 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Face Recognition
Papers and Code
Reasoning under Ambiguity: Uncertainty-Aware Multilingual Emotion Classification under Partial Supervision
Feb 05, 2026Contemporary knowledge-based systems increasingly rely on multilingual emotion identification to support intelligent decision-making, yet they face major challenges due to emotional ambiguity and incomplete supervision. Emotion recognition from text is inherently uncertain because multiple emotional states often co-occur and emotion annotations are frequently missing or heterogeneous. Most existing multi-label emotion classification methods assume fully observed labels and rely on deterministic learning objectives, which can lead to biased learning and unreliable predictions under partial supervision. This paper introduces Reasoning under Ambiguity, an uncertainty-aware framework for multilingual multi-label emotion classification that explicitly aligns learning with annotation uncertainty. The proposed approach uses a shared multilingual encoder with language-specific optimization and an entropy-based ambiguity weighting mechanism that down-weights highly ambiguous training instances rather than treating missing labels as negative evidence. A mask-aware objective with positive-unlabeled regularization is further incorporated to enable robust learning under partial supervision. Experiments on English, Spanish, and Arabic emotion classification benchmarks demonstrate consistent improvements over strong baselines across multiple evaluation metrics, along with improved training stability, robustness to annotation sparsity, and enhanced interpretability.
SeNeDiF-OOD: Semantic Nested Dichotomy Fusion for Out-of-Distribution Detection Methodology in Open-World Classification. A Case Study on Monument Style Classification
Jan 27, 2026Out-of-distribution (OOD) detection is a fundamental requirement for the reliable deployment of artificial intelligence applications in open-world environments. However, addressing the heterogeneous nature of OOD data, ranging from low-level corruption to semantic shifts, remains a complex challenge that single-stage detectors often fail to resolve. To address this issue, we propose SeNeDiF-OOD, a novel methodology based on Semantic Nested Dichotomy Fusion. This framework decomposes the detection task into a hierarchical structure of binary fusion nodes, where each layer is designed to integrate decision boundaries aligned with specific levels of semantic abstraction. To validate the proposed framework, we present a comprehensive case study using MonuMAI, a real-world architectural style recognition system exposed to an open environment. This application faces a diverse range of inputs, including non-monument images, unknown architectural styles, and adversarial attacks, making it an ideal testbed for our proposal. Through extensive experimental evaluation in this domain, results demonstrate that our hierarchical fusion methodology significantly outperforms traditional baselines, effectively filtering these diverse OOD categories while preserving in-distribution performance.
STARS: Shared-specific Translation and Alignment for missing-modality Remote Sensing Semantic Segmentation
Jan 24, 2026Multimodal remote sensing technology significantly enhances the understanding of surface semantics by integrating heterogeneous data such as optical images, Synthetic Aperture Radar (SAR), and Digital Surface Models (DSM). However, in practical applications, the missing of modality data (e.g., optical or DSM) is a common and severe challenge, which leads to performance decline in traditional multimodal fusion models. Existing methods for addressing missing modalities still face limitations, including feature collapse and overly generalized recovered features. To address these issues, we propose \textbf{STARS} (\textbf{S}hared-specific \textbf{T}ranslation and \textbf{A}lignment for missing-modality \textbf{R}emote \textbf{S}ensing), a robust semantic segmentation framework for incomplete multimodal inputs. STARS is built on two key designs. First, we introduce an asymmetric alignment mechanism with bidirectional translation and stop-gradient, which effectively prevents feature collapse and reduces sensitivity to hyperparameters. Second, we propose a Pixel-level Semantic sampling Alignment (PSA) strategy that combines class-balanced pixel sampling with cross-modality semantic alignment loss, to mitigate alignment failures caused by severe class imbalance and improve minority-class recognition.
MobiDiary: Autoregressive Action Captioning with Wearable Devices and Wireless Signals
Jan 13, 2026Human Activity Recognition (HAR) in smart homes is critical for health monitoring and assistive living. While vision-based systems are common, they face privacy concerns and environmental limitations (e.g., occlusion). In this work, we present MobiDiary, a framework that generates natural language descriptions of daily activities directly from heterogeneous physical signals (specifically IMU and Wi-Fi). Unlike conventional approaches that restrict outputs to pre-defined labels, MobiDiary produces expressive, human-readable summaries. To bridge the semantic gap between continuous, noisy physical signals and discrete linguistic descriptions, we propose a unified sensor encoder. Instead of relying on modality-specific engineering, we exploit the shared inductive biases of motion-induced signals--where both inertial and wireless data reflect underlying kinematic dynamics. Specifically, our encoder utilizes a patch-based mechanism to capture local temporal correlations and integrates heterogeneous placement embedding to unify spatial contexts across different sensors. These unified signal tokens are then fed into a Transformer-based decoder, which employs an autoregressive mechanism to generate coherent action descriptions word-by-word. We comprehensively evaluate our approach on multiple public benchmarks (XRF V2, UWash, and WiFiTAD). Experimental results demonstrate that MobiDiary effectively generalizes across modalities, achieving state-of-the-art performance on captioning metrics (e.g., BLEU@4, CIDEr, RMC) and outperforming specialized baselines in continuous action understanding.
