 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStraIT: Non-autoregressive Generation with Stratified Image Transformer
Mar 01, 2023We propose Stratified Image Transformer(StraIT), a pure non-autoregressive(NAR) generative model that demonstrates superiority in high-quality image synthesis over existing autoregressive(AR) and diffusion models(DMs). In contrast to the under-exploitation of visual characteristics in existing vision tokenizer, we leverage the hierarchical nature of images to encode visual tokens into stratified levels with emergent properties. Through the proposed image stratification that obtains an interlinked token pair, we alleviate the modeling difficulty and lift the generative power of NAR models. Our experiments demonstrate that StraIT significantly improves NAR generation and out-performs existing DMs and AR methods while being order-of-magnitude faster, achieving FID scores of 3.96 at 256*256 resolution on ImageNet without leveraging any guidance in sampling or auxiliary image classifiers. When equipped with classifier-free guidance, our method achieves an FID of 3.36 and IS of 259.3. In addition, we illustrate the decoupled modeling process of StraIT generation, showing its compelling properties on applications including domain transfer.
QueryForm: A Simple Zero-shot Form Entity Query Framework
Nov 14, 2022



Zero-shot transfer learning for document understanding is a crucial yet under-investigated scenario to help reduce the high cost involved in annotating document entities. We present a novel query-based framework, QueryForm, that extracts entity values from form-like documents in a zero-shot fashion. QueryForm contains a dual prompting mechanism that composes both the document schema and a specific entity type into a query, which is used to prompt a Transformer model to perform a single entity extraction task. Furthermore, we propose to leverage large-scale query-entity pairs generated from form-like webpages with weak HTML annotations to pre-train QueryForm. By unifying pre-training and fine-tuning into the same query-based framework, QueryForm enables models to learn from structured documents containing various entities and layouts, leading to better generalization to target document types without the need for target-specific training data. QueryForm sets new state-of-the-art average F1 score on both the XFUND (+4.6%~10.1%) and the Payment (+3.2%~9.5%) zero-shot benchmark, with a smaller model size and no additional image input.
UNesT: Local Spatial Representation Learning with Hierarchical Transformer for Efficient Medical Segmentation
Sep 28, 2022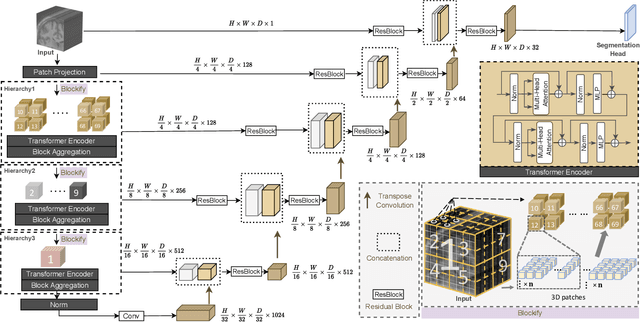

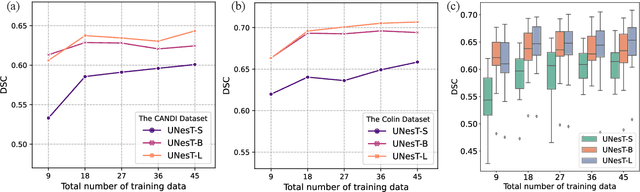
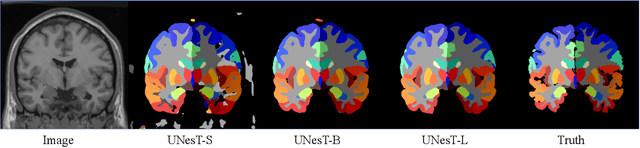
Transformer-based models, capable of learning better global dependencies, have recently demonstrated exceptional representation learning capabilities in computer vision and medical image analysis. Transformer reformats the image into separate patches and realize global communication via the self-attention mechanism. However, positional information between patches is hard to preserve in such 1D sequences, and loss of it can lead to sub-optimal performance when dealing with large amounts of heterogeneous tissues of various sizes in 3D medical image segmentation. Additionally, current methods are not robust and efficient for heavy-duty medical segmentation tasks such as predicting a large number of tissue classes or modeling globally inter-connected tissues structures. Inspired by the nested hierarchical structures in vision transformer, we proposed a novel 3D medical image segmentation method (UNesT), employing a simplified and faster-converging transformer encoder design that achieves local communication among spatially adjacent patch sequences by aggregating them hierarchically. We extensively validate our method on multiple challenging datasets, consisting anatomies of 133 structures in brain, 14 organs in abdomen, 4 hierarchical components in kidney, and inter-connected kidney tumors). We show that UNesT consistently achieves state-of-the-art performance and evaluate its generalizability and data efficiency. Particularly, the model achieves whole brain segmentation task complete ROI with 133 tissue classes in single network, outperforms prior state-of-the-art method SLANT27 ensembled with 27 network tiles, our model performance increases the mean DSC score of the publicly available Colin and CANDI dataset from 0.7264 to 0.7444 and from 0.6968 to 0.7025, respectively.
