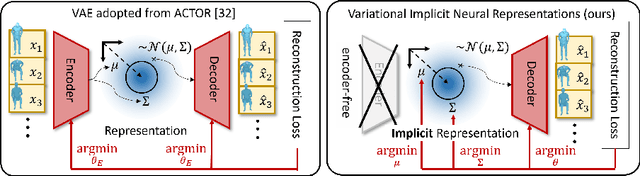
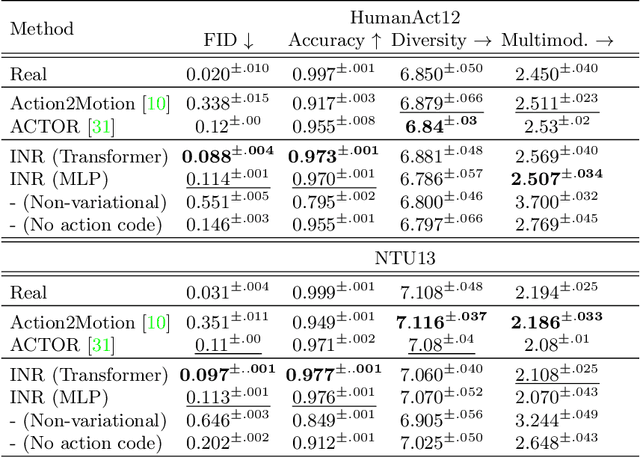
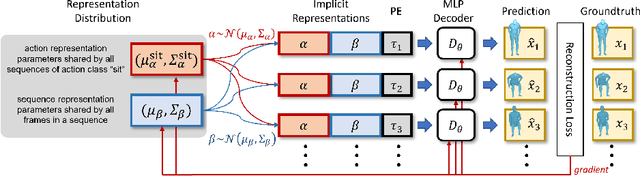

We propose an action-conditional human motion generation method using variational implicit neural representations (INR). The variational formalism enables action-conditional distributions of INRs, from which one can easily sample representations to generate novel human motion sequences. Our method offers variable-length sequence generation by construction because a part of INR is optimized for a whole sequence of arbitrary length with temporal embeddings. In contrast, previous works reported difficulties with modeling variable-length sequences. We confirm that our method with a Transformer decoder outperforms all relevant methods on HumanAct12, NTU-RGBD, and UESTC datasets in terms of realism and diversity of generated motions. Surprisingly, even our method with an MLP decoder consistently outperforms the state-of-the-art Transformer-based auto-encoder. In particular, we show that variable-length motions generated by our method are better than fixed-length motions generated by the state-of-the-art method in terms of realism and diversity.
Action-Conditioned 3D Human Motion Synthesis with Transformer VAE
Apr 12, 2021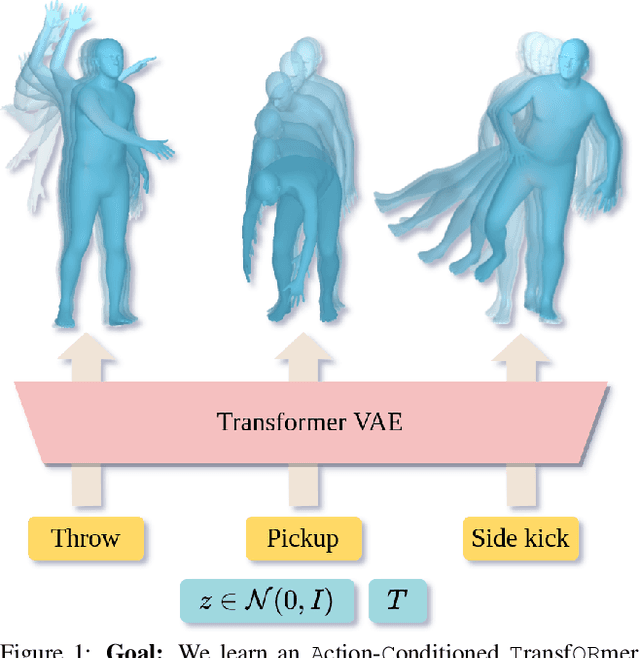

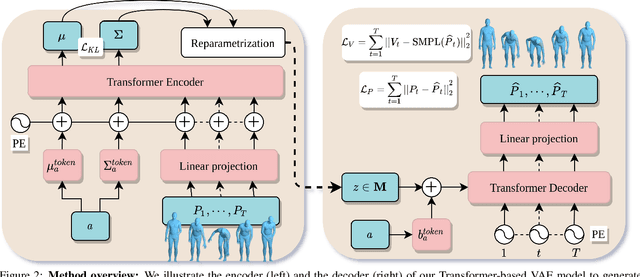
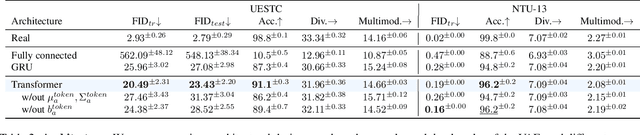
We tackle the problem of action-conditioned generation of realistic and diverse human motion sequences. In contrast to methods that complete, or extend, motion sequences, this task does not require an initial pose or sequence. Here we learn an action-aware latent representation for human motions by training a generative variational autoencoder (VAE). By sampling from this latent space and querying a certain duration through a series of positional encodings, we synthesize variable-length motion sequences conditioned on a categorical action. Specifically, we design a Transformer-based architecture, ACTOR, for encoding and decoding a sequence of parametric SMPL human body models estimated from action recognition datasets. We evaluate our approach on the NTU RGB+D, HumanAct12 and UESTC datasets and show improvements over the state of the art. Furthermore, we present two use cases: improving action recognition through adding our synthesized data to training, and motion denoising. Our code and models will be made available.
