 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSURGIN: SURrogate-guided Generative INversion for subsurface multiphase flow with quantified uncertainty
Sep 16, 2025We present a direct inverse modeling method named SURGIN, a SURrogate-guided Generative INversion framework tailed for subsurface multiphase flow data assimilation. Unlike existing inversion methods that require adaptation for each new observational configuration, SURGIN features a zero-shot conditional generation capability, enabling real-time assimilation of unseen monitoring data without task-specific retraining. Specifically, SURGIN synergistically integrates a U-Net enhanced Fourier Neural Operator (U-FNO) surrogate with a score-based generative model (SGM), framing the conditional generation as a surrogate prediction-guidance process in a Bayesian perspective. Instead of directly learning the conditional generation of geological parameters, an unconditional SGM is first pretrained in a self-supervised manner to capture the geological prior, after which posterior sampling is performed by leveraging a differentiable U-FNO surrogate to enable efficient forward evaluations conditioned on unseen observations. Extensive numerical experiments demonstrate SURGIN's capability to decently infer heterogeneous geological fields and predict spatiotemporal flow dynamics with quantified uncertainty across diverse measurement settings. By unifying generative learning with surrogate-guided Bayesian inference, SURGIN establishes a new paradigm for inverse modeling and uncertainty quantification in parametric functional spaces.
Accuracy Assessment of OpenAlex and Clarivate Scholar ID with an LLM-Assisted Benchmark
Feb 17, 2025In quantitative SciSci (science of science) studies, accurately identifying individual scholars is paramount for scientific data analysis. However, the variability in how names are represented-due to commonality, abbreviations, and different spelling conventions-complicates this task. While identifier systems like ORCID are being developed, many scholars remain unregistered, and numerous publications are not included. Scholarly databases such as Clarivate and OpenAlex have introduced their own ID systems as preliminary name disambiguation solutions. This study evaluates the effectiveness of these systems across different groups to determine their suitability for various application scenarios. We sampled authors from the top quartile (Q1) of Web of Science (WOS) journals based on country, discipline, and number of corresponding author papers. For each group, we selected 100 scholars and meticulously annotated all their papers using a Search-enhanced Large Language Model method. Using these annotations, we identified the corresponding IDs in OpenAlex and Clarivate, extracted all associated papers, filtered for Q1 WOS journals, and calculated precision and recall by comparing against the annotated dataset.
Scholar Name Disambiguation with Search-enhanced LLM Across Language
Nov 26, 2024The task of scholar name disambiguation is crucial in various real-world scenarios, including bibliometric-based candidate evaluation for awards, application material anti-fraud measures, and more. Despite significant advancements, current methods face limitations due to the complexity of heterogeneous data, often necessitating extensive human intervention. This paper proposes a novel approach by leveraging search-enhanced language models across multiple languages to improve name disambiguation. By utilizing the powerful query rewriting, intent recognition, and data indexing capabilities of search engines, our method can gather richer information for distinguishing between entities and extracting profiles, resulting in a more comprehensive data dimension. Given the strong cross-language capabilities of large language models(LLMs), optimizing enhanced retrieval methods with this technology offers substantial potential for high-efficiency information retrieval and utilization. Our experiments demonstrate that incorporating local languages significantly enhances disambiguation performance, particularly for scholars from diverse geographic regions. This multi-lingual, search-enhanced methodology offers a promising direction for more efficient and accurate active scholar name disambiguation.
