 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRHO ($ρ$): Reducing Hallucination in Open-domain Dialogues with Knowledge Grounding
Dec 03, 2022



Dialogue systems can leverage large pre-trained language models and knowledge to generate fluent and informative responses. However, these models are still prone to produce hallucinated responses not supported by the input source, which greatly hinders their application. The heterogeneity between external knowledge and dialogue context challenges representation learning and source integration, and further contributes to unfaithfulness. To handle this challenge and generate more faithful responses, this paper presents RHO ($\rho$) utilizing the representations of linked entities and relation predicates from a knowledge graph (KG). We propose (1) local knowledge grounding to combine textual embeddings with the corresponding KG embeddings; and (2) global knowledge grounding to equip RHO with multi-hop reasoning abilities via the attention mechanism. In addition, we devise a response re-ranking technique based on walks over KG sub-graphs for better conversational reasoning. Experimental results on OpenDialKG show that our approach significantly outperforms state-of-the-art methods on both automatic and human evaluation by a large margin, especially in hallucination reduction (17.54% in FeQA).
Plausible May Not Be Faithful: Probing Object Hallucination in Vision-Language Pre-training
Oct 14, 2022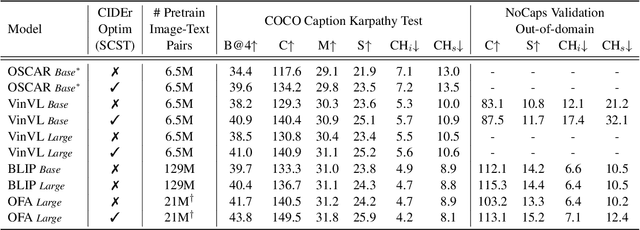

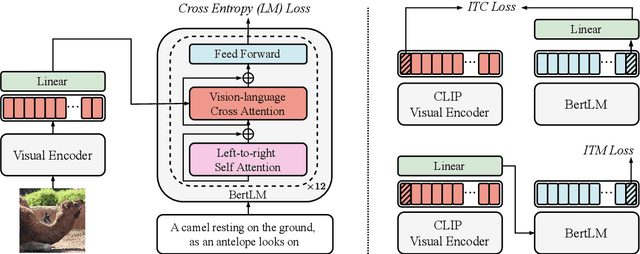
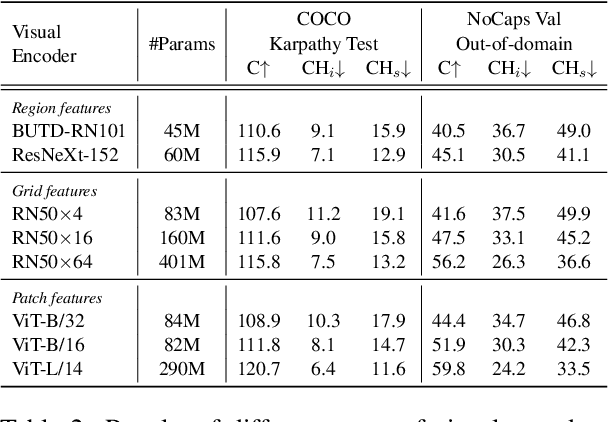
Large-scale vision-language pre-trained (VLP) models are prone to hallucinate non-existent visual objects when generating text based on visual information. In this paper, we exhaustively probe the object hallucination problem from three aspects. First, we examine various state-of-the-art VLP models, showing that models achieving better scores on standard metrics(e.g., BLEU-4, CIDEr) could hallucinate objects more frequently. Second, we investigate how different types of visual features in VLP influence hallucination, including region-based, grid-based, and patch-based. Surprisingly, we find that patch-based features perform the best and smaller patch resolution yields a non-trivial reduction in object hallucination. Third, we decouple various VLP objectives and demonstrate their effectiveness in alleviating object hallucination. Based on that, we propose a new pre-training loss, object masked language modeling, to further reduce object hallucination. We evaluate models on both COCO (in-domain) and NoCaps (out-of-domain) datasets with our improved CHAIR metric. Furthermore, we investigate the effects of various text decoding strategies and image augmentation methods on object hallucination.
