 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIEG: Robust Neural Network Training to Tackle Severe Label Noise
Oct 13, 2019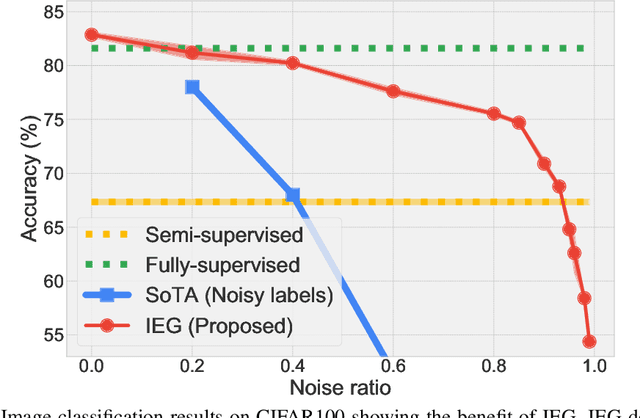
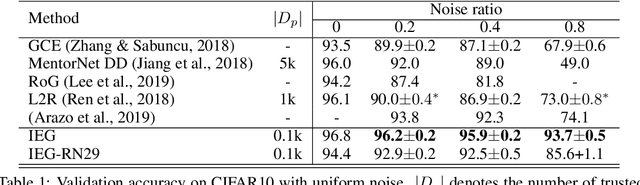
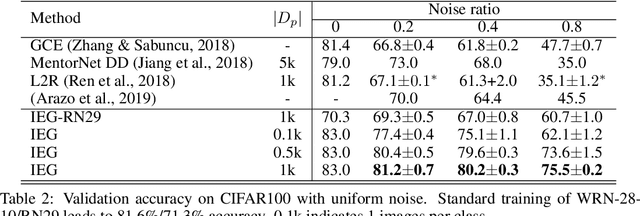

Collecting large-scale data with clean labels for supervised training of neural networks is practically challenging. Although noisy labels are usually cheap to acquire, existing methods suffer severely for training datasets with high noise ratios, making high-cost human labeling a necessity. Here we present a method to train neural networks in a way that is almost invulnerable to severe label noise by utilizing a tiny trusted set. Our method, named IEG, is based on three key insights: (i) Isolation of noisy labels, (ii) Escalation of useful supervision from mislabeled data, and (iii) Guidance from small trusted data. On CIFAR100 with a 40% uniform noise ratio and 10 trusted labeled data per class, our method achieves $80.2{\pm}0.3\%$ classification accuracy, only 1.4% higher error than a neural network trained without label noise. Moreover, increasing the noise ratio to 80%, our method still achieves a high accuracy of $75.5{\pm}0.2\%$, compared to the previous best 47.7%. Finally, our method sets new state of the art on various types of challenging label corruption types and levels and large-scale WebVision benchmarks.
