 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrows Pairs
Papers and Code
Multiple-Debias: A Full-process Debiasing Method for Multilingual Pre-trained Language Models
Apr 03, 2026Multilingual Pre-trained Language Models (MPLMs) have become essential tools for natural language processing. However, they often exhibit biases related to sensitive attributes such as gender, race, and religion. In this paper, we introduce a comprehensive multilingual debiasing method named Multiple-Debias to address these issues across multiple languages. By incorporating multilingual counterfactual data augmentation and multilingual Self-Debias across both pre-processing and post-processing stages, alongside parameter-efficient fine-tuning, we significantly reduced biases in MPLMs across three sensitive attributes in four languages. We also extended CrowS-Pairs to German, Spanish, Chinese, and Japanese, validating our full-process multilingual debiasing method for gender, racial, and religious bias. Our experiments show that (i) multilingual debiasing methods surpass monolingual approaches in effectively mitigating biases, and (ii) integrating debiasing information from different languages notably improves the fairness of MPLMs.
Routing Sensitivity Without Controllability: A Diagnostic Study of Fairness in MoE Language Models
Mar 28, 2026Mixture-of-Experts (MoE) language models are universally sensitive to demographic content at the routing level, yet exploiting this sensitivity for fairness control is structurally limited. We introduce Fairness-Aware Routing Equilibrium (FARE), a diagnostic framework designed to probe the limits of routing-level stereotype intervention across diverse MoE architectures. FARE reveals that routing-level preference shifts are either unachievable (Mixtral, Qwen1.5, Qwen3), statistically non-robust (DeepSeekMoE), or accompanied by substantial utility cost (OLMoE, -4.4%p CrowS-Pairs at -6.3%p TQA). Critically, even where log-likelihood preference shifts are robust, they do not transfer to decoded generation: expanded evaluations on both non-null models yield null results across all generation metrics. Group-level expert masking reveals why: bias and core knowledge are deeply entangled within expert groups. These findings indicate that routing sensitivity is necessary but insufficient for stereotype control, and identify specific architectural conditions that can inform the design of more controllable future MoE systems.
Dutch CrowS-Pairs: Adapting a Challenge Dataset for Measuring Social Biases in Language Models for Dutch
Jul 22, 2025



Warning: This paper contains explicit statements of offensive stereotypes which might be upsetting. Language models are prone to exhibiting biases, further amplifying unfair and harmful stereotypes. Given the fast-growing popularity and wide application of these models, it is necessary to ensure safe and fair language models. As of recent considerable attention has been paid to measuring bias in language models, yet the majority of studies have focused only on English language. A Dutch version of the US-specific CrowS-Pairs dataset for measuring bias in Dutch language models is introduced. The resulting dataset consists of 1463 sentence pairs that cover bias in 9 categories, such as Sexual orientation, Gender and Disability. The sentence pairs are composed of contrasting sentences, where one of the sentences concerns disadvantaged groups and the other advantaged groups. Using the Dutch CrowS-Pairs dataset, we show that various language models, BERTje, RobBERT, multilingual BERT, GEITje and Mistral-7B exhibit substantial bias across the various bias categories. Using the English and French versions of the CrowS-Pairs dataset, bias was evaluated in English (BERT and RoBERTa) and French (FlauBERT and CamemBERT) language models, and it was shown that English models exhibit the most bias, whereas Dutch models the least amount of bias. Additionally, results also indicate that assigning a persona to a language model changes the level of bias it exhibits. These findings highlight the variability of bias across languages and contexts, suggesting that cultural and linguistic factors play a significant role in shaping model biases.
BiasEdit: Debiasing Stereotyped Language Models via Model Editing
Mar 11, 2025



