 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Generative Data-Free Distillation
Dec 10, 2020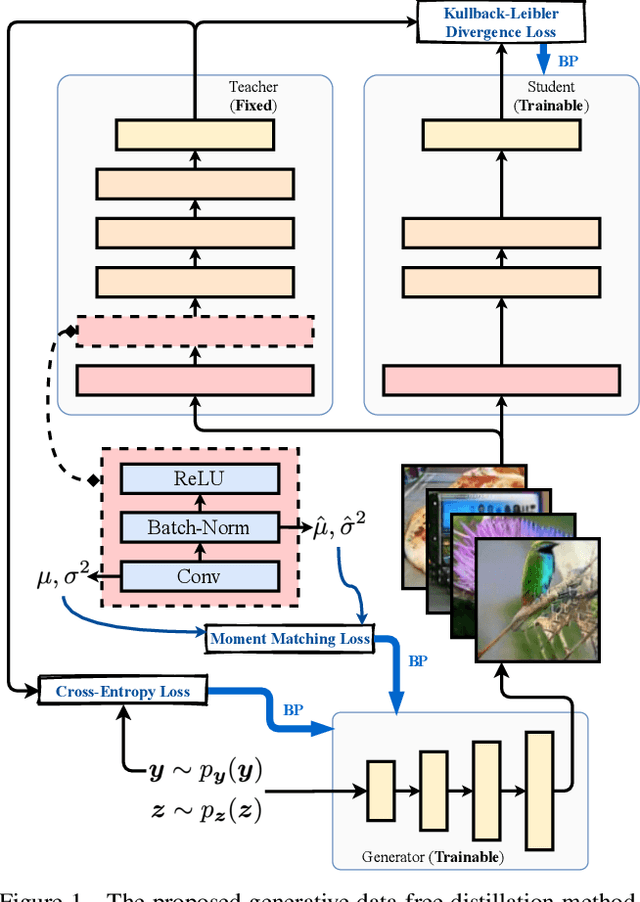
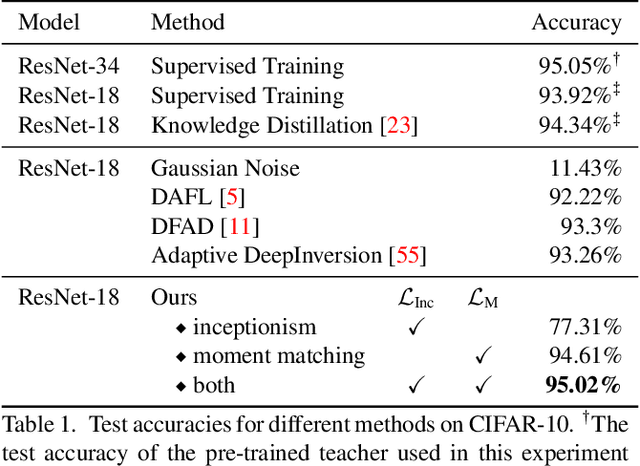

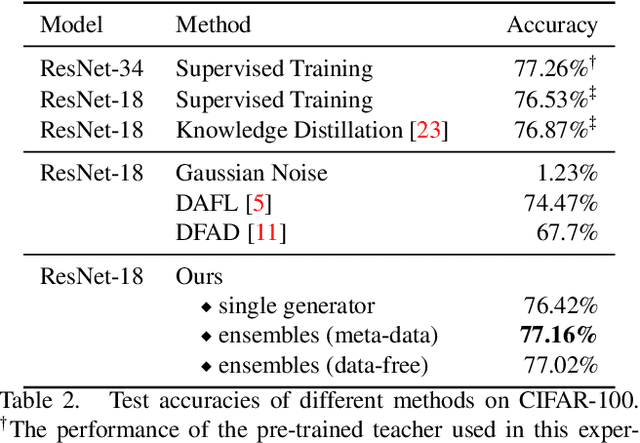
Knowledge distillation is one of the most popular and effective techniques for knowledge transfer, model compression and semi-supervised learning. Most existing distillation approaches require the access to original or augmented training samples. But this can be problematic in practice due to privacy, proprietary and availability concerns. Recent work has put forward some methods to tackle this problem, but they are either highly time-consuming or unable to scale to large datasets. To this end, we propose a new method to train a generative image model by leveraging the intrinsic normalization layers' statistics of the trained teacher network. This enables us to build an ensemble of generators without training data that can efficiently produce substitute inputs for subsequent distillation. The proposed method pushes forward the data-free distillation performance on CIFAR-10 and CIFAR-100 to 95.02% and 77.02% respectively. Furthermore, we are able to scale it to ImageNet dataset, which to the best of our knowledge, has never been done using generative models in a data-free setting.