Deep Hypergraph Structure Learning
Aug 26, 2022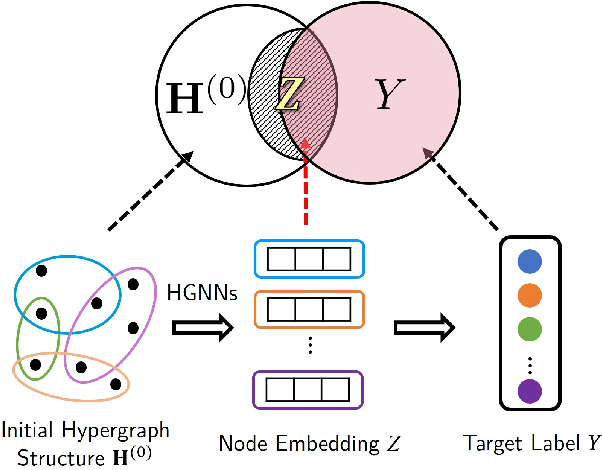

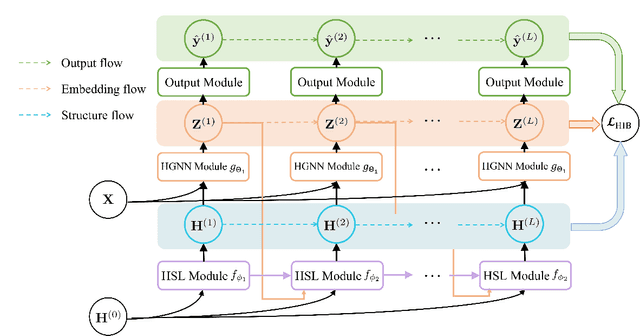
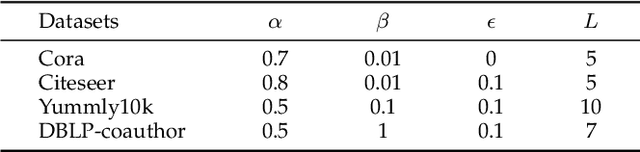
Learning on high-order correlation has shown superiority in data representation learning, where hypergraph has been widely used in recent decades. The performance of hypergraph-based representation learning methods, such as hypergraph neural networks, highly depends on the quality of the hypergraph structure. How to generate the hypergraph structure among data is still a challenging task. Missing and noisy data may lead to "bad connections" in the hypergraph structure and destroy the hypergraph-based representation learning process. Therefore, revealing the high-order structure, i.e., the hypergraph behind the observed data, becomes an urgent but important task. To address this issue, we design a general paradigm of deep hypergraph structure learning, namely DeepHGSL, to optimize the hypergraph structure for hypergraph-based representation learning. Concretely, inspired by the information bottleneck principle for the robustness issue, we first extend it to the hypergraph case, named by the hypergraph information bottleneck (HIB) principle. Then, we apply this principle to guide the hypergraph structure learning, where the HIB is introduced to construct the loss function to minimize the noisy information in the hypergraph structure. The hypergraph structure can be optimized and this process can be regarded as enhancing the correct connections and weakening the wrong connections in the training phase. Therefore, the proposed method benefits to extract more robust representations even on a heavily noisy structure. Finally, we evaluate the model on four benchmark datasets for representation learning. The experimental results on both graph- and hypergraph-structured data demonstrate the effectiveness and robustness of our method compared with other state-of-the-art methods.
DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning
Apr 10, 2022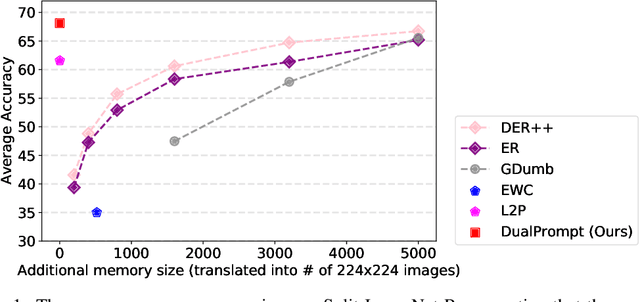
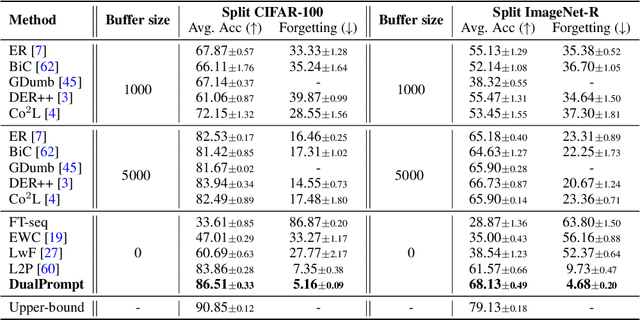
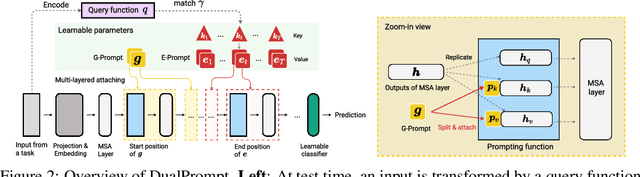
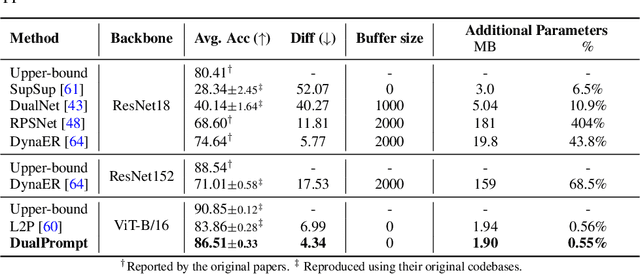
Continual learning aims to enable a single model to learn a sequence of tasks without catastrophic forgetting. Top-performing methods usually require a rehearsal buffer to store past pristine examples for experience replay, which, however, limits their practical value due to privacy and memory constraints. In this work, we present a simple yet effective framework, DualPrompt, which learns a tiny set of parameters, called prompts, to properly instruct a pre-trained model to learn tasks arriving sequentially without buffering past examples. DualPrompt presents a novel approach to attach complementary prompts to the pre-trained backbone, and then formulates the objective as learning task-invariant and task-specific "instructions". With extensive experimental validation, DualPrompt consistently sets state-of-the-art performance under the challenging class-incremental setting. In particular, DualPrompt outperforms recent advanced continual learning methods with relatively large buffer sizes. We also introduce a more challenging benchmark, Split ImageNet-R, to help generalize rehearsal-free continual learning research. Source code is available at https://github.com/google-research/l2p.
