 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuReader: a Chinese Machine Reading Comprehension Dataset from Real-world Applications
Paper and Code
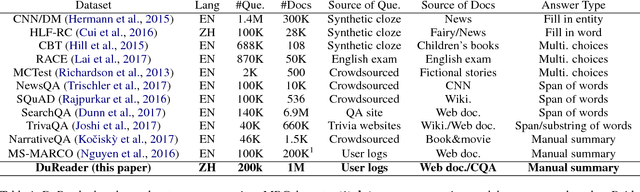
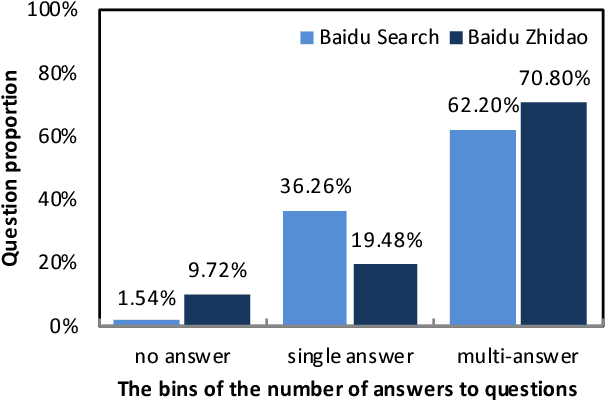

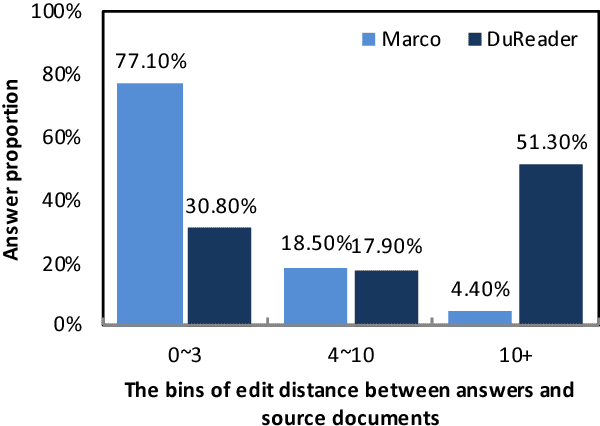
This paper introduces DuReader, a new large-scale, open-domain Chinese ma- chine reading comprehension (MRC) dataset, designed to address real-world MRC. DuReader has three advantages over previous MRC datasets: (1) data sources: questions and documents are based on Baidu Search and Baidu Zhidao; answers are manually generated. (2) question types: it provides rich annotations for more question types, especially yes-no and opinion questions, that leaves more opportunity for the research community. (3) scale: it contains 200K questions, 420K answers and 1M documents; it is the largest Chinese MRC dataset so far. Experiments show that human performance is well above current state-of-the-art baseline systems, leaving plenty of room for the community to make improvements. To help the community make these improvements, both DuReader and baseline systems have been posted online. We also organize a shared competition to encourage the exploration of more models. Since the release of the task, there are significant improvements over the baselines.