Pruning Redundant Mappings in Transformer Models via Spectral-Normalized Identity Prior
Oct 05, 2020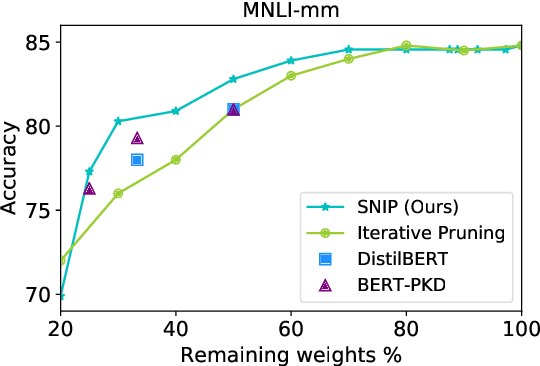
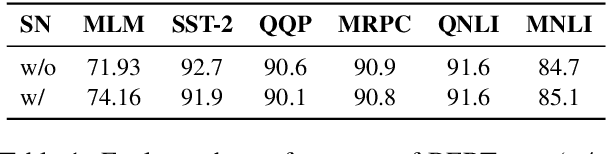
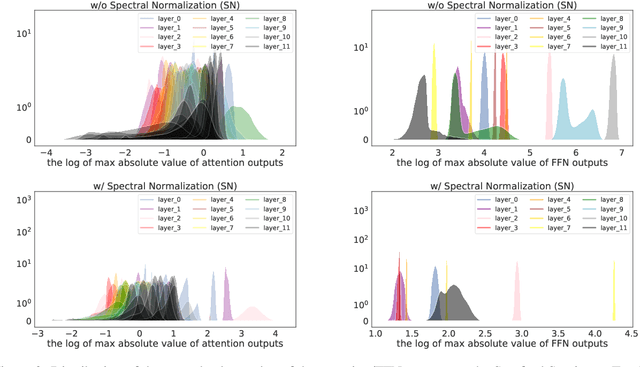
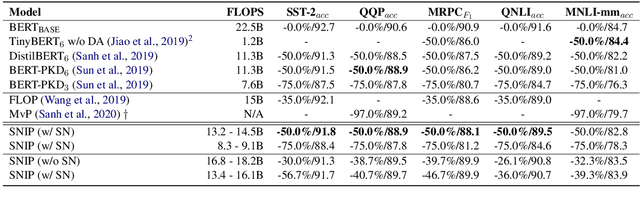
Traditional (unstructured) pruning methods for a Transformer model focus on regularizing the individual weights by penalizing them toward zero. In this work, we explore spectral-normalized identity priors (SNIP), a structured pruning approach that penalizes an entire residual module in a Transformer model toward an identity mapping. Our method identifies and discards unimportant non-linear mappings in the residual connections by applying a thresholding operator on the function norm. It is applicable to any structured module, including a single attention head, an entire attention block, or a feed-forward subnetwork. Furthermore, we introduce spectral normalization to stabilize the distribution of the post-activation values of the Transformer layers, further improving the pruning effectiveness of the proposed methodology. We conduct experiments with BERT on 5 GLUE benchmark tasks to demonstrate that SNIP achieves effective pruning results while maintaining comparable performance. Specifically, we improve the performance over the state-of-the-art by 0.5 to 1.0% on average at 50% compression ratio.
