 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOdysseyArena: Benchmarking Large Language Models For Long-Horizon, Active and Inductive Interactions
Feb 05, 2026The rapid advancement of Large Language Models (LLMs) has catalyzed the development of autonomous agents capable of navigating complex environments. However, existing evaluations primarily adopt a deductive paradigm, where agents execute tasks based on explicitly provided rules and static goals, often within limited planning horizons. Crucially, this neglects the inductive necessity for agents to discover latent transition laws from experience autonomously, which is the cornerstone for enabling agentic foresight and sustaining strategic coherence. To bridge this gap, we introduce OdysseyArena, which re-centers agent evaluation on long-horizon, active, and inductive interactions. We formalize and instantiate four primitives, translating abstract transition dynamics into concrete interactive environments. Building upon this, we establish OdysseyArena-Lite for standardized benchmarking, providing a set of 120 tasks to measure an agent's inductive efficiency and long-horizon discovery. Pushing further, we introduce OdysseyArena-Challenge to stress-test agent stability across extreme interaction horizons (e.g., > 200 steps). Extensive experiments on 15+ leading LLMs reveal that even frontier models exhibit a deficiency in inductive scenarios, identifying a critical bottleneck in the pursuit of autonomous discovery in complex environments. Our code and data are available at https://github.com/xufangzhi/Odyssey-Arena
MindMerger: Efficient Boosting LLM Reasoning in non-English Languages
May 27, 2024Reasoning capabilities are crucial for Large Language Models (LLMs), yet a notable gap exists between English and non-English languages. To bridge this disparity, some works fine-tune LLMs to relearn reasoning capabilities in non-English languages, while others replace non-English inputs with an external model's outputs such as English translation text to circumvent the challenge of LLM understanding non-English. Unfortunately, these methods often underutilize the built-in skilled reasoning and useful language understanding capabilities of LLMs. In order to better utilize the minds of reasoning and language understanding in LLMs, we propose a new method, namely MindMerger, which merges LLMs with the external language understanding capabilities from multilingual models to boost the multilingual reasoning performance. Furthermore, a two-step training scheme is introduced to first train to embeded the external capabilities into LLMs and then train the collaborative utilization of the external capabilities and the built-in capabilities in LLMs. Experiments on three multilingual reasoning datasets and a language understanding dataset demonstrate that MindMerger consistently outperforms all baselines, especially in low-resource languages. Without updating the parameters of LLMs, the average accuracy improved by 6.7% and 8.0% across all languages and low-resource languages on the MGSM dataset, respectively.
Enhancing In-Context Learning with Answer Feedback for Multi-Span Question Answering
Jun 07, 2023Whereas the recent emergence of large language models (LLMs) like ChatGPT has exhibited impressive general performance, it still has a large gap with fully-supervised models on specific tasks such as multi-span question answering. Previous researches found that in-context learning is an effective approach to exploiting LLM, by using a few task-related labeled data as demonstration examples to construct a few-shot prompt for answering new questions. A popular implementation is to concatenate a few questions and their correct answers through simple templates, informing LLM of the desired output. In this paper, we propose a novel way of employing labeled data such that it also informs LLM of some undesired output, by extending demonstration examples with feedback about answers predicted by an off-the-shelf model, e.g., correct, incorrect, or incomplete. Experiments on three multi-span question answering datasets as well as a keyphrase extraction dataset show that our new prompting strategy consistently improves LLM's in-context learning performance.
Clues Before Answers: Generation-Enhanced Multiple-Choice QA
Apr 30, 2022
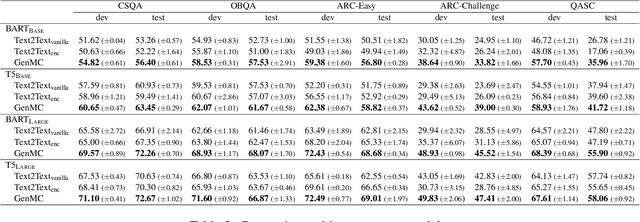
A trending paradigm for multiple-choice question answering (MCQA) is using a text-to-text framework. By unifying data in different tasks into a single text-to-text format, it trains a generative encoder-decoder model which is both powerful and universal. However, a side effect of twisting a generation target to fit the classification nature of MCQA is the under-utilization of the decoder and the knowledge that can be decoded. To exploit the generation capability and underlying knowledge of a pre-trained encoder-decoder model, in this paper, we propose a generation-enhanced MCQA model named GenMC. It generates a clue from the question and then leverages the clue to enhance a reader for MCQA. It outperforms text-to-text models on multiple MCQA datasets.