Reducing Uncertainty in Undersampled MRI Reconstruction with Active Acquisition
Feb 08, 2019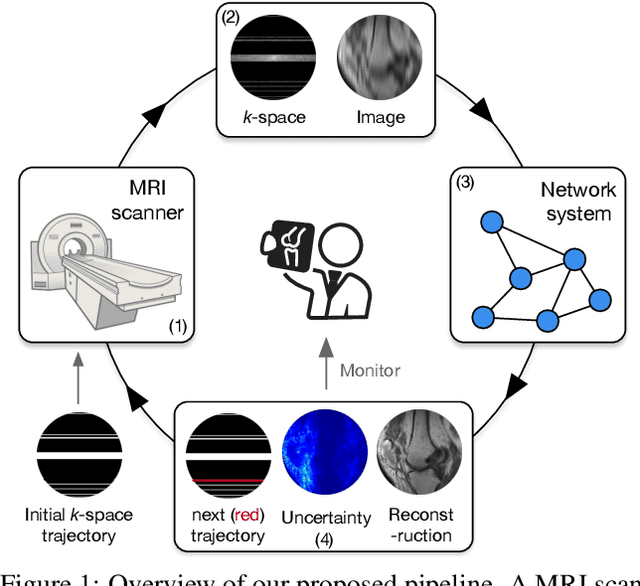
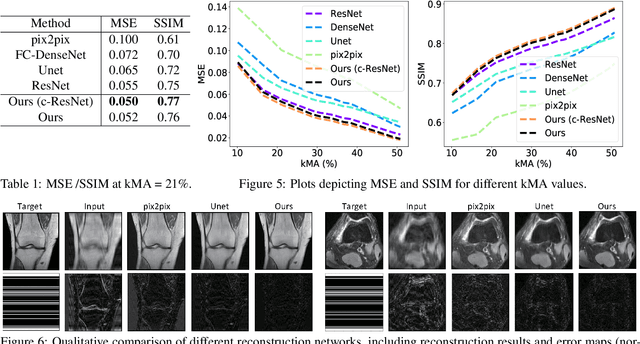
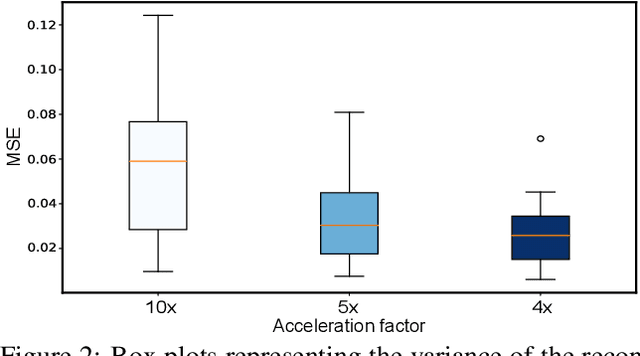
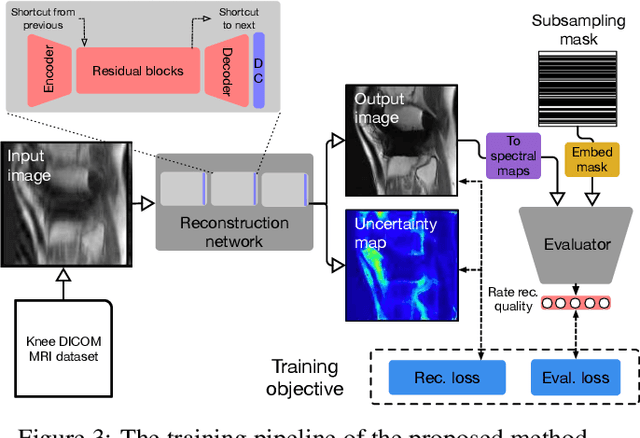
The goal of MRI reconstruction is to restore a high fidelity image from partially observed measurements. This partial view naturally induces reconstruction uncertainty that can only be reduced by acquiring additional measurements. In this paper, we present a novel method for MRI reconstruction that, at inference time, dynamically selects the measurements to take and iteratively refines the prediction in order to best reduce the reconstruction error and, thus, its uncertainty. We validate our method on a large scale knee MRI dataset, as well as on ImageNet. Results show that (1) our system successfully outperforms active acquisition baselines; (2) our uncertainty estimates correlate with error maps; and (3) our ResNet-based architecture surpasses standard pixel-to-pixel models in the task of MRI reconstruction. The proposed method not only shows high-quality reconstructions but also paves the road towards more applicable solutions for accelerating MRI.