Learning Instance-Specific Adaptation for Cross-Domain Segmentation
Mar 30, 2022
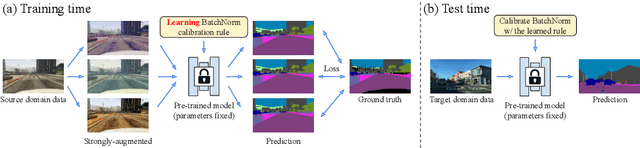
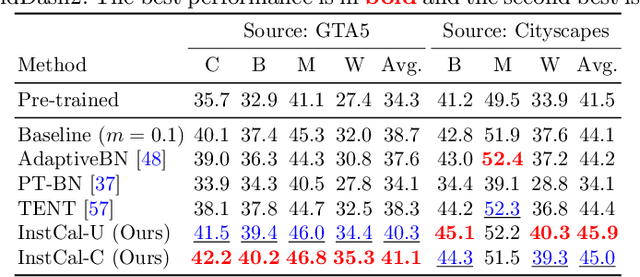

We propose a test-time adaptation method for cross-domain image segmentation. Our method is simple: Given a new unseen instance at test time, we adapt a pre-trained model by conducting instance-specific BatchNorm (statistics) calibration. Our approach has two core components. First, we replace the manually designed BatchNorm calibration rule with a learnable module. Second, we leverage strong data augmentation to simulate random domain shifts for learning the calibration rule. In contrast to existing domain adaptation methods, our method does not require accessing the target domain data at training time or conducting computationally expensive test-time model training/optimization. Equipping our method with models trained by standard recipes achieves significant improvement, comparing favorably with several state-of-the-art domain generalization and one-shot unsupervised domain adaptation approaches. Combining our method with the domain generalization methods further improves performance, reaching a new state of the art.
Exploit Customer Life-time Value with Memoryless Experiments
Jan 17, 2022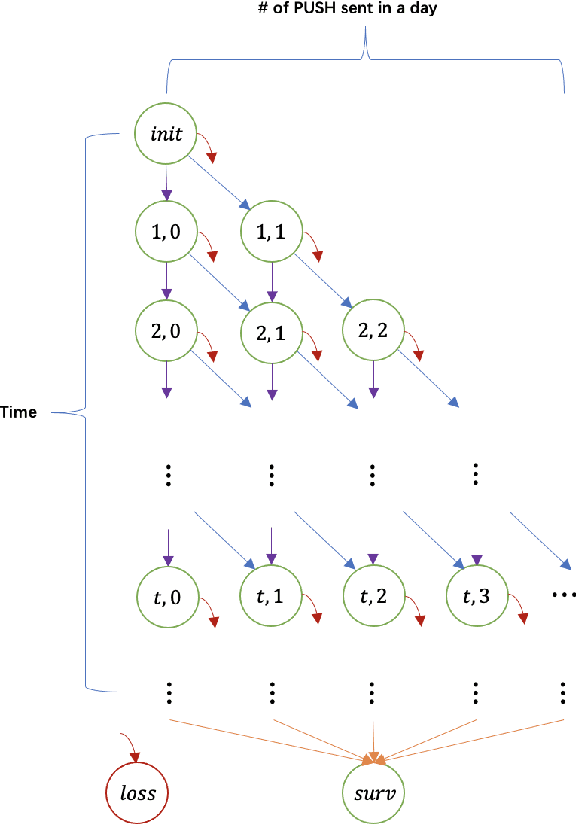
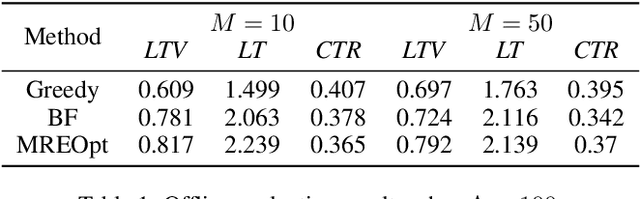
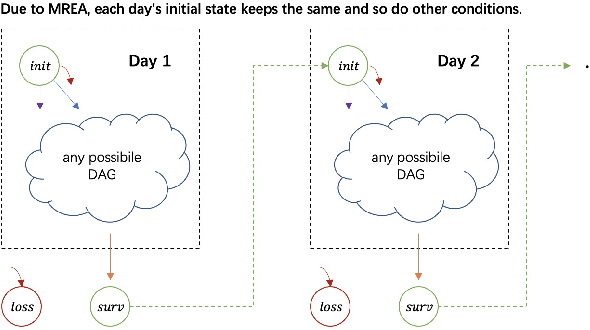
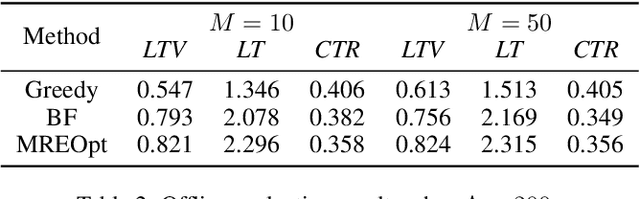
As a measure of the long-term contribution produced by customers in a service or product relationship, life-time value, or LTV, can more comprehensively find the optimal strategy for service delivery. However, it is challenging to accurately abstract the LTV scene, model it reasonably, and find the optimal solution. The current theories either cannot precisely express LTV because of the single modeling structure, or there is no efficient solution. We propose a general LTV modeling method, which solves the problem that customers' long-term contribution is difficult to quantify while existing methods, such as modeling the click-through rate, only pursue the short-term contribution. At the same time, we also propose a fast dynamic programming solution based on a mutated bisection method and the memoryless repeated experiments assumption. The model and method can be applied to different service scenarios, such as the recommendation system. Experiments on real-world datasets confirm the effectiveness of the proposed model and optimization method. In addition, this whole LTV structure was deployed at a large E-commerce mobile phone application, where it managed to select optimal push message sending time and achieved a 10\% LTV improvement.
