 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgogesture
Papers and Code
ACTION-Net: Multipath Excitation for Action Recognition
Mar 11, 2021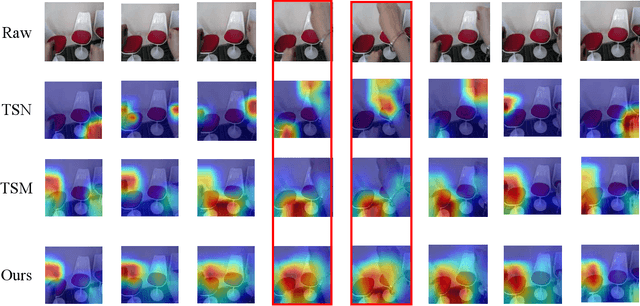
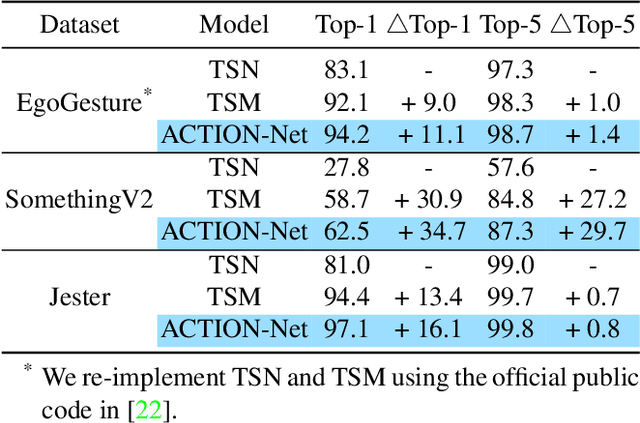
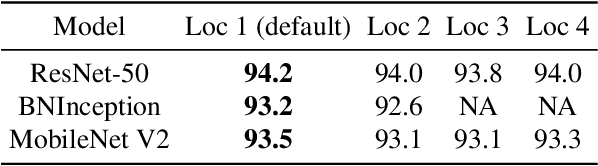
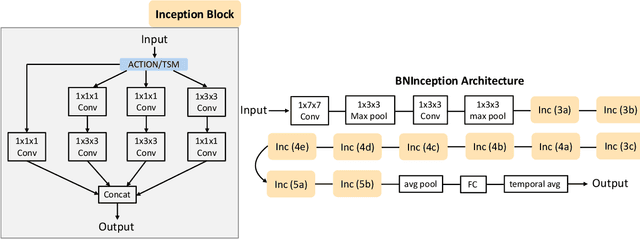
Spatial-temporal, channel-wise, and motion patterns are three complementary and crucial types of information for video action recognition. Conventional 2D CNNs are computationally cheap but cannot catch temporal relationships; 3D CNNs can achieve good performance but are computationally intensive. In this work, we tackle this dilemma by designing a generic and effective module that can be embedded into 2D CNNs. To this end, we propose a spAtio-temporal, Channel and moTion excitatION (ACTION) module consisting of three paths: Spatio-Temporal Excitation (STE) path, Channel Excitation (CE) path, and Motion Excitation (ME) path. The STE path employs one channel 3D convolution to characterize spatio-temporal representation. The CE path adaptively recalibrates channel-wise feature responses by explicitly modeling interdependencies between channels in terms of the temporal aspect. The ME path calculates feature-level temporal differences, which is then utilized to excite motion-sensitive channels. We equip 2D CNNs with the proposed ACTION module to form a simple yet effective ACTION-Net with very limited extra computational cost. ACTION-Net is demonstrated by consistently outperforming 2D CNN counterparts on three backbones (i.e., ResNet-50, MobileNet V2 and BNInception) employing three datasets (i.e., Something-Something V2, Jester, and EgoGesture). Codes are available at \url{https://github.com/V-Sense/ACTION-Net}.