Simple and Principled Uncertainty Estimation with Deterministic Deep Learning via Distance Awareness
Jun 17, 2020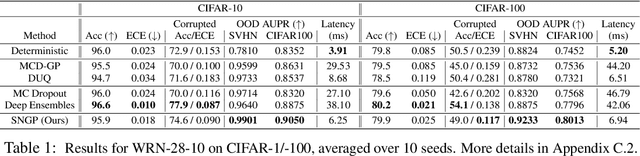
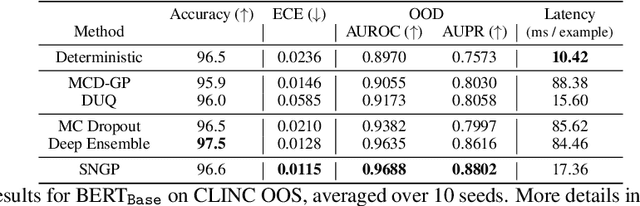
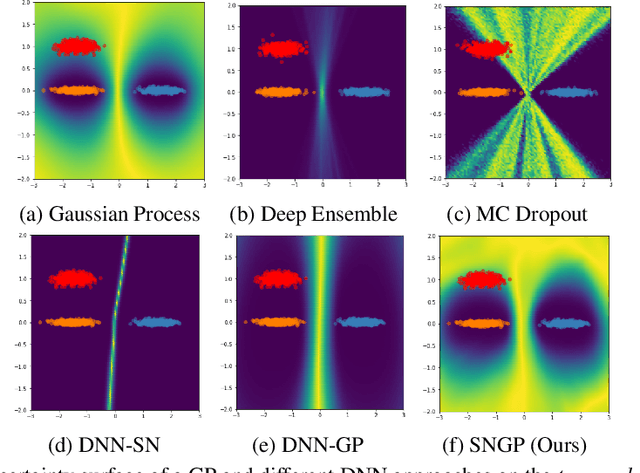
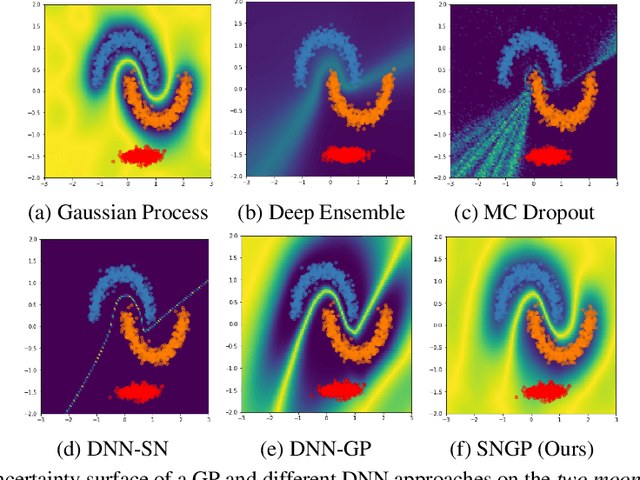
Bayesian neural networks (BNN) and deep ensembles are principled approaches to estimate the predictive uncertainty of a deep learning model. However their practicality in real-time, industrial-scale applications are limited due to their heavy memory and inference cost. This motivates us to study principled approaches to high-quality uncertainty estimation that require only a single deep neural network (DNN). By formalizing the uncertainty quantification as a minimax learning problem, we first identify input distance awareness, i.e., the model's ability to quantify the distance of a testing example from the training data in the input space, as a necessary condition for a DNN to achieve high-quality (i.e., minimax optimal) uncertainty estimation. We then propose Spectral-normalized Neural Gaussian Process (SNGP), a simple method that improves the distance-awareness ability of modern DNNs, by adding a weight normalization step during training and replacing the output layer with a Gaussian process. On a suite of vision and language understanding tasks and on modern architectures (Wide-ResNet and BERT), SNGP is competitive with deep ensembles in prediction, calibration and out-of-domain detection, and outperforms the other single-model approaches.