Learning to Prompt for Continual Learning
Dec 16, 2021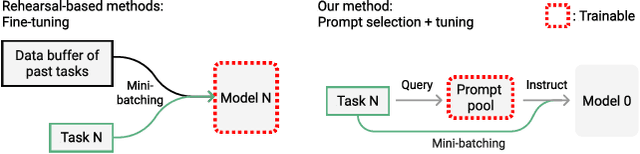
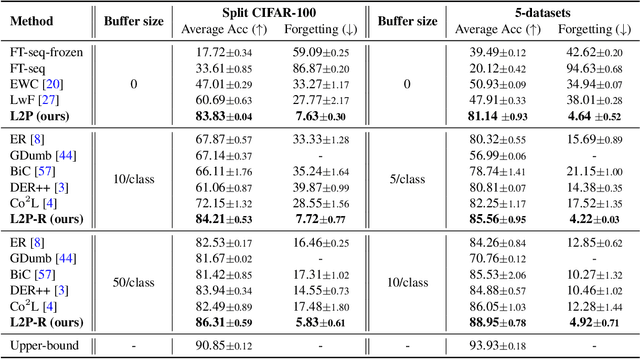
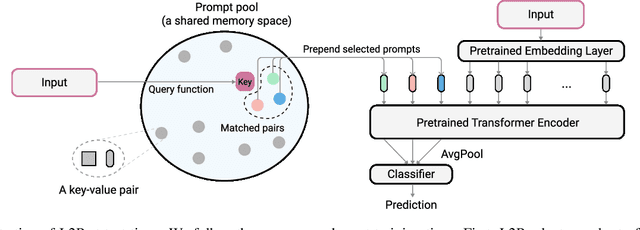
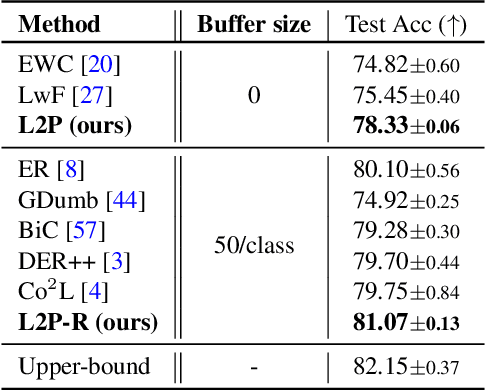
The mainstream paradigm behind continual learning has been to adapt the model parameters to non-stationary data distributions, where catastrophic forgetting is the central challenge. Typical methods rely on a rehearsal buffer or known task identity at test time to retrieve learned knowledge and address forgetting, while this work presents a new paradigm for continual learning that aims to train a more succinct memory system without accessing task identity at test time. Our method learns to dynamically prompt (L2P) a pre-trained model to learn tasks sequentially under different task transitions. In our proposed framework, prompts are small learnable parameters, which are maintained in a memory space. The objective is to optimize prompts to instruct the model prediction and explicitly manage task-invariant and task-specific knowledge while maintaining model plasticity. We conduct comprehensive experiments under popular image classification benchmarks with different challenging continual learning settings, where L2P consistently outperforms prior state-of-the-art methods. Surprisingly, L2P achieves competitive results against rehearsal-based methods even without a rehearsal buffer and is directly applicable to challenging task-agnostic continual learning. Source code is available at https://github.com/google-research/l2p.