Multi-modal Fusion for Single-Stage Continuous Gesture Recognition
Nov 10, 2020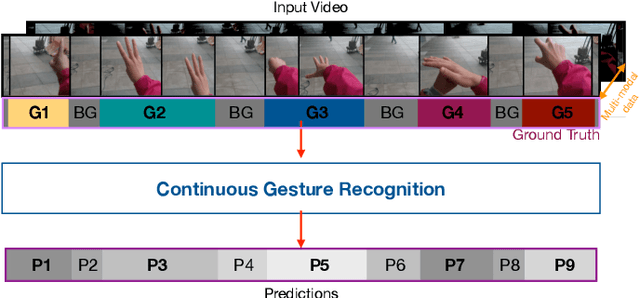
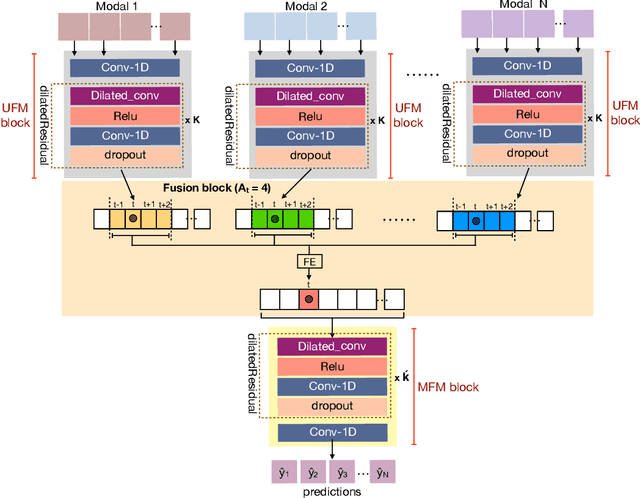
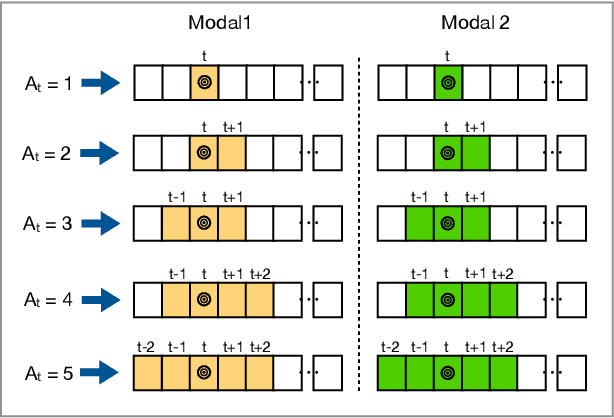
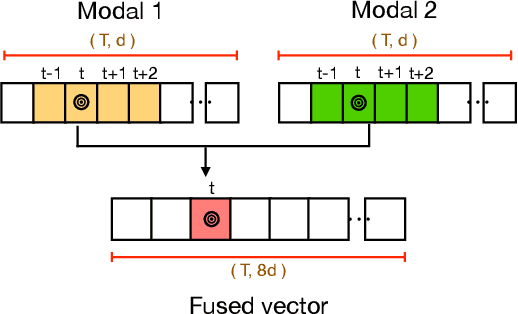
Gesture recognition is a much studied research area which has myriad real-world applications including robotics and human-machine interaction. Current gesture recognition methods have heavily focused on isolated gestures, and existing continuous gesture recognition methods are limited by a two-stage approach where independent models are required for detection and classification, with the performance of the latter being constrained by detection performance. In contrast, we introduce a single-stage continuous gesture recognition model, that can detect and classify multiple gestures in a single video via a single model. This approach learns the natural transitions between gestures and non-gestures without the need for a pre-processing segmentation stage to detect individual gestures. To enable this, we introduce a multi-modal fusion mechanism to support the integration of important information that flows from multi-modal inputs, and is scalable to any number of modes. Additionally, we propose Unimodal Feature Mapping (UFM) and Multi-modal Feature Mapping (MFM) models to map uni-modal features and the fused multi-modal features respectively. To further enhance the performance we propose a mid-point based loss function that encourages smooth alignment between the ground truth and the prediction. We demonstrate the utility of our proposed framework which can handle variable-length input videos, and outperforms the state-of-the-art on two challenging datasets, EgoGesture, and IPN hand. Furthermore, ablative experiments show the importance of different components of the proposed framework.