Fast Structured Decoding for Sequence Models
Oct 25, 2019
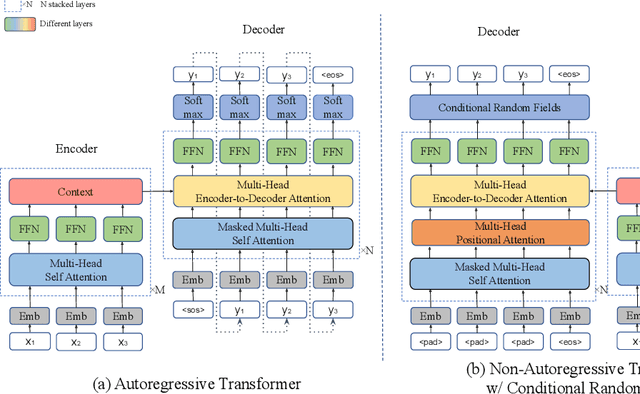
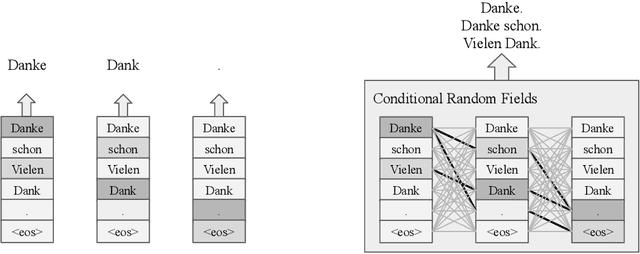
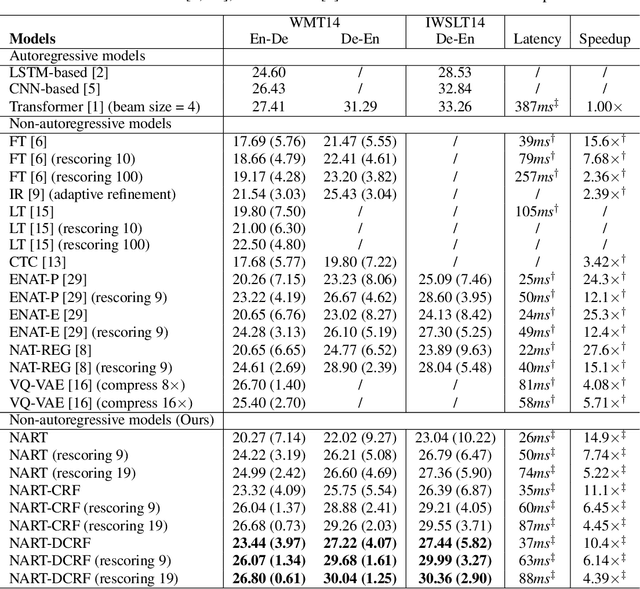
Autoregressive sequence models achieve state-of-the-art performance in domains like machine translation. However, due to the autoregressive factorization nature, these models suffer from heavy latency during inference. Recently, non-autoregressive sequence models were proposed to speed up the inference time. However, these models assume that the decoding process of each token is conditionally independent of others. Such a generation process sometimes makes the output sentence inconsistent, and thus the learned non-autoregressive models could only achieve inferior accuracy compared to their autoregressive counterparts. To improve then decoding consistency and reduce the inference cost at the same time, we propose to incorporate a structured inference module into the non-autoregressive models. Specifically, we design an efficient approximation for Conditional Random Fields (CRF) for non-autoregressive sequence models, and further propose a dynamic transition technique to model positional contexts in the CRF. Experiments in machine translation show that while increasing little latency (8~14ms), our model could achieve significantly better translation performance than previous non-autoregressive models on different translation datasets. In particular, for the WMT14 En-De dataset, our model obtains a BLEU score of 26.80, which largely outperforms the previous non-autoregressive baselines and is only 0.61 lower in BLEU than purely autoregressive models.