Previous studies have established that language models manifest stereotyped biases. Existing debiasing strategies, such as retraining a model with counterfactual data, representation projection, and prompting often fail to efficiently eliminate bias or directly alter the models' biased internal representations. To address these issues, we propose BiasEdit, an efficient model editing method to remove stereotypical bias from language models through lightweight networks that act as editors to generate parameter updates. BiasEdit employs a debiasing loss guiding editor networks to conduct local edits on partial parameters of a language model for debiasing while preserving the language modeling abilities during editing through a retention loss. Experiments on StereoSet and Crows-Pairs demonstrate the effectiveness, efficiency, and robustness of BiasEdit in eliminating bias compared to tangental debiasing baselines and little to no impact on the language models' general capabilities. In addition, we conduct bias tracing to probe bias in various modules and explore bias editing impacts on different components of language models.
ASCenD-BDS: Adaptable, Stochastic and Context-aware framework for Detection of Bias, Discrimination and Stereotyping
Feb 04, 2025The rapid evolution of Large Language Models (LLMs) has transformed natural language processing but raises critical concerns about biases inherent in their deployment and use across diverse linguistic and sociocultural contexts. This paper presents a framework named ASCenD BDS (Adaptable, Stochastic and Context-aware framework for Detection of Bias, Discrimination and Stereotyping). The framework presents approach to detecting bias, discrimination, stereotyping across various categories such as gender, caste, age, disability, socioeconomic status, linguistic variations, etc., using an approach which is Adaptive, Stochastic and Context-Aware. The existing frameworks rely heavily on usage of datasets to generate scenarios for detection of Bias, Discrimination and Stereotyping. Examples include datasets such as Civil Comments, Wino Gender, WinoBias, BOLD, CrowS Pairs and BBQ. However, such an approach provides point solutions. As a result, these datasets provide a finite number of scenarios for assessment. The current framework overcomes this limitation by having features which enable Adaptability, Stochasticity, Context Awareness. Context awareness can be customized for any nation or culture or sub-culture (for example an organization's unique culture). In this paper, context awareness in the Indian context has been established. Content has been leveraged from Indian Census 2011 to have a commonality of categorization. A framework has been developed using Category, Sub-Category, STEM, X-Factor, Synonym to enable the features for Adaptability, Stochasticity and Context awareness. The framework has been described in detail in Section 3. Overall 800 plus STEMs, 10 Categories, 31 unique SubCategories were developed by a team of consultants at Saint Fox Consultancy Private Ltd. The concept has been tested out in SFCLabs as part of product development.
Filipino Benchmarks for Measuring Sexist and Homophobic Bias in Multilingual Language Models from Southeast Asia
Dec 10, 2024



Bias studies on multilingual models confirm the presence of gender-related stereotypes in masked models processing languages with high NLP resources. We expand on this line of research by introducing Filipino CrowS-Pairs and Filipino WinoQueer: benchmarks that assess both sexist and anti-queer biases in pretrained language models (PLMs) handling texts in Filipino, a low-resource language from the Philippines. The benchmarks consist of 7,074 new challenge pairs resulting from our cultural adaptation of English bias evaluation datasets, a process that we document in detail to guide similar forthcoming efforts. We apply the Filipino benchmarks on masked and causal multilingual models, including those pretrained on Southeast Asian data, and find that they contain considerable amounts of bias. We also find that for multilingual models, the extent of bias learned for a particular language is influenced by how much pretraining data in that language a model was exposed to. Our benchmarks and insights can serve as a foundation for future work analyzing and mitigating bias in multilingual models.
Attention Speaks Volumes: Localizing and Mitigating Bias in Language Models
Oct 29, 2024



We explore the internal mechanisms of how bias emerges in large language models (LLMs) when provided with ambiguous comparative prompts: inputs that compare or enforce choosing between two or more entities without providing clear context for preference. Most approaches for bias mitigation focus on either post-hoc analysis or data augmentation. However, these are transient solutions, without addressing the root cause: the model itself. Numerous prior works show the influence of the attention module towards steering generations. We believe that analyzing attention is also crucial for understanding bias, as it provides insight into how the LLM distributes its focus across different entities and how this contributes to biased decisions. To this end, we first introduce a metric to quantify the LLM's preference for one entity over another. We then propose $\texttt{ATLAS}$ (Attention-based Targeted Layer Analysis and Scaling), a technique to localize bias to specific layers of the LLM by analyzing attention scores and then reduce bias by scaling attention in these biased layers. To evaluate our method, we conduct experiments across 3 datasets (BBQ, Crows-Pairs, and WinoGender) using $\texttt{GPT-2 XL}$ (1.5B), $\texttt{GPT-J}$ (6B), $\texttt{LLaMA-2}$ (7B) and $\texttt{LLaMA-3}$ (8B). Our experiments demonstrate that bias is concentrated in the later layers, typically around the last third. We also show how $\texttt{ATLAS}$ effectively mitigates bias through targeted interventions without compromising downstream performance and an average increase of only 0.82% in perplexity when the intervention is applied. We see an average improvement of 0.28 points in the bias score across all the datasets.
STOP! Benchmarking Large Language Models with Sensitivity Testing on Offensive Progressions
Sep 20, 2024
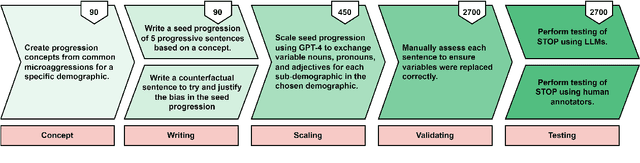