Searching Multi-Rate and Multi-Modal Temporal Enhanced Networks for Gesture Recognition
Aug 21, 2020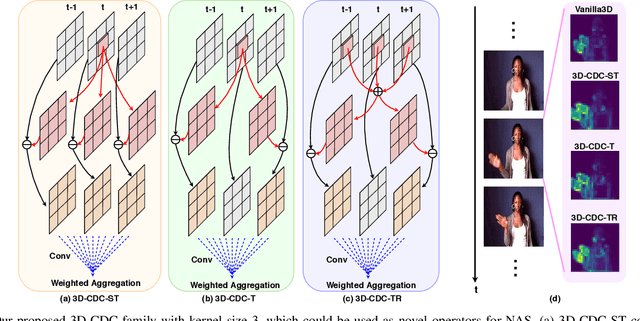
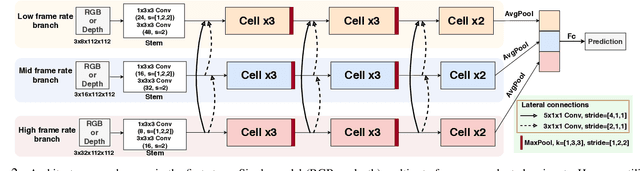
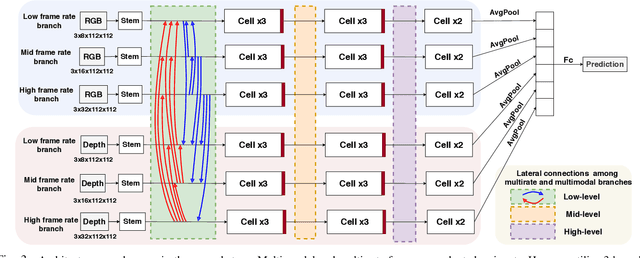
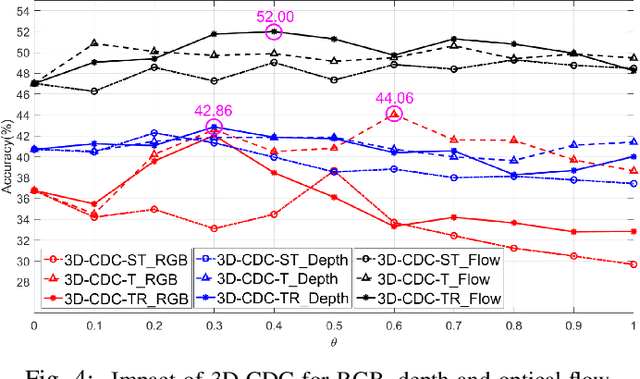
Gesture recognition has attracted considerable attention owing to its great potential in applications. Although the great progress has been made recently in multi-modal learning methods, existing methods still lack effective integration to fully explore synergies among spatio-temporal modalities effectively for gesture recognition. The problems are partially due to the fact that the existing manually designed network architectures have low efficiency in the joint learning of multi-modalities. In this paper, we propose the first neural architecture search (NAS)-based method for RGB-D gesture recognition. The proposed method includes two key components: 1) enhanced temporal representation via the proposed 3D Central Difference Convolution (3D-CDC) family, which is able to capture rich temporal context via aggregating temporal difference information; and 2) optimized backbones for multi-sampling-rate branches and lateral connections among varied modalities. The resultant multi-modal multi-rate network provides a new perspective to understand the relationship between RGB and depth modalities and their temporal dynamics. Comprehensive experiments are performed on three benchmark datasets (IsoGD, NvGesture, and EgoGesture), demonstrating the state-of-the-art performance in both single- and multi-modality settings.The code is available at https://github.com/ZitongYu/3DCDC-NAS
CatNet: Class Incremental 3D ConvNets for Lifelong Egocentric Gesture Recognition
Apr 20, 2020
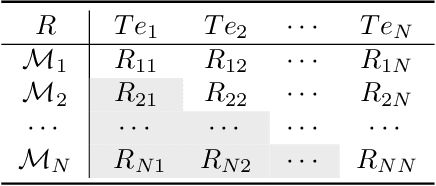

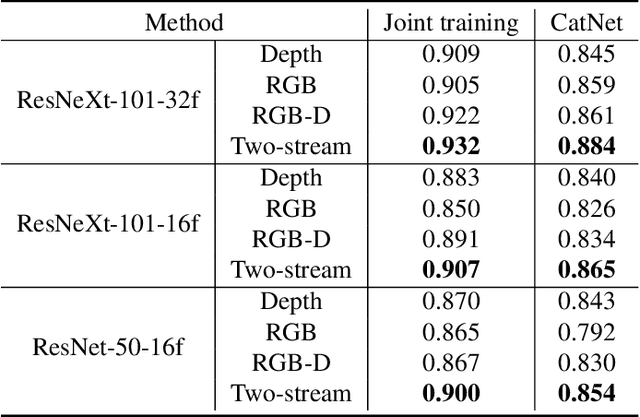
Egocentric gestures are the most natural form of communication for humans to interact with wearable devices such as VR/AR helmets and glasses. A major issue in such scenarios for real-world applications is that may easily become necessary to add new gestures to the system e.g., a proper VR system should allow users to customize gestures incrementally. Traditional deep learning methods require storing all previous class samples in the system and training the model again from scratch by incorporating previous samples and new samples, which costs humongous memory and significantly increases computation over time. In this work, we demonstrate a lifelong 3D convolutional framework -- c(C)la(a)ss increment(t)al net(Net)work (CatNet), which considers temporal information in videos and enables lifelong learning for egocentric gesture video recognition by learning the feature representation of an exemplar set selected from previous class samples. Importantly, we propose a two-stream CatNet, which deploys RGB and depth modalities to train two separate networks. We evaluate CatNets on a publicly available dataset -- EgoGesture dataset, and show that CatNets can learn many classes incrementally over a long period of time. Results also demonstrate that the two-stream architecture achieves the best performance on both joint training and class incremental training compared to 3 other one-stream architectures. The codes and pre-trained models used in this work are provided at https://github.com/villawang/CatNet.