Efficient Large-Scale Fleet Management via Multi-Agent Deep Reinforcement Learning
Nov 01, 2018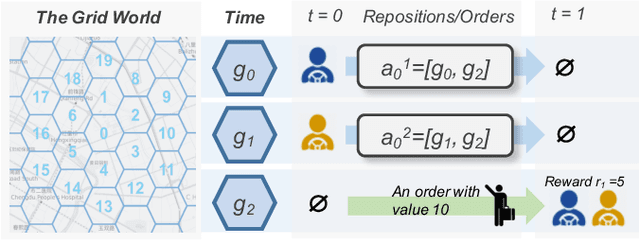
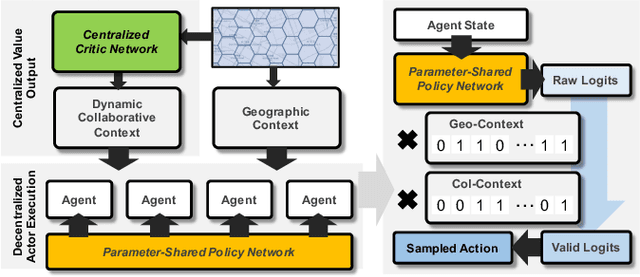
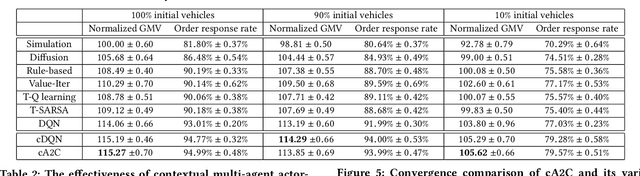
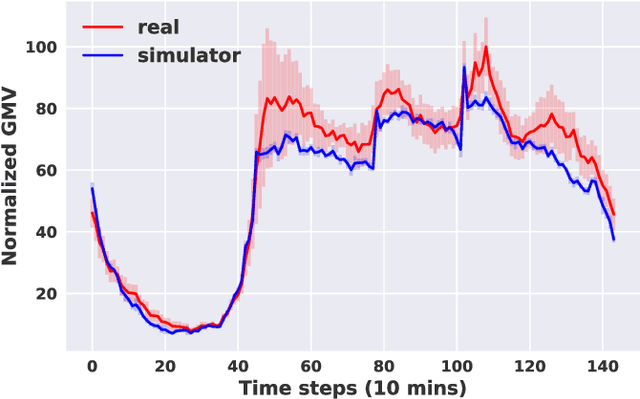
Large-scale online ride-sharing platforms have substantially transformed our lives by reallocating transportation resources to alleviate traffic congestion and promote transportation efficiency. An efficient fleet management strategy not only can significantly improve the utilization of transportation resources but also increase the revenue and customer satisfaction. It is a challenging task to design an effective fleet management strategy that can adapt to an environment involving complex dynamics between demand and supply. Existing studies usually work on a simplified problem setting that can hardly capture the complicated stochastic demand-supply variations in high-dimensional space. In this paper we propose to tackle the large-scale fleet management problem using reinforcement learning, and propose a contextual multi-agent reinforcement learning framework including two concrete algorithms, namely contextual deep Q-learning and contextual multi-agent actor-critic, to achieve explicit coordination among a large number of agents adaptive to different contexts. We show significant improvements of the proposed framework over state-of-the-art approaches through extensive empirical studies.
Monitoring Chinese Population Migration in Consecutive Weekly Basis from Intra-city scale to Inter-province scale by Didi's Bigdata
Apr 07, 2016

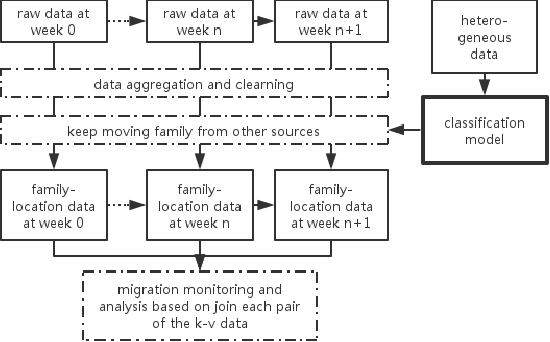
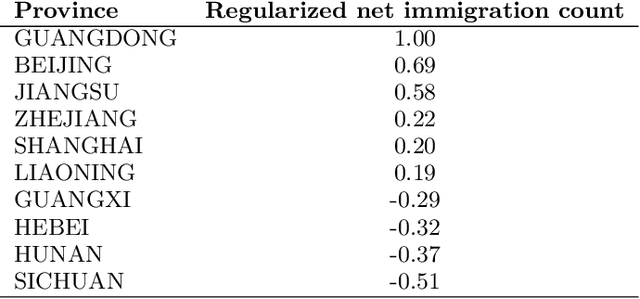
Population migration is valuable information which leads to proper decision in urban-planning strategy, massive investment, and many other fields. For instance, inter-city migration is a posterior evidence to see if the government's constrain of population works, and inter-community immigration might be a prior evidence of real estate price hike. With timely data, it is also impossible to compare which city is more favorable for the people, suppose the cities release different new regulations, we could also compare the customers of different real estate development groups, where they come from, where they probably will go. Unfortunately these data was not available. In this paper, leveraging the data generated by positioning team in Didi, we propose a novel approach that timely monitoring population migration from community scale to provincial scale. Migration can be detected as soon as in a week. It could be faster, the setting of a week is for statistical purpose. A monitoring system is developed, then applied nation wide in China, some observations derived from the system will be presented in this paper. This new method of migration perception is origin from the insight that nowadays people mostly moving with their personal Access Point (AP), also known as WiFi hotspot. Assume that the ratio of AP moving to the migration of population is constant, analysis of comparative population migration would be feasible. More exact quantitative research would also be done with few sample research and model regression. The procedures of processing data includes many steps: eliminating the impact of pseudo-migration AP, for instance pocket WiFi, and second-hand traded router; distinguishing moving of population with moving of companies; identifying shifting of AP by the finger print clusters, etc..