Hint-Based Training for Non-Autoregressive Machine Translation
Sep 15, 2019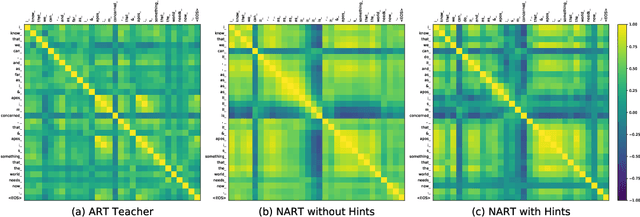
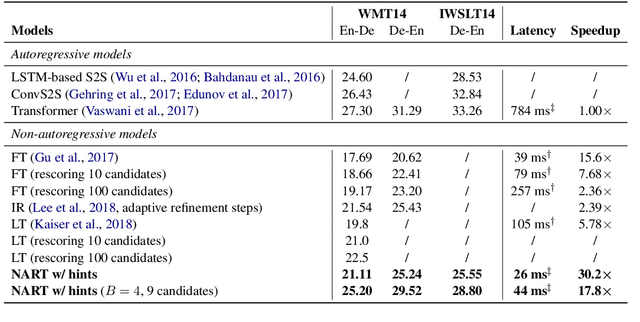
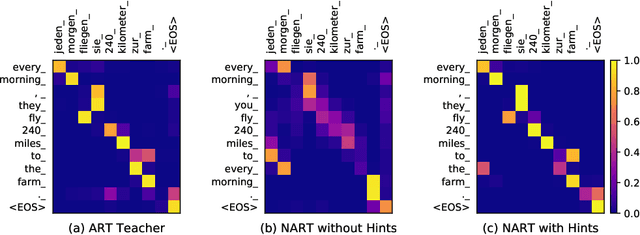
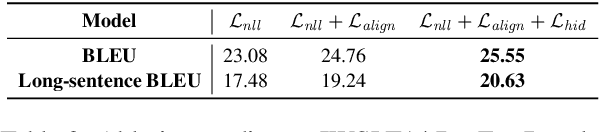
Due to the unparallelizable nature of the autoregressive factorization, AutoRegressive Translation (ART) models have to generate tokens sequentially during decoding and thus suffer from high inference latency. Non-AutoRegressive Translation (NART) models were proposed to reduce the inference time, but could only achieve inferior translation accuracy. In this paper, we proposed a novel approach to leveraging the hints from hidden states and word alignments to help the training of NART models. The results achieve significant improvement over previous NART models for the WMT14 En-De and De-En datasets and are even comparable to a strong LSTM-based ART baseline but one order of magnitude faster in inference.
A Comparative Analysis of Knowledge-Intensive and Data-Intensive Semantic Parsers
Aug 15, 2019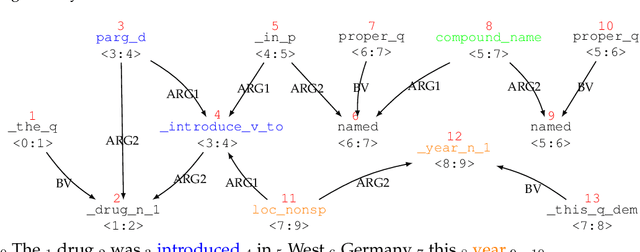
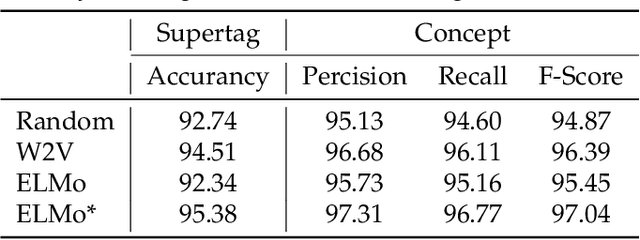
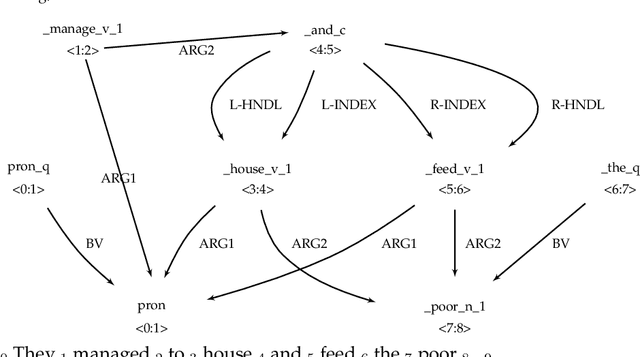
We present a phenomenon-oriented comparative analysis of the two dominant approaches in task-independent semantic parsing: classic, knowledge-intensive and neural, data-intensive models. To reflect state-of-the-art neural NLP technologies, we introduce a new target structure-centric parser that can produce semantic graphs much more accurately than previous data-driven parsers. We then show that, in spite of comparable performance overall, knowledge- and data-intensive models produce different types of errors, in a way that can be explained by their theoretical properties. This analysis leads to new directions for parser development.