A Method for Constructing a Digital Transformation Driving Mechanism Based on Semantic Understanding of Large Models
Jan 08, 2026In the process of digital transformation, enterprises are faced with problems such as insufficient semantic understanding of unstructured data and lack of intelligent decision-making basis in driving mechanisms. This study proposes a method that combines a large language model (LLM) and a knowledge graph. First, a fine-tuned BERT (Bidirectional Encoder Representations from Transformers) model is used to perform entity recognition and relationship extraction on multi-source heterogeneous texts, and GPT-4 is used to generate semantically enhanced vector representations; secondly, a two-layer graph neural network (GNN) architecture is designed to fuse the semantic vectors output by LLM with business metadata to construct a dynamic and scalable enterprise knowledge graph; then reinforcement learning is introduced to optimize decision path generation, and the reward function is used to drive the mechanism iteration. In the case of the manufacturing industry, this mechanism reduced the response time for equipment failure scenarios from 7.8 hours to 3.7 hours, the F1 value reached 94.3%, and the compensation for decision errors in the annual digital transformation cost decreased by 45.3%. This method significantly enhances the intelligence level and execution efficiency of the digital transformation driving mechanism by integrating large model semantic understanding with structured knowledge.
Multi-Attribute guided Thermal Face Image Translation based on Latent Diffusion Model
Dec 24, 2025Modern surveillance systems increasingly rely on multi-wavelength sensors and deep neural networks to recognize faces in infrared images captured at night. However, most facial recognition models are trained on visible light datasets, leading to substantial performance degradation on infrared inputs due to significant domain shifts. Early feature-based methods for infrared face recognition proved ineffective, prompting researchers to adopt generative approaches that convert infrared images into visible light images for improved recognition. This paradigm, known as Heterogeneous Face Recognition (HFR), faces challenges such as model and modality discrepancies, leading to distortion and feature loss in generated images. To address these limitations, this paper introduces a novel latent diffusion-based model designed to generate high-quality visible face images from thermal inputs while preserving critical identity features. A multi-attribute classifier is incorporated to extract key facial attributes from visible images, mitigating feature loss during infrared-to-visible image restoration. Additionally, we propose the Self-attn Mamba module, which enhances global modeling of cross-modal features and significantly improves inference speed. Experimental results on two benchmark datasets demonstrate the superiority of our approach, achieving state-of-the-art performance in both image quality and identity preservation.
UniMPR: A Unified Framework for Multimodal Place Recognition with Heterogeneous Sensor Configurations
Dec 23, 2025Place recognition is a critical component of autonomous vehicles and robotics, enabling global localization in GPS-denied environments. Recent advances have spurred significant interest in multimodal place recognition (MPR), which leverages complementary strengths of multiple modalities. Despite its potential, most existing MPR methods still face three key challenges: (1) dynamically adapting to various modality inputs within a unified framework, (2) maintaining robustness with missing or degraded modalities, and (3) generalizing across diverse sensor configurations and setups. In this paper, we propose UniMPR, a unified framework for multimodal place recognition. Using only one trained model, it can seamlessly adapt to any combination of common perceptual modalities (e.g., camera, LiDAR, radar). To tackle the data heterogeneity, we unify all inputs within a polar BEV feature space. Subsequently, the polar BEVs are fed into a multi-branch network to exploit discriminative intra-model and inter-modal features from any modality combinations. To fully exploit the network's generalization capability and robustness, we construct a large-scale training set from multiple datasets and introduce an adaptive label assignment strategy for extensive pre-training. Experiments on seven datasets demonstrate that UniMPR achieves state-of-the-art performance under varying sensor configurations, modality combinations, and environmental conditions. Our code will be released at https://github.com/QiZS-BIT/UniMPR.