Convex Analysis at Infinity: An Introduction to Astral Space
May 06, 2022Not all convex functions on $\mathbb{R}^n$ have finite minimizers; some can only be minimized by a sequence as it heads to infinity. In this work, we aim to develop a theory for understanding such minimizers at infinity. We study astral space, a compact extension of $\mathbb{R}^n$ to which such points at infinity have been added. Astral space is constructed to be as small as possible while still ensuring that all linear functions can be continuously extended to the new space. Although astral space includes all of $\mathbb{R}^n$, it is not a vector space, nor even a metric space. However, it is sufficiently well-structured to allow useful and meaningful extensions of concepts of convexity, conjugacy, and subdifferentials. We develop these concepts and analyze various properties of convex functions on astral space, including the detailed structure of their minimizers, exact characterizations of continuity, and convergence of descent algorithms.
VScript: Controllable Script Generation with Audio-Visual Presentation
Mar 01, 2022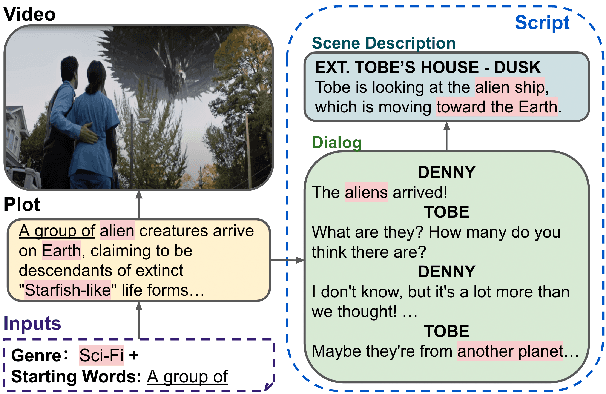
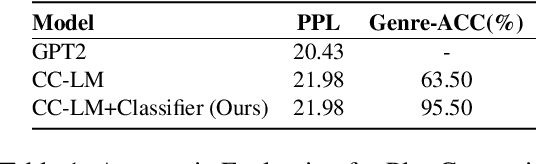
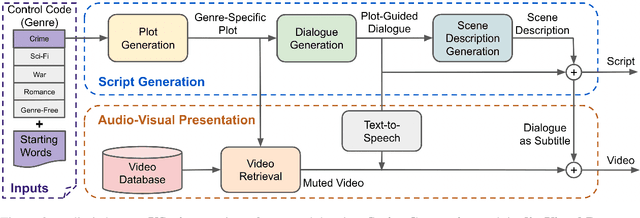
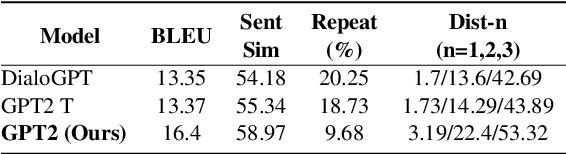
Automatic script generation could save a considerable amount of resources and offer inspiration to professional scriptwriters. We present VScript, a controllable pipeline that generates complete scripts including dialogues and scene descriptions, and presents visually using video retrieval and aurally using text-to-speech for spoken dialogue. With an interactive interface, our system allows users to select genres and input starting words that control the theme and development of the generated script. We adopt a hierarchical structure, which generates the plot, then the script and its audio-visual presentation. We also introduce a novel approach to plot-guided dialogue generation by treating it as an inverse dialogue summarization. Experiment results show that our approach outperforms the baselines on both automatic and human evaluations, especially in terms of genre control.
Reproducibility in Optimization: Theoretical Framework and Limits
Feb 09, 2022
We initiate a formal study of reproducibility in optimization. We define a quantitative measure of reproducibility of optimization procedures in the face of noisy or error-prone operations such as inexact or stochastic gradient computations or inexact initialization. We then analyze several convex optimization settings of interest such as smooth, non-smooth, and strongly-convex objective functions and establish tight bounds on the limits of reproducibility in each setting. Our analysis reveals a fundamental trade-off between computation and reproducibility: more computation is necessary (and sufficient) for better reproducibility.