fastMRI: An Open Dataset and Benchmarks for Accelerated MRI
Nov 21, 2018
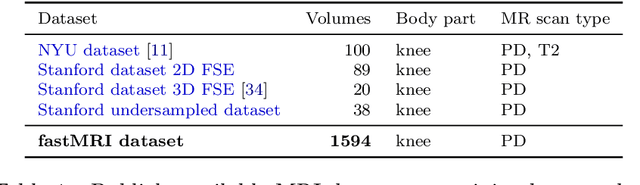
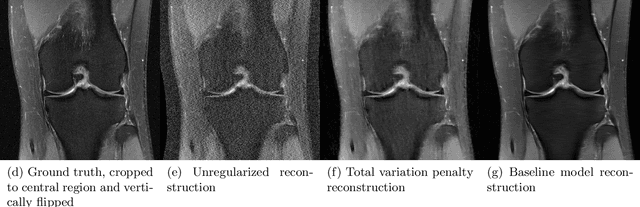
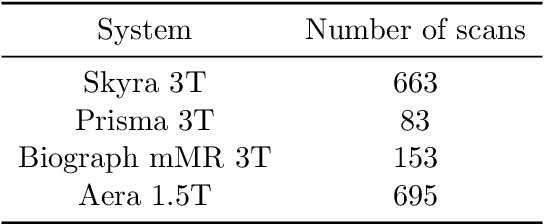
Accelerating Magnetic Resonance Imaging (MRI) by taking fewer measurements has the potential to reduce medical costs, minimize stress to patients and make MRI possible in applications where it is currently prohibitively slow or expensive. We introduce the fastMRI dataset, a large-scale collection of both raw MR measurements and clinical MR images, that can be used for training and evaluation of machine-learning approaches to MR image reconstruction. By introducing standardized evaluation criteria and a freely-accessible dataset, our goal is to help the community make rapid advances in the state of the art for MR image reconstruction. We also provide a self-contained introduction to MRI for machine learning researchers with no medical imaging background.
Hypergraph Neural Networks
Sep 25, 2018
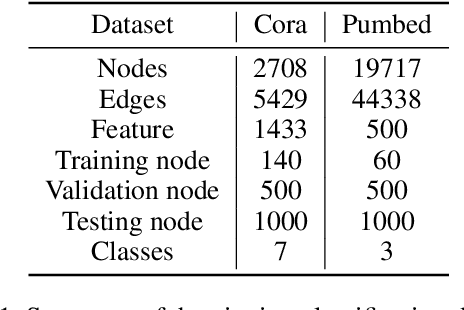
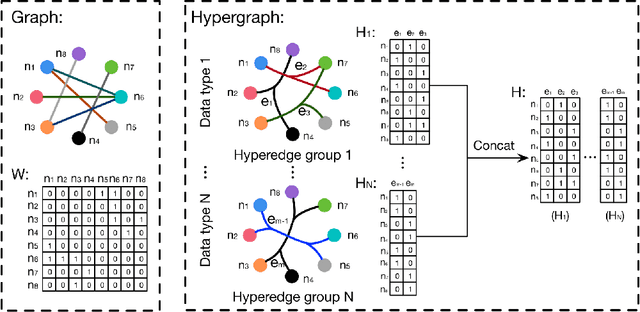
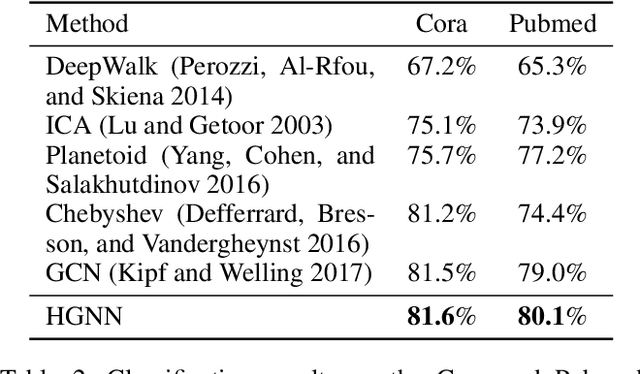
In this paper, we present a hypergraph neural networks (HGNN) framework for data representation learning, which can encode high-order data correlation in a hypergraph structure. Confronting the challenges of learning representation for complex data in real practice, we propose to incorporate such data structure in a hypergraph, which is more flexible on data modeling, especially when dealing with complex data. In this method, a hyperedge convolution operation is designed to handle the data correlation during representation learning. In this way, traditional hypergraph learning procedure can be conducted using hyperedge convolution operations efficiently. HGNN is able to learn the hidden layer representation considering the high-order data structure, which is a general framework considering the complex data correlations. We have conducted experiments on citation network classification and visual object recognition tasks and compared HGNN with graph convolutional networks and other traditional methods. Experimental results demonstrate that the proposed HGNN method outperforms recent state-of-the-art methods. We can also reveal from the results that the proposed HGNN is superior when dealing with multi-modal data compared with existing methods.