Learning Fast Sample Re-weighting Without Reward Data
Sep 07, 2021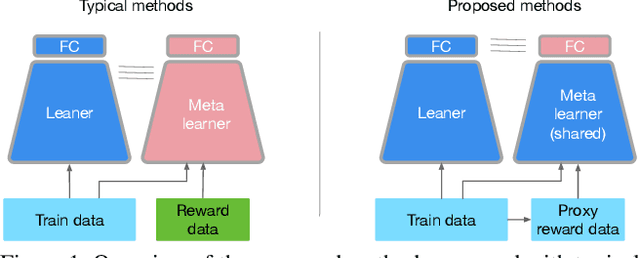
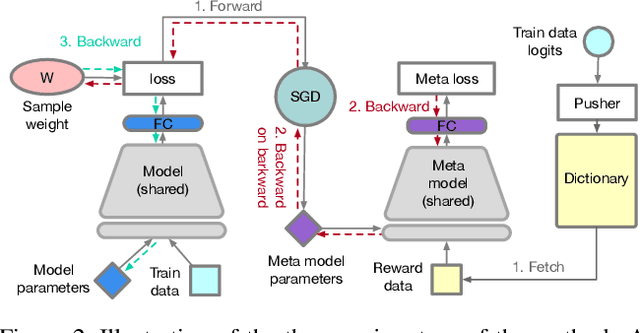
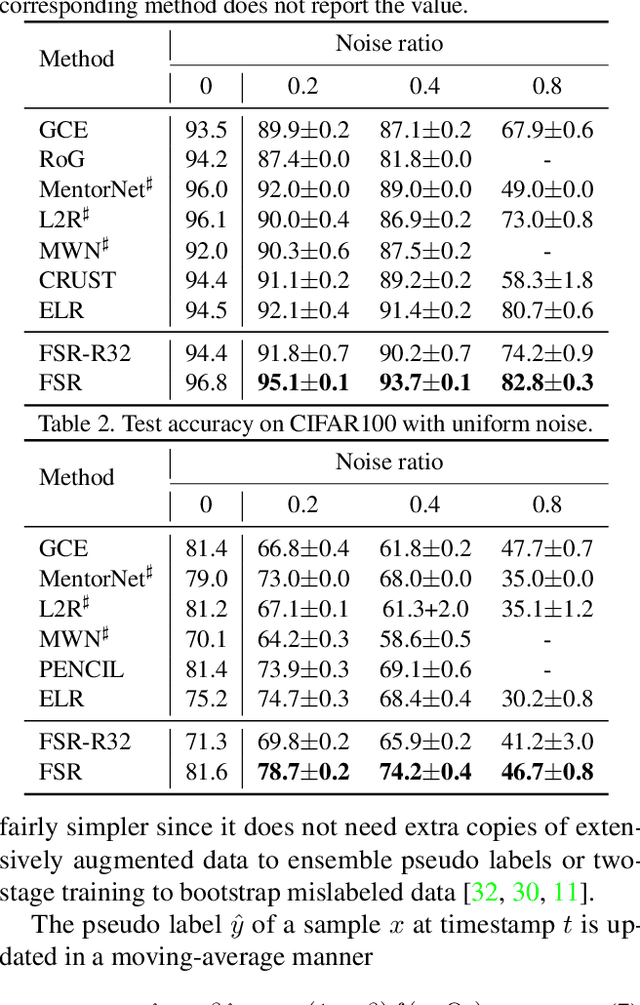
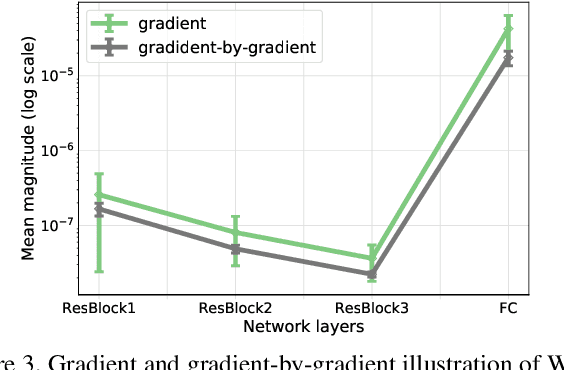
Training sample re-weighting is an effective approach for tackling data biases such as imbalanced and corrupted labels. Recent methods develop learning-based algorithms to learn sample re-weighting strategies jointly with model training based on the frameworks of reinforcement learning and meta learning. However, depending on additional unbiased reward data is limiting their general applicability. Furthermore, existing learning-based sample re-weighting methods require nested optimizations of models and weighting parameters, which requires expensive second-order computation. This paper addresses these two problems and presents a novel learning-based fast sample re-weighting (FSR) method that does not require additional reward data. The method is based on two key ideas: learning from history to build proxy reward data and feature sharing to reduce the optimization cost. Our experiments show the proposed method achieves competitive results compared to state of the arts on label noise robustness and long-tailed recognition, and does so while achieving significantly improved training efficiency. The source code is publicly available at https://github.com/google-research/google-research/tree/master/ieg.