Survey of Hallucination in Natural Language Generation
Feb 08, 2022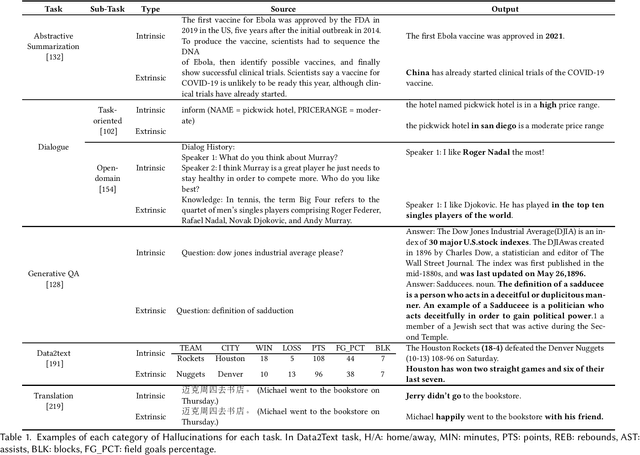
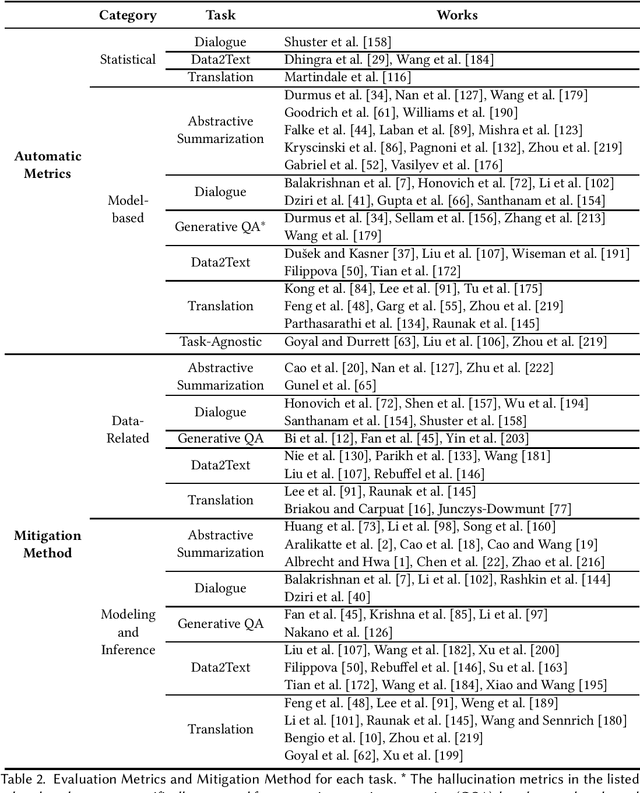
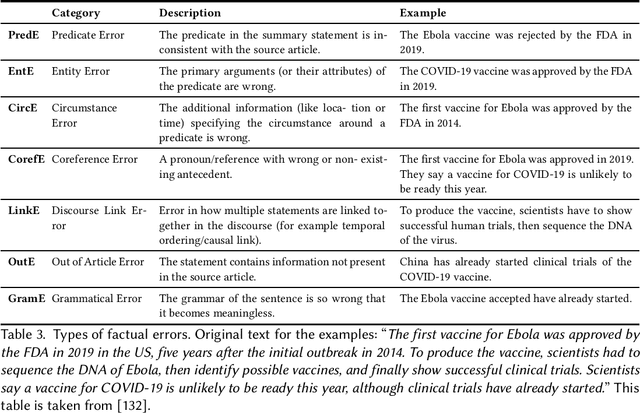
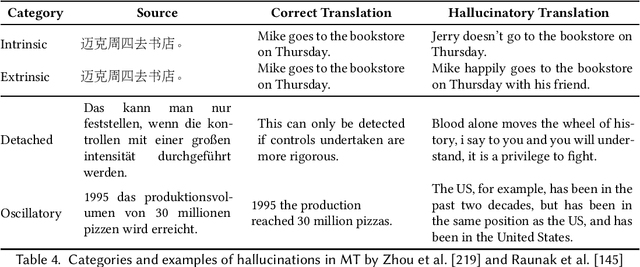
Natural Language Generation (NLG) has improved exponentially in recent years thanks to the development of deep learning technologies such as Transformer-based language models. This advancement has led to more fluent and coherent natural language generation, naturally leading to development in downstream tasks such as abstractive summarization, dialogue generation and data-to-text generation. However, it is also investigated that such generation includes hallucinated texts, which makes the performances of text generation fail to meet users' expectations in many real-world scenarios. In order to address this issue, studies in evaluation and mitigation methods of hallucinations have been presented in various tasks, but have not been reviewed in a combined manner. In this survey, we provide a broad overview of the research progress and challenges in the hallucination problem of NLG. The survey is organized into two big divisions: (i) a general overview of metrics, mitigation methods, and future directions; (ii) task-specific research progress for hallucinations in a large set of downstream tasks: abstractive summarization, dialogue generation, generative question answering, data-to-text generation, and machine translation. This survey could facilitate collaborative efforts among researchers in these tasks.
Agnostic Learnability of Halfspaces via Logistic Loss
Jan 31, 2022
We investigate approximation guarantees provided by logistic regression for the fundamental problem of agnostic learning of homogeneous halfspaces. Previously, for a certain broad class of "well-behaved" distributions on the examples, Diakonikolas et al. (2020) proved an $\tilde{\Omega}(\textrm{OPT})$ lower bound, while Frei et al. (2021) proved an $\tilde{O}(\sqrt{\textrm{OPT}})$ upper bound, where $\textrm{OPT}$ denotes the best zero-one/misclassification risk of a homogeneous halfspace. In this paper, we close this gap by constructing a well-behaved