 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent Fuzzing for Escaping Information Cocoons on Digital Social Media
Apr 07, 2026Information cocoons on social media limit users' exposure to posts with diverse viewpoints. Modern platforms use stance detection as an important signal in recommendation and ranking pipelines, which can route posts primarily to like-minded audiences and reduce cross-cutting exposure. This restricts the reach of dissenting opinions and hinders constructive discourse. We take the creator's perspective and investigate how content can be revised to reach beyond existing affinity clusters. We present ContentFuzz, a confidence-guided fuzzing framework that rewrites posts while preserving their human-interpreted intent and induces different machine-inferred stance labels. ContentFuzz aims to route posts beyond their original cocoons. Our method guides a large language model (LLM) to generate meaning-preserving rewrites using confidence feedback from stance detection models. Evaluated on four representative stance detection models across three datasets in two languages, ContentFuzz effectively changes machine-classified stance labels, while maintaining semantic integrity with respect to the original content.
CARD: Towards Conditional Design of Multi-agent Topological Structures
Mar 01, 2026Large language model (LLM)-based multi-agent systems have shown strong capabilities in tasks such as code generation and collaborative reasoning. However, the effectiveness and robustness of these systems critically depend on their communication topology, which is often fixed or statically learned, ignoring real-world dynamics such as model upgrades, API (or tool) changes, or knowledge source variability. To address this limitation, we propose CARD (Conditional Agentic Graph Designer), a conditional graph-generation framework that instantiates AMACP, a protocol for adaptive multi-agent communication. CARD explicitly incorporates dynamic environmental signals into graph construction, enabling topology adaptation at both training and runtime. Through a conditional variational graph encoder and environment-aware optimization, CARD produces communication structures that are both effective and resilient to shifts in model capability or resource availability. Empirical results on HumanEval, MATH, and MMLU demonstrate that CARD consistently outperforms static and prompt-based baselines, achieving higher accuracy and robustness across diverse conditions. The source code is available at: https://github.com/Warma10032/CARD.
Who Deserves the Reward? SHARP: Shapley Credit-based Optimization for Multi-Agent System
Feb 09, 2026Integrating Large Language Models (LLMs) with external tools via multi-agent systems offers a promising new paradigm for decomposing and solving complex problems. However, training these systems remains notoriously difficult due to the credit assignment challenge, as it is often unclear which specific functional agent is responsible for the success or failure of decision trajectories. Existing methods typically rely on sparse or globally broadcast rewards, failing to capture individual contributions and leading to inefficient reinforcement learning. To address these limitations, we introduce the Shapley-based Hierarchical Attribution for Reinforcement Policy (SHARP), a novel framework for optimizing multi-agent reinforcement learning via precise credit attribution. SHARP effectively stabilizes training by normalizing agent-specific advantages across trajectory groups, primarily through a decomposed reward mechanism comprising a global broadcast-accuracy reward, a Shapley-based marginal-credit reward for each agent, and a tool-process reward to improve execution efficiency. Extensive experiments across various real-world benchmarks demonstrate that SHARP significantly outperforms recent state-of-the-art baselines, achieving average match improvements of 23.66% and 14.05% over single-agent and multi-agent approaches, respectively.
Designing the Game to Play: Optimizing Payoff Structure in Security Games
May 22, 2018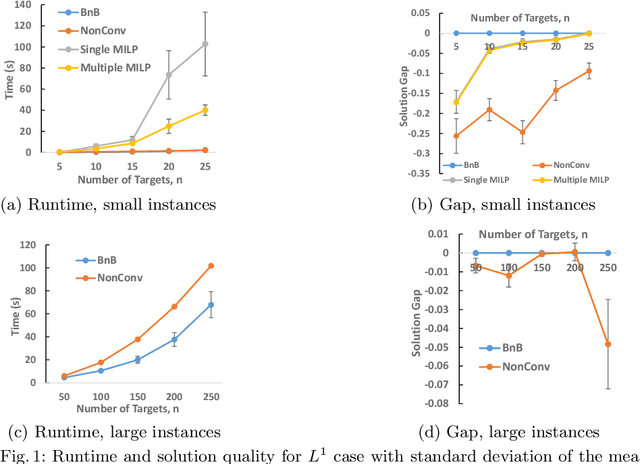
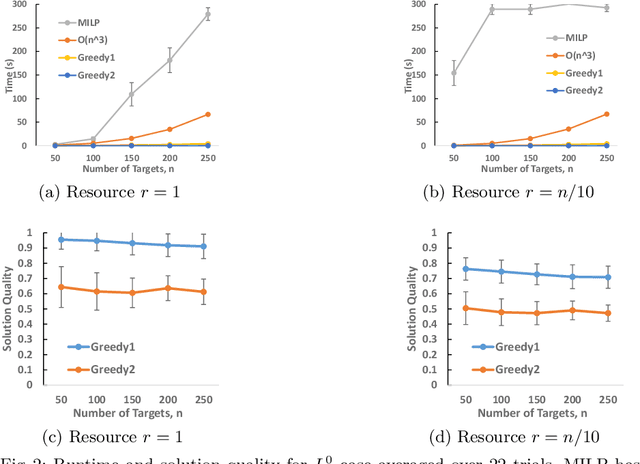
Effective game-theoretic modeling of defender-attacker behavior is becoming increasingly important. In many domains, the defender functions not only as a player but also the designer of the game's payoff structure. We study Stackelberg Security Games where the defender, in addition to allocating defensive resources to protect targets from the attacker, can strategically manipulate the attacker's payoff under budget constraints in weighted L^p-norm form regarding the amount of change. Focusing on problems with weighted L^1-norm form constraint, we present (i) a mixed integer linear program-based algorithm with approximation guarantee; (ii) a branch-and-bound based algorithm with improved efficiency achieved by effective pruning; (iii) a polynomial time approximation scheme for a special but practical class of problems. In addition, we show that problems under budget constraints in L^0-norm form and weighted L^\infty-norm form can be solved in polynomial time. We provide an extensive experimental evaluation of our proposed algorithms.