Improved Transformer for High-Resolution GANs
Jun 14, 2021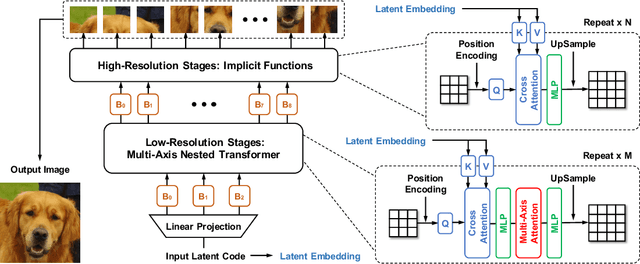
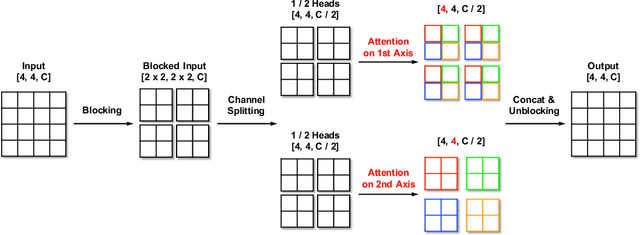
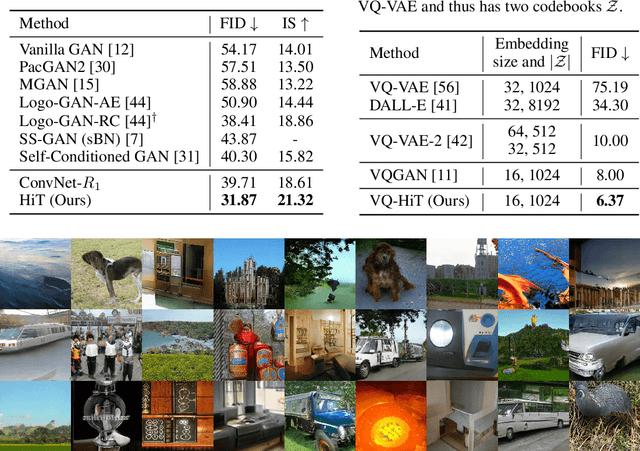

Attention-based models, exemplified by the Transformer, can effectively model long range dependency, but suffer from the quadratic complexity of self-attention operation, making them difficult to be adopted for high-resolution image generation based on Generative Adversarial Networks (GANs). In this paper, we introduce two key ingredients to Transformer to address this challenge. First, in low-resolution stages of the generative process, standard global self-attention is replaced with the proposed multi-axis blocked self-attention which allows efficient mixing of local and global attention. Second, in high-resolution stages, we drop self-attention while only keeping multi-layer perceptrons reminiscent of the implicit neural function. To further improve the performance, we introduce an additional self-modulation component based on cross-attention. The resulting model, denoted as HiT, has a linear computational complexity with respect to the image size and thus directly scales to synthesizing high definition images. We show in the experiments that the proposed HiT achieves state-of-the-art FID scores of 31.87 and 2.95 on unconditional ImageNet $128 \times 128$ and FFHQ $256 \times 256$, respectively, with a reasonable throughput. We believe the proposed HiT is an important milestone for generators in GANs which are completely free of convolutions.