distribution such that the global minimizer of the logistic risk over this distribution only achieves $\Omega(\sqrt{\textrm{OPT}})$ misclassification risk, matching the upper bound in (Frei et al., 2021). On the other hand, we also show that if we impose a radial-Lipschitzness condition in addition to well-behaved-ness on the distribution, logistic regression on a ball of bounded radius reaches $\tilde{O}(\textrm{OPT})$ misclassification risk. Our techniques also show for any well-behaved distribution, regardless of radial Lipschitzness, we can overcome the $\Omega(\sqrt{\textrm{OPT}})$ lower bound for logistic loss simply at the cost of one additional convex optimization step involving the hinge loss and attain $\tilde{O}(\textrm{OPT})$ misclassification risk. This two-step convex optimization algorithm is simpler than previous methods obtaining this guarantee, all of which require solving $O(\log(1/\textrm{OPT}))$ minimization problems.
Actor-critic is implicitly biased towards high entropy optimal policies
Oct 21, 2021We show that the simplest actor-critic method -- a linear softmax policy updated with TD through interaction with a linear MDP, but featuring no explicit regularization or exploration -- does not merely find an optimal policy, but moreover prefers high entropy optimal policies. To demonstrate the strength of this bias, the algorithm not only has no regularization, no projections, and no exploration like $\epsilon$-greedy, but is moreover trained on a single trajectory with no resets. The key consequence of the high entropy bias is that uniform mixing assumptions on the MDP, which exist in some form in all prior work, can be dropped: the implicit regularization of the high entropy bias is enough to ensure that all chains mix and an optimal policy is reached with high probability. As auxiliary contributions, this work decouples concerns between the actor and critic by writing the actor update as an explicit mirror descent, provides tools to uniformly bound mixing times within KL balls of policy space, and provides a projection-free TD analysis with its own implicit bias which can be run from an unmixed starting distribution.