When Retriever-Reader Meets Scenario-Based Multiple-Choice Questions
Sep 05, 2021

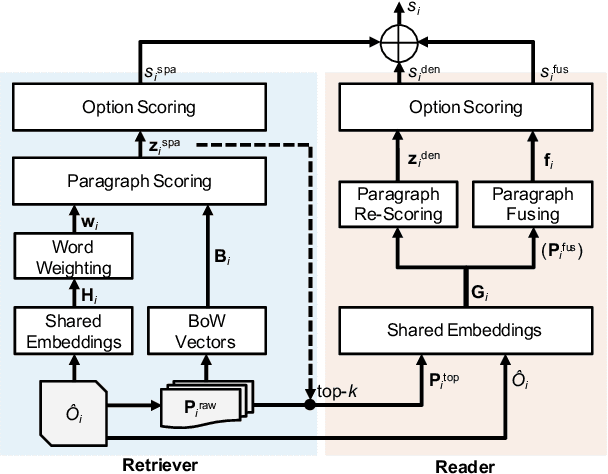
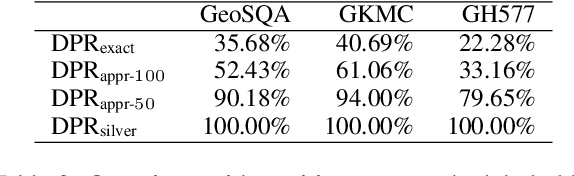
Scenario-based question answering (SQA) requires retrieving and reading paragraphs from a large corpus to answer a question which is contextualized by a long scenario description. Since a scenario contains both keyphrases for retrieval and much noise, retrieval for SQA is extremely difficult. Moreover, it can hardly be supervised due to the lack of relevance labels of paragraphs for SQA. To meet the challenge, in this paper we propose a joint retriever-reader model called JEEVES where the retriever is implicitly supervised only using QA labels via a novel word weighting mechanism. JEEVES significantly outperforms a variety of strong baselines on multiple-choice questions in three SQA datasets.
Enriching Documents with Compact, Representative, Relevant Knowledge Graphs
May 10, 2020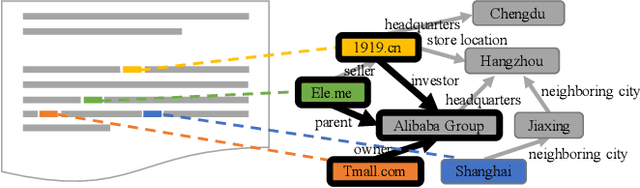

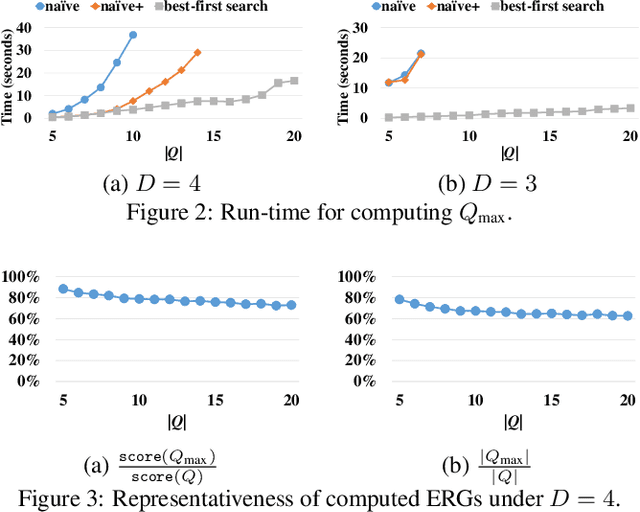
A prominent application of knowledge graph (KG) is document enrichment. Existing methods identify mentions of entities in a background KG and enrich documents with entity types and direct relations. We compute an entity relation subgraph (ERG) that can more expressively represent indirect relations among a set of mentioned entities. To find compact, representative, and relevant ERGs for effective enrichment, we propose an efficient best-first search algorithm to solve a new combinatorial optimization problem that achieves a trade-off between representativeness and compactness, and then we exploit ontological knowledge to rank ERGs by entity-based document-KG and intra-KG relevance. Extensive experiments and user studies show the promising performance of our approach.
GeoSQA: A Benchmark for Scenario-based Question Answering in the Geography Domain at High School Level
Aug 20, 2019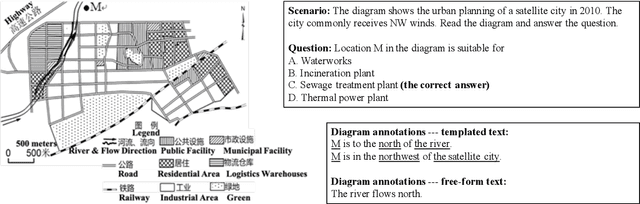
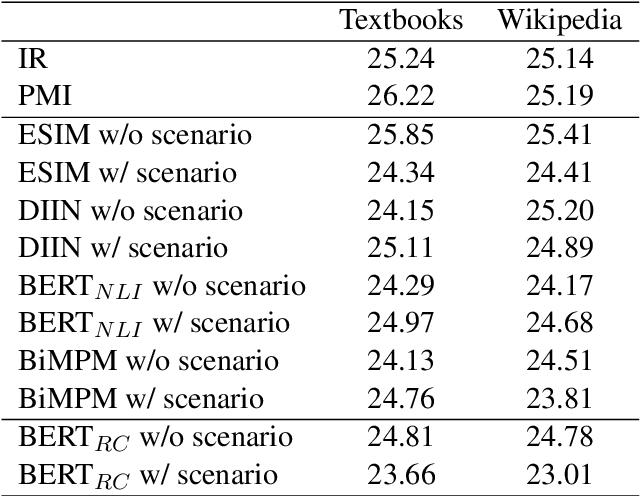
Scenario-based question answering (SQA) has attracted increasing research attention. It typically requires retrieving and integrating knowledge from multiple sources, and applying general knowledge to a specific case described by a scenario. SQA widely exists in the medical, geography, and legal domains---both in practice and in the exams. In this paper, we introduce the GeoSQA dataset. It consists of 1,981 scenarios and 4,110 multiple-choice questions in the geography domain at high school level, where diagrams (e.g., maps, charts) have been manually annotated with natural language descriptions to benefit NLP research. Benchmark results on a variety of state-of-the-art methods for question answering, textual entailment, and reading comprehension demonstrate the unique challenges presented by SQA for future research.