Action2Motion: Conditioned Generation of 3D Human Motions
Jul 30, 2020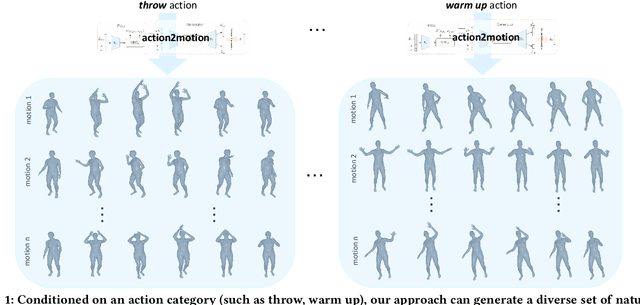
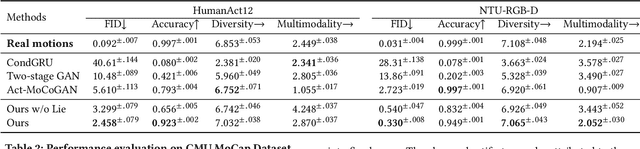
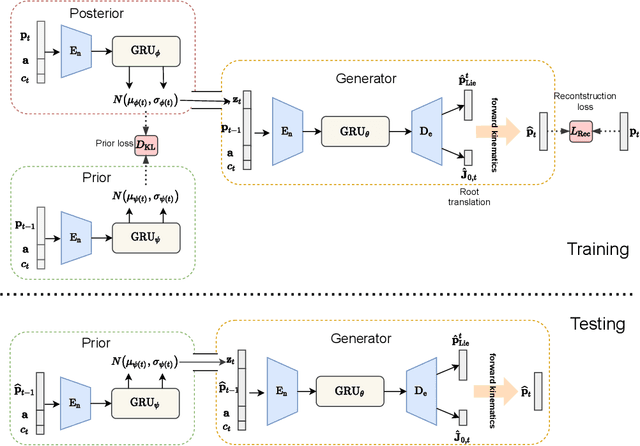
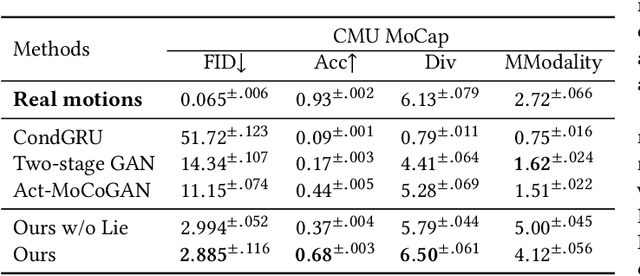
Action recognition is a relatively established task, where givenan input sequence of human motion, the goal is to predict its ac-tion category. This paper, on the other hand, considers a relativelynew problem, which could be thought of as an inverse of actionrecognition: given a prescribed action type, we aim to generateplausible human motion sequences in 3D. Importantly, the set ofgenerated motions are expected to maintain itsdiversityto be ableto explore the entire action-conditioned motion space; meanwhile,each sampled sequence faithfully resembles anaturalhuman bodyarticulation dynamics. Motivated by these objectives, we followthe physics law of human kinematics by adopting the Lie Algebratheory to represent thenaturalhuman motions; we also propose atemporal Variational Auto-Encoder (VAE) that encourages adiversesampling of the motion space. A new 3D human motion dataset, HumanAct12, is also constructed. Empirical experiments overthree distinct human motion datasets (including ours) demonstratethe effectiveness of our approach.