Simultaneous Segmentation and Recognition: Towards more accurate Ego Gesture Recognition
Sep 18, 2019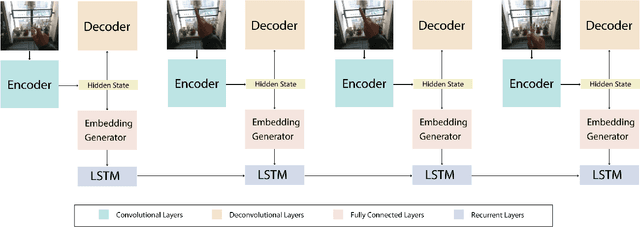
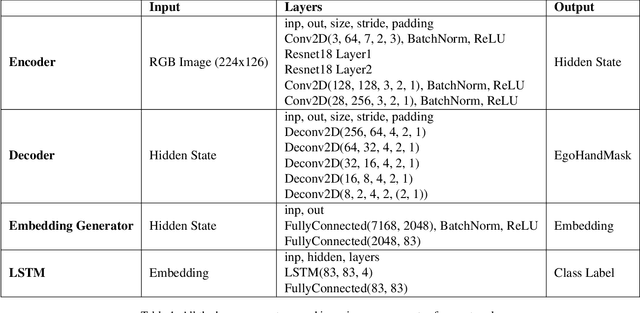
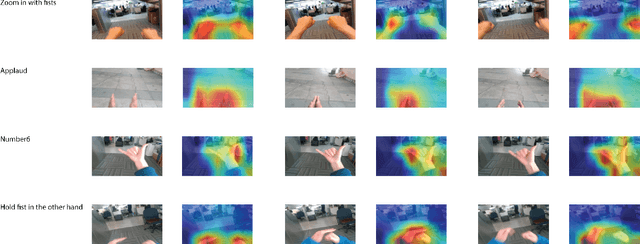

Ego hand gestures can be used as an interface in AR and VR environments. While the context of an image is important for tasks like scene understanding, object recognition, image caption generation and activity recognition, it plays a minimal role in ego hand gesture recognition. An ego hand gesture used for AR and VR environments conveys the same information regardless of the background. With this idea in mind, we present our work on ego hand gesture recognition that produces embeddings from RBG images with ego hands, which are simultaneously used for ego hand segmentation and ego gesture recognition. To this extent, we achieved better recognition accuracy (96.9%) compared to the state of the art (92.2%) on the biggest ego hand gesture dataset available publicly. We present a gesture recognition deep neural network which recognises ego hand gestures from videos (videos containing a single gesture) by generating and recognising embeddings of ego hands from image sequences of varying length. We introduce the concept of simultaneous segmentation and recognition applied to ego hand gestures, present the network architecture, the training procedure and the results compared to the state of the art on the EgoGesture dataset
Real-time Hand Gesture Detection and Classification Using Convolutional Neural Networks
Feb 05, 2019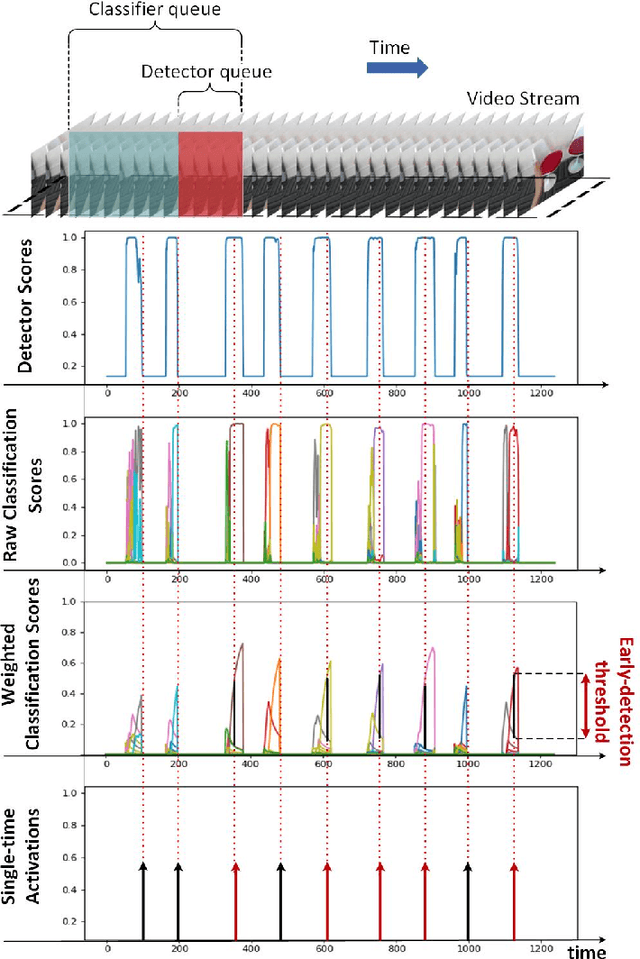
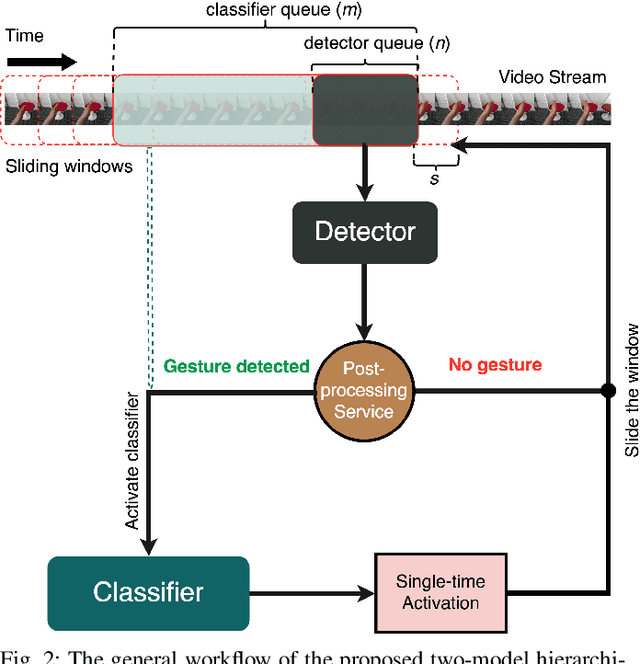