Fast Margin Maximization via Dual Acceleration
Jul 01, 2021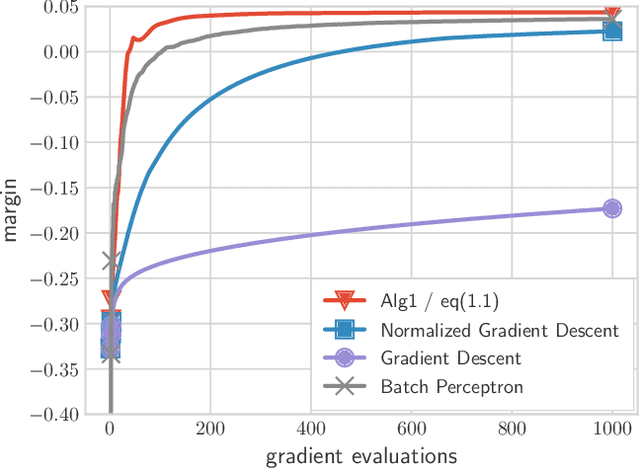
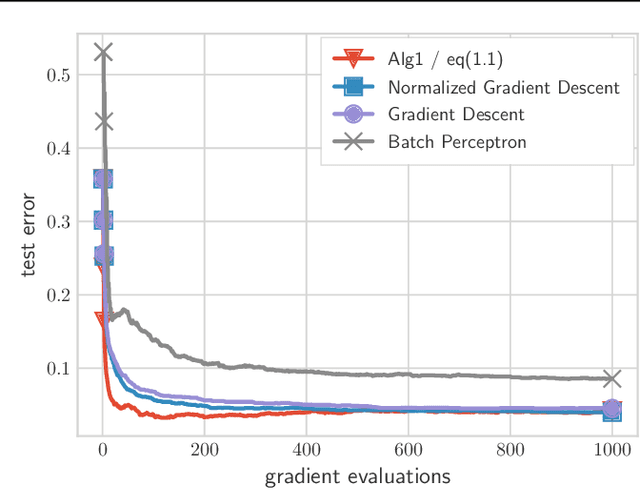
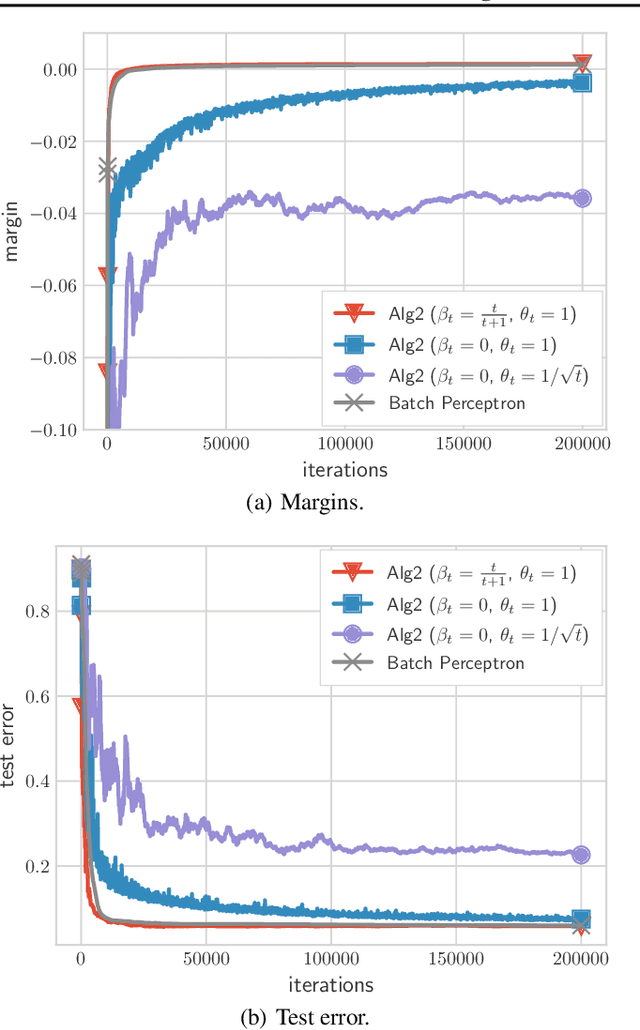
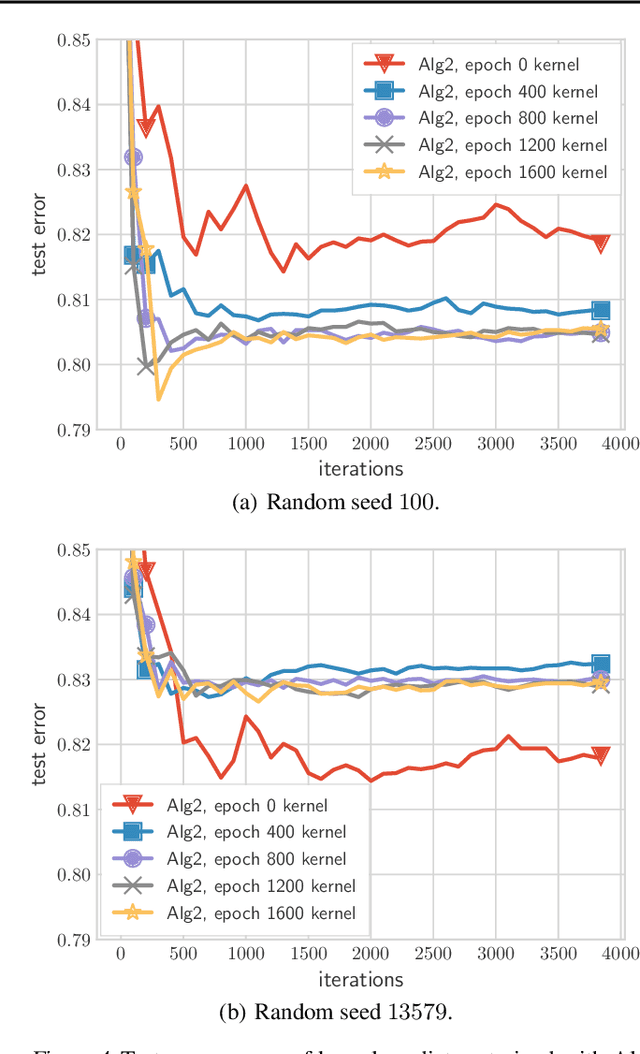
We present and analyze a momentum-based gradient method for training linear classifiers with an exponentially-tailed loss (e.g., the exponential or logistic loss), which maximizes the classification margin on separable data at a rate of $\widetilde{\mathcal{O}}(1/t^2)$. This contrasts with a rate of $\mathcal{O}(1/\log(t))$ for standard gradient descent, and $\mathcal{O}(1/t)$ for normalized gradient descent. This momentum-based method is derived via the convex dual of the maximum-margin problem, and specifically by applying Nesterov acceleration to this dual, which manages to result in a simple and intuitive method in the primal. This dual view can also be used to derive a stochastic variant, which performs adaptive non-uniform sampling via the dual variables.
Early-stopped neural networks are consistent
Jun 10, 2021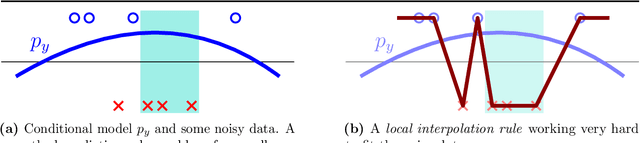
This work studies the behavior of neural networks trained with the logistic loss via gradient descent on binary classification data where the underlying data distribution is general, and the (optimal) Bayes risk is not necessarily zero. In this setting, it is shown that gradient descent with early stopping achieves population risk arbitrarily close to optimal in terms of not just logistic and misclassification losses, but also in terms of calibration, meaning the sigmoid mapping of its outputs approximates the true underlying conditional distribution arbitrarily finely. Moreover, the necessary iteration, sample, and architectural complexities of this analysis all scale naturally with a certain complexity measure of the true conditional model. Lastly, while it is not shown that early stopping is necessary, it is shown that any univariate classifier satisfying a local interpolation property is necessarily inconsistent.