Photographic Text-to-Image Synthesis with a Hierarchically-nested Adversarial Network
Apr 06, 2018



This paper presents a novel method to deal with the challenging task of generating photographic images conditioned on semantic image descriptions. Our method introduces accompanying hierarchical-nested adversarial objectives inside the network hierarchies, which regularize mid-level representations and assist generator training to capture the complex image statistics. We present an extensile single-stream generator architecture to better adapt the jointed discriminators and push generated images up to high resolutions. We adopt a multi-purpose adversarial loss to encourage more effective image and text information usage in order to improve the semantic consistency and image fidelity simultaneously. Furthermore, we introduce a new visual-semantic similarity measure to evaluate the semantic consistency of generated images. With extensive experimental validation on three public datasets, our method significantly improves previous state of the arts on all datasets over different evaluation metrics.
Translating and Segmenting Multimodal Medical Volumes with Cycle- and Shape-Consistency Generative Adversarial Network
Feb 27, 2018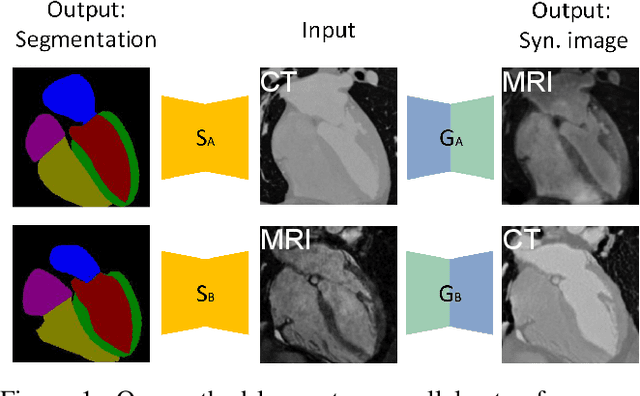
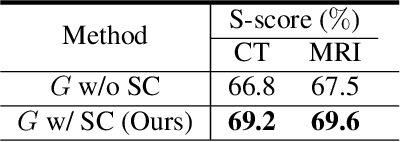
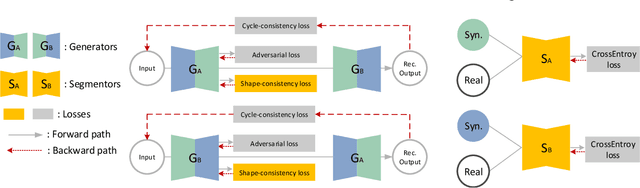
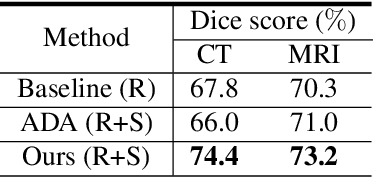
Synthesized medical images have several important applications, e.g., as an intermedium in cross-modality image registration and as supplementary training samples to boost the generalization capability of a classifier. Especially, synthesized computed tomography (CT) data can provide X-ray attenuation map for radiation therapy planning. In this work, we propose a generic cross-modality synthesis approach with the following targets: 1) synthesizing realistic looking 3D images using unpaired training data, 2) ensuring consistent anatomical structures, which could be changed by geometric distortion in cross-modality synthesis and 3) improving volume segmentation by using synthetic data for modalities with limited training samples. We show that these goals can be achieved with an end-to-end 3D convolutional neural network (CNN) composed of mutually-beneficial generators and segmentors for image synthesis and segmentation tasks. The generators are trained with an adversarial loss, a cycle-consistency loss, and also a shape-consistency loss, which is supervised by segmentors, to reduce the geometric distortion. From the segmentation view, the segmentors are boosted by synthetic data from generators in an online manner. Generators and segmentors prompt each other alternatively in an end-to-end training fashion. With extensive experiments on a dataset including a total of 4,496 CT and magnetic resonance imaging (MRI) cardiovascular volumes, we show both tasks are beneficial to each other and coupling these two tasks results in better performance than solving them exclusively.