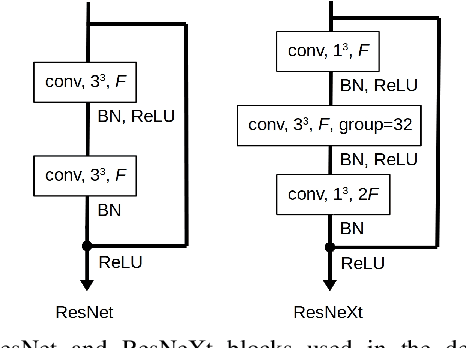
Real-time recognition of dynamic hand gestures from video streams is a challenging task since (i) there is no indication when a gesture starts and ends in the video, (ii) performed gestures should only be recognized once, and (iii) the entire architecture should be designed considering the memory and power budget. In this work, we address these challenges by proposing a hierarchical structure enabling offline-working convolutional neural network (CNN) architectures to operate online efficiently by using sliding window approach. The proposed architecture consists of two models: (1) A detector which is a lightweight CNN architecture to detect gestures and (2) a classifier which is a deep CNN to classify the detected gestures. In order to evaluate the single-time activations of the detected gestures, we propose to use Levenshtein distance as an evaluation metric since it can measure misclassifications, multiple detections, and missing detections at the same time. We evaluate our architecture on two publicly available datasets - EgoGesture and NVIDIA Dynamic Hand Gesture Datasets - which require temporal detection and classification of the performed hand gestures. ResNeXt-101 model, which is used as a classifier, achieves the state-of-the-art offline classification accuracy of 94.04% and 83.82% for depth modality on EgoGesture and NVIDIA benchmarks, respectively. In real-time detection and classification, we obtain considerable early detections while achieving performances close to offline operation. The codes and pretrained models used in this work are publicly available.