Implanting Rational Knowledge into Distributed Representation at Morpheme Level
Nov 26, 2018
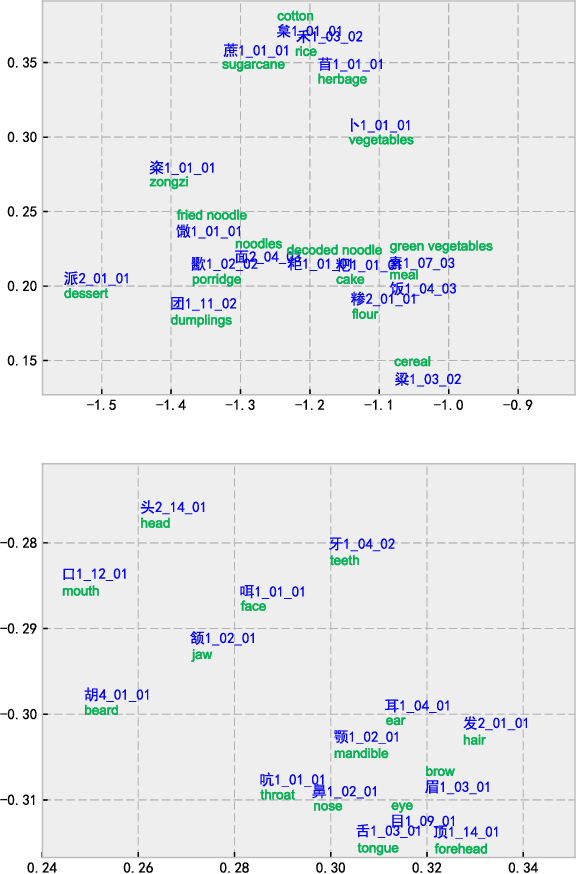
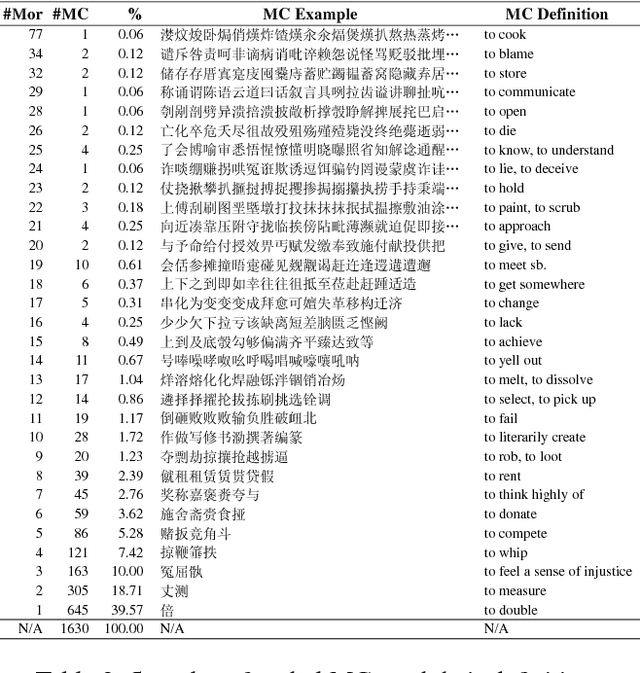
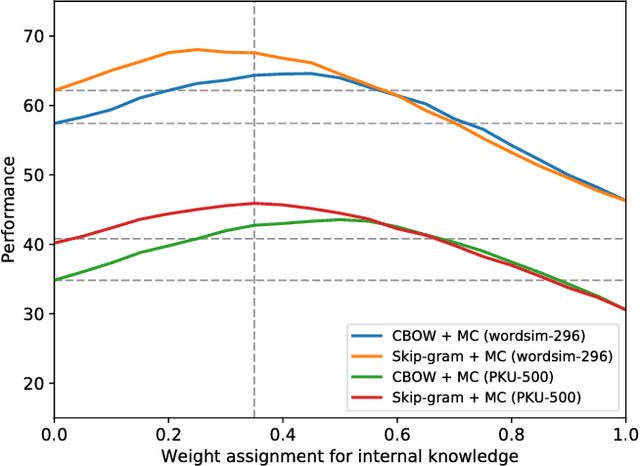
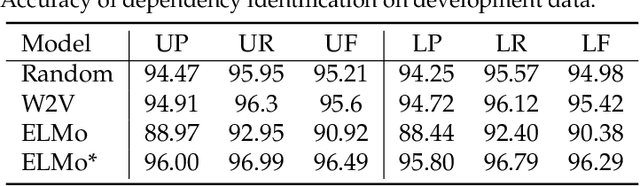
Previously, researchers paid no attention to the creation of unambiguous morpheme embeddings independent from the corpus, while such information plays an important role in expressing the exact meanings of words for parataxis languages like Chinese. In this paper, after constructing the Chinese lexical and semantic ontology based on word-formation, we propose a novel approach to implanting the structured rational knowledge into distributed representation at morpheme level, naturally avoiding heavy disambiguation in the corpus. We design a template to create the instances as pseudo-sentences merely from the pieces of knowledge of morphemes built in the lexicon. To exploit hierarchical information and tackle the data sparseness problem, the instance proliferation technique is applied based on similarity to expand the collection of pseudo-sentences. The distributed representation for morphemes can then be trained on these pseudo-sentences using word2vec. For evaluation, we validate the paradigmatic and syntagmatic relations of morpheme embeddings, and apply the obtained embeddings to word similarity measurement, achieving significant improvements over the classical models by more than 5 Spearman scores or 8 percentage points, which shows very promising prospects for adoption of the new source of knowledge.