Revisiting Graph Construction for Fast Image Segmentation
Dec 02, 2017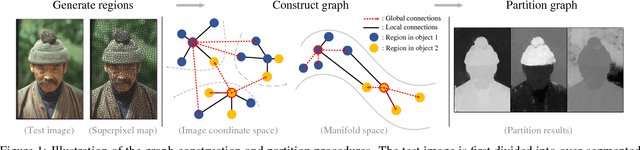
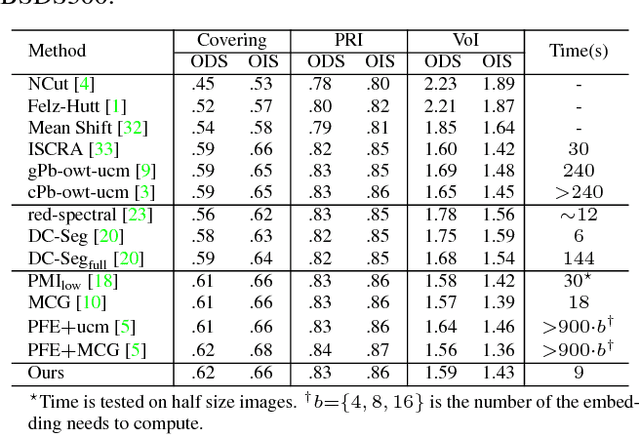

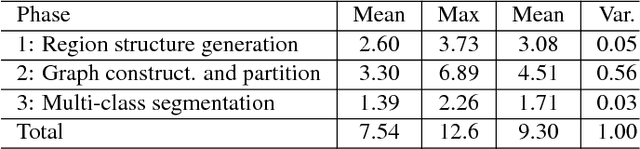
In this paper, we propose a simple but effective method for fast image segmentation. We re-examine the locality-preserving character of spectral clustering by constructing a graph over image regions with both global and local connections. Our novel approach to build graph connections relies on two key observations: 1) local region pairs that co-occur frequently will have a high probability to reside on a common object; 2) spatially distant regions in a common object often exhibit similar visual saliency, which implies their neighborship in a manifold. We present a novel energy function to efficiently conduct graph partitioning. Based on multiple high quality partitions, we show that the generated eigenvector histogram based representation can automatically drive effective unary potentials for a hierarchical random field model to produce multi-class segmentation. Sufficient experiments, on the BSDS500 benchmark, large-scale PASCAL VOC and COCO datasets, demonstrate the competitive segmentation accuracy and significantly improved efficiency of our proposed method compared with other state of the arts.
Recent Advances in the Applications of Convolutional Neural Networks to Medical Image Contour Detection
Aug 24, 2017
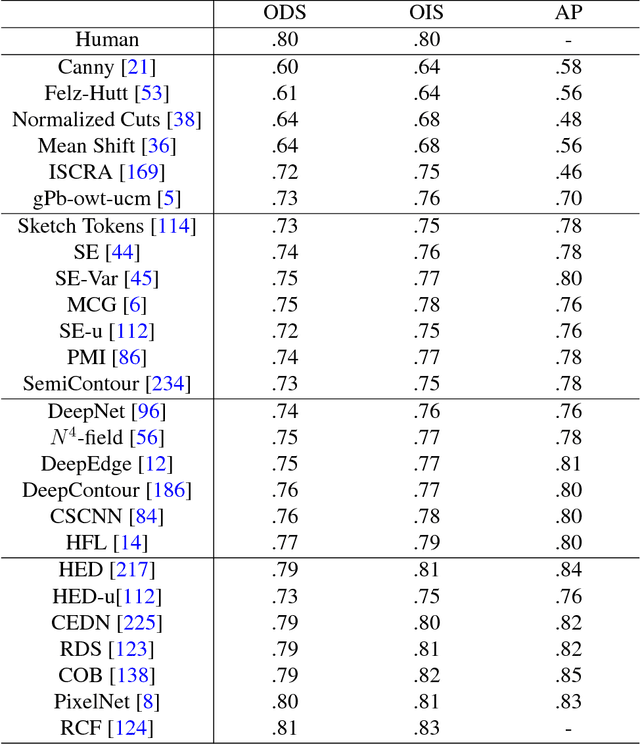
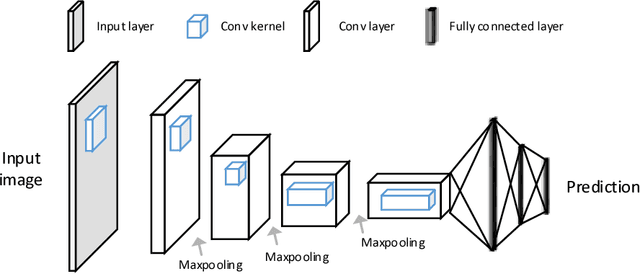
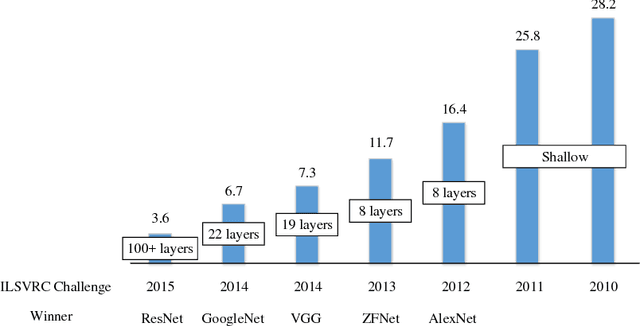