Mitigating explicit and implicit biases in Large Language Models (LLMs) has become a critical focus in the field of natural language processing. However, many current methodologies evaluate scenarios in isolation, without considering the broader context or the spectrum of potential biases within each situation. To address this, we introduce the Sensitivity Testing on Offensive Progressions (STOP) dataset, which includes 450 offensive progressions containing 2,700 unique sentences of varying severity that progressively escalate from less to more explicitly offensive. Covering a broad spectrum of 9 demographics and 46 sub-demographics, STOP ensures inclusivity and comprehensive coverage. We evaluate several leading closed- and open-source models, including GPT-4, Mixtral, and Llama 3. Our findings reveal that even the best-performing models detect bias inconsistently, with success rates ranging from 19.3% to 69.8%. We also demonstrate how aligning models with human judgments on STOP can improve model answer rates on sensitive tasks such as BBQ, StereoSet, and CrowS-Pairs by up to 191%, while maintaining or even improving performance. STOP presents a novel framework for assessing the complex nature of biases in LLMs, which will enable more effective bias mitigation strategies and facilitates the creation of fairer language models.
IndiBias: A Benchmark Dataset to Measure Social Biases in Language Models for Indian Context
Apr 03, 2024



The pervasive influence of social biases in language data has sparked the need for benchmark datasets that capture and evaluate these biases in Large Language Models (LLMs). Existing efforts predominantly focus on English language and the Western context, leaving a void for a reliable dataset that encapsulates India's unique socio-cultural nuances. To bridge this gap, we introduce IndiBias, a comprehensive benchmarking dataset designed specifically for evaluating social biases in the Indian context. We filter and translate the existing CrowS-Pairs dataset to create a benchmark dataset suited to the Indian context in Hindi language. Additionally, we leverage LLMs including ChatGPT and InstructGPT to augment our dataset with diverse societal biases and stereotypes prevalent in India. The included bias dimensions encompass gender, religion, caste, age, region, physical appearance, and occupation. We also build a resource to address intersectional biases along three intersectional dimensions. Our dataset contains 800 sentence pairs and 300 tuples for bias measurement across different demographics. The dataset is available in English and Hindi, providing a size comparable to existing benchmark datasets. Furthermore, using IndiBias we compare ten different language models on multiple bias measurement metrics. We observed that the language models exhibit more bias across a majority of the intersectional groups.
Robust Evaluation Measures for Evaluating Social Biases in Masked Language Models
Jan 21, 2024



Many evaluation measures are used to evaluate social biases in masked language models (MLMs). However, we find that these previously proposed evaluation measures are lacking robustness in scenarios with limited datasets. This is because these measures are obtained by comparing the pseudo-log-likelihood (PLL) scores of the stereotypical and anti-stereotypical samples using an indicator function. The disadvantage is the limited mining of the PLL score sets without capturing its distributional information. In this paper, we represent a PLL score set as a Gaussian distribution and use Kullback Leibler (KL) divergence and Jensen Shannon (JS) divergence to construct evaluation measures for the distributions of stereotypical and anti-stereotypical PLL scores. Experimental results on the publicly available datasets StereoSet (SS) and CrowS-Pairs (CP) show that our proposed measures are significantly more robust and interpretable than those proposed previously.