Semantic Role Labeling for Learner Chinese: the Importance of Syntactic Parsing and L2-L1 Parallel Data
Aug 29, 2018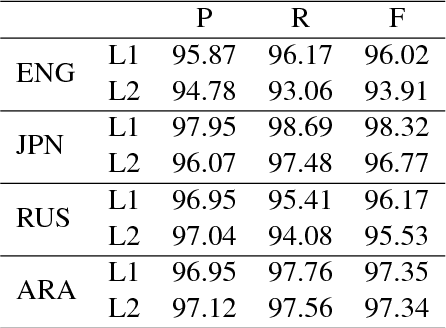
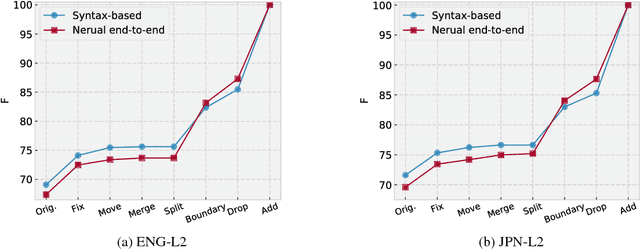
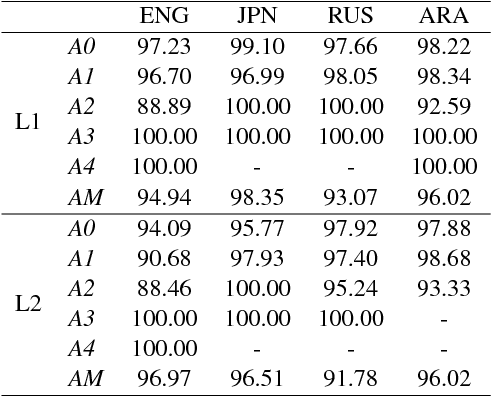

This paper studies semantic parsing for interlanguage (L2), taking semantic role labeling (SRL) as a case task and learner Chinese as a case language. We first manually annotate the semantic roles for a set of learner texts to derive a gold standard for automatic SRL. Based on the new data, we then evaluate three off-the-shelf SRL systems, i.e., the PCFGLA-parser-based, neural-parser-based and neural-syntax-agnostic systems, to gauge how successful SRL for learner Chinese can be. We find two non-obvious facts: 1) the L1-sentence-trained systems performs rather badly on the L2 data; 2) the performance drop from the L1 data to the L2 data of the two parser-based systems is much smaller, indicating the importance of syntactic parsing in SRL for interlanguages. Finally, the paper introduces a new agreement-based model to explore the semantic coherency information in the large-scale L2-L1 parallel data. We then show such information is very effective to enhance SRL for learner texts. Our model achieves an F-score of 72.06, which is a 2.02 point improvement over the best baseline.