The fast growing deep learning technologies have become the main solution of many machine learning problems for medical image analysis. Deep convolution neural networks (CNNs), as one of the most important branch of the deep learning family, have been widely investigated for various computer-aided diagnosis tasks including long-term problems and continuously emerging new problems. Image contour detection is a fundamental but challenging task that has been studied for more than four decades. Recently, we have witnessed the significantly improved performance of contour detection thanks to the development of CNNs. Beyond purusing performance in existing natural image benchmarks, contour detection plays a particularly important role in medical image analysis. Segmenting various objects from radiology images or pathology images requires accurate detection of contours. However, some problems, such as discontinuity and shape constraints, are insufficiently studied in CNNs. It is necessary to clarify the challenges to encourage further exploration. The performance of CNN based contour detection relies on the state-of-the-art CNN architectures. Careful investigation of their design principles and motivations is critical and beneficial to contour detection. In this paper, we first review recent development of medical image contour detection and point out the current confronting challenges and problems. We discuss the development of general CNNs and their applications in image contours (or edges) detection. We compare those methods in detail, clarify their strengthens and weaknesses. Then we review their recent applications in medical image analysis and point out limitations, with the goal to light some potential directions in medical image analysis. We expect the paper to cover comprehensive technical ingredients of advanced CNNs to enrich the study in the medical image domain.