From Visual Perception to Deep Empathy: An Automated Assessment Framework for House-Tree-Person Drawings Using Multimodal LLMs and Multi-Agent Collaboration
Dec 23, 2025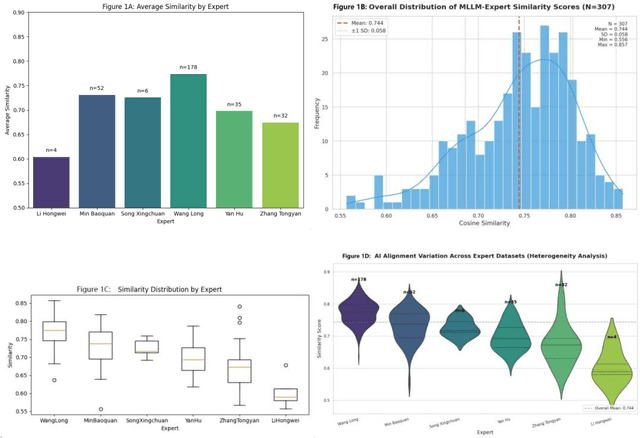
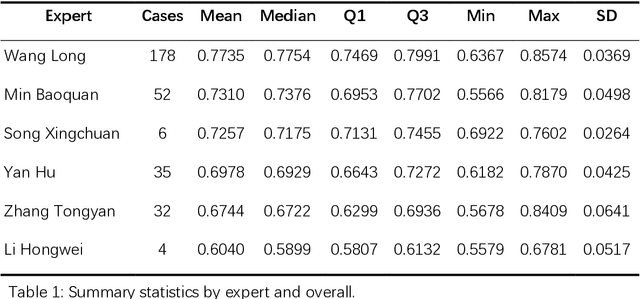
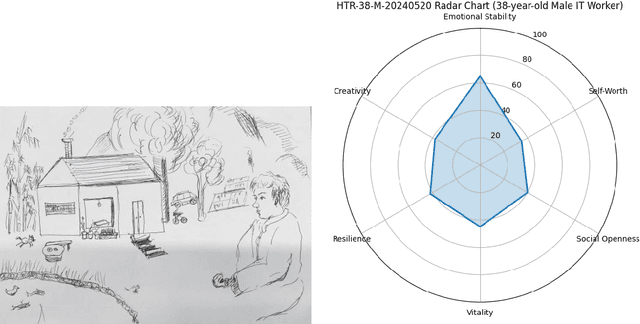
Background: The House-Tree-Person (HTP) drawing test, introduced by John Buck in 1948, remains a widely used projective technique in clinical psychology. However, it has long faced challenges such as heterogeneous scoring standards, reliance on examiners subjective experience, and a lack of a unified quantitative coding system. Results: Quantitative experiments showed that the mean semantic similarity between Multimodal Large Language Model (MLLM) interpretations and human expert interpretations was approximately 0.75 (standard deviation about 0.05). In structurally oriented expert data sets, this similarity rose to 0.85, indicating expert-level baseline comprehension. Qualitative analyses demonstrated that the multi-agent system, by integrating social-psychological perspectives and destigmatizing narratives, effectively corrected visual hallucinations and produced psychological reports with high ecological validity and internal coherence. Conclusions: The findings confirm the potential of multimodal large models as standardized tools for projective assessment. The proposed multi-agent framework, by dividing roles, decouples feature recognition from psychological inference and offers a new paradigm for digital mental-health services. Keywords: House-Tree-Person test; multimodal large language model; multi-agent collaboration; cosine similarity; computational psychology; artificial intelligence
MCN-CL: Multimodal Cross-Attention Network and Contrastive Learning for Multimodal Emotion Recognition
Nov 14, 2025



Multimodal emotion recognition plays a key role in many domains, including mental health monitoring, educational interaction, and human-computer interaction. However, existing methods often face three major challenges: unbalanced category distribution, the complexity of dynamic facial action unit time modeling, and the difficulty of feature fusion due to modal heterogeneity. With the explosive growth of multimodal data in social media scenarios, the need for building an efficient cross-modal fusion framework for emotion recognition is becoming increasingly urgent. To this end, this paper proposes Multimodal Cross-Attention Network and Contrastive Learning (MCN-CL) for multimodal emotion recognition. It uses a triple query mechanism and hard negative mining strategy to remove feature redundancy while preserving important emotional cues, effectively addressing the issues of modal heterogeneity and category imbalance. Experiment results on the IEMOCAP and MELD datasets show that our proposed method outperforms state-of-the-art approaches, with Weighted F1 scores improving by 3.42% and 5.73%, respectively.
A Novel Deep Hybrid Framework with Ensemble-Based Feature Optimization for Robust Real-Time Human Activity Recognition
Aug 26, 2025



Human Activity Recognition (HAR) plays a pivotal role in various applications, including smart surveillance, healthcare, assistive technologies, sports analytics, etc. However, HAR systems still face critical challenges, including high computational costs, redundant features, and limited scalability in real-time scenarios. An optimized hybrid deep learning framework is introduced that integrates a customized InceptionV3, an LSTM architecture, and a novel ensemble-based feature selection strategy. The proposed framework first extracts spatial descriptors using the customized InceptionV3 model, which captures multilevel contextual patterns, region homogeneity, and fine-grained localization cues. The temporal dependencies across frames are then modeled using LSTMs to effectively encode motion dynamics. Finally, an ensemble-based genetic algorithm with Adaptive Dynamic Fitness Sharing and Attention (ADFSA) is employed to select a compact and optimized feature set by dynamically balancing objectives such as accuracy, redundancy, uniqueness, and complexity reduction. Consequently, the selected feature subsets, which are both diverse and discriminative, enable various lightweight machine learning classifiers to achieve accurate and robust HAR in heterogeneous environments. Experimental results on the robust UCF-YouTube dataset, which presents challenges such as occlusion, cluttered backgrounds, motion dynamics, and poor illumination, demonstrate good performance. The proposed approach achieves 99.65% recognition accuracy, reduces features to as few as 7, and enhances inference time. The lightweight and scalable nature of the HAR system supports real-time deployment on edge devices such as Raspberry Pi, enabling practical applications in intelligent, resource-aware environments, including public safety, assistive technology, and autonomous monitoring systems.