TandemNet: Distilling Knowledge from Medical Images Using Diagnostic Reports as Optional Semantic References
Aug 10, 2017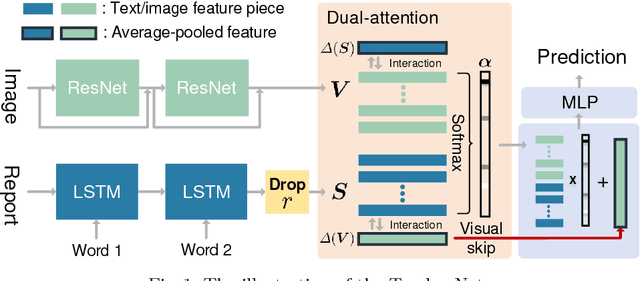

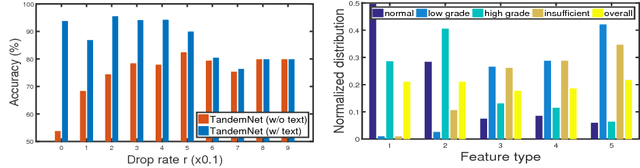
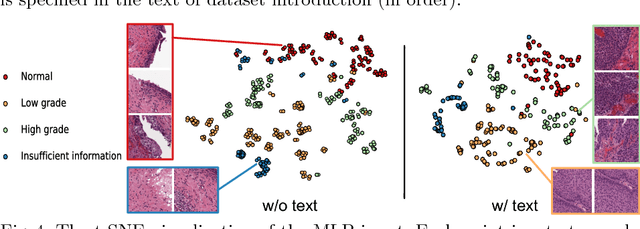
In this paper, we introduce the semantic knowledge of medical images from their diagnostic reports to provide an inspirational network training and an interpretable prediction mechanism with our proposed novel multimodal neural network, namely TandemNet. Inside TandemNet, a language model is used to represent report text, which cooperates with the image model in a tandem scheme. We propose a novel dual-attention model that facilitates high-level interactions between visual and semantic information and effectively distills useful features for prediction. In the testing stage, TandemNet can make accurate image prediction with an optional report text input. It also interprets its prediction by producing attention on the image and text informative feature pieces, and further generating diagnostic report paragraphs. Based on a pathological bladder cancer images and their diagnostic reports (BCIDR) dataset, sufficient experiments demonstrate that our method effectively learns and integrates knowledge from multimodalities and obtains significantly improved performance than comparing baselines.
MDNet: A Semantically and Visually Interpretable Medical Image Diagnosis Network
Jul 08, 2017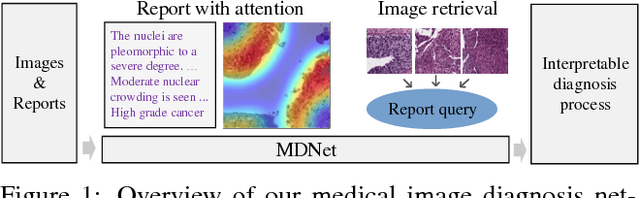
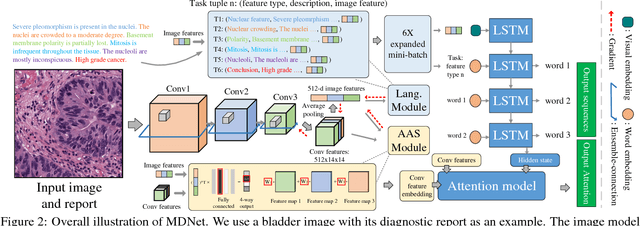
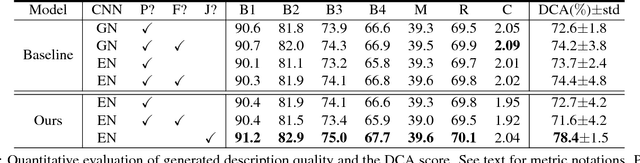
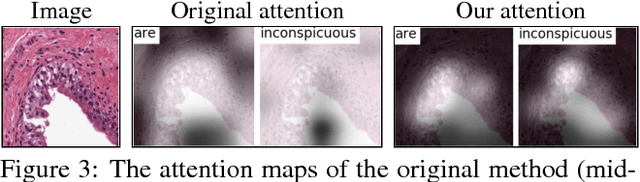
The inability to interpret the model prediction in semantically and visually meaningful ways is a well-known shortcoming of most existing computer-aided diagnosis methods. In this paper, we propose MDNet to establish a direct multimodal mapping between medical images and diagnostic reports that can read images, generate diagnostic reports, retrieve images by symptom descriptions, and visualize attention, to provide justifications of the network diagnosis process. MDNet includes an image model and a language model. The image model is proposed to enhance multi-scale feature ensembles and utilization efficiency. The language model, integrated with our improved attention mechanism, aims to read and explore discriminative image feature descriptions from reports to learn a direct mapping from sentence words to image pixels. The overall network is trained end-to-end by using our developed optimization strategy. Based on a pathology bladder cancer images and its diagnostic reports (BCIDR) dataset, we conduct sufficient experiments to demonstrate that MDNet outperforms comparative baselines. The proposed image model obtains state-of-the-art performance on two CIFAR datasets as well.