 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUR-adapter: Enhancing Text-to-Image Pre-trained Diffusion Models with Large Language Models
May 12, 2023



Diffusion models, which have emerged to become popular text-to-image generation models, can produce high-quality and content-rich images guided by textual prompts. However, there are limitations to semantic understanding and commonsense reasoning in existing models when the input prompts are concise narrative, resulting in low-quality image generation. To improve the capacities for narrative prompts, we propose a simple-yet-effective parameter-efficient fine-tuning approach called the Semantic Understanding and Reasoning adapter (SUR-adapter) for pre-trained diffusion models. To reach this goal, we first collect and annotate a new dataset SURD which consists of more than 57,000 semantically corrected multi-modal samples. Each sample contains a simple narrative prompt, a complex keyword-based prompt, and a high-quality image. Then, we align the semantic representation of narrative prompts to the complex prompts and transfer knowledge of large language models (LLMs) to our SUR-adapter via knowledge distillation so that it can acquire the powerful semantic understanding and reasoning capabilities to build a high-quality textual semantic representation for text-to-image generation. We conduct experiments by integrating multiple LLMs and popular pre-trained diffusion models to show the effectiveness of our approach in enabling diffusion models to understand and reason concise natural language without image quality degradation. Our approach can make text-to-image diffusion models easier to use with better user experience, which demonstrates our approach has the potential for further advancing the development of user-friendly text-to-image generation models by bridging the semantic gap between simple narrative prompts and complex keyword-based prompts. The code is released at https://github.com/Qrange-group/SUR-adapter.
LSAS: Lightweight Sub-attention Strategy for Alleviating Attention Bias Problem
May 09, 2023



In computer vision, the performance of deep neural networks (DNNs) is highly related to the feature extraction ability, i.e., the ability to recognize and focus on key pixel regions in an image. However, in this paper, we quantitatively and statistically illustrate that DNNs have a serious attention bias problem on many samples from some popular datasets: (1) Position bias: DNNs fully focus on label-independent regions; (2) Range bias: The focused regions from DNN are not completely contained in the ideal region. Moreover, we find that the existing self-attention modules can alleviate these biases to a certain extent, but the biases are still non-negligible. To further mitigate them, we propose a lightweight sub-attention strategy (LSAS), which utilizes high-order sub-attention modules to improve the original self-attention modules. The effectiveness of LSAS is demonstrated by extensive experiments on widely-used benchmark datasets and popular attention networks. We release our code to help other researchers to reproduce the results of LSAS~\footnote{https://github.com/Qrange-group/LSAS}.
ASR: Attention-alike Structural Re-parameterization
Apr 13, 2023



The structural re-parameterization (SRP) technique is a novel deep learning technique that achieves interconversion between different network architectures through equivalent parameter transformations. This technique enables the mitigation of the extra costs for performance improvement during training, such as parameter size and inference time, through these transformations during inference, and therefore SRP has great potential for industrial and practical applications. The existing SRP methods have successfully considered many commonly used architectures, such as normalizations, pooling methods, multi-branch convolution. However, the widely used self-attention modules cannot be directly implemented by SRP due to these modules usually act on the backbone network in a multiplicative manner and the modules' output is input-dependent during inference, which limits the application scenarios of SRP. In this paper, we conduct extensive experiments from a statistical perspective and discover an interesting phenomenon Stripe Observation, which reveals that channel attention values quickly approach some constant vectors during training. This observation inspires us to propose a simple-yet-effective attention-alike structural re-parameterization (ASR) that allows us to achieve SRP for a given network while enjoying the effectiveness of the self-attention mechanism. Extensive experiments conducted on several standard benchmarks demonstrate the effectiveness of ASR in generally improving the performance of existing backbone networks, self-attention modules, and SRP methods without any elaborated model crafting. We also analyze the limitations and provide experimental or theoretical evidence for the strong robustness of the proposed ASR.
On Robust Numerical Solver for ODE via Self-Attention Mechanism
Feb 05, 2023With the development of deep learning techniques, AI-enhanced numerical solvers are expected to become a new paradigm for solving differential equations due to their versatility and effectiveness in alleviating the accuracy-speed trade-off in traditional numerical solvers. However, this paradigm still inevitably requires a large amount of high-quality data, whose acquisition is often very expensive in natural science and engineering problems. Therefore, in this paper, we explore training efficient and robust AI-enhanced numerical solvers with a small data size by mitigating intrinsic noise disturbances. We first analyze the ability of the self-attention mechanism to regulate noise in supervised learning and then propose a simple-yet-effective numerical solver, AttSolver, which introduces an additive self-attention mechanism to the numerical solution of differential equations based on the dynamical system perspective of the residual neural network. Our results on benchmarks, ranging from high-dimensional problems to chaotic systems, demonstrate the effectiveness of AttSolver in generally improving the performance of existing traditional numerical solvers without any elaborated model crafting. Finally, we analyze the convergence, generalization, and robustness of the proposed method experimentally and theoretically.
Deepening Neural Networks Implicitly and Locally via Recurrent Attention Strategy
Oct 27, 2022



More and more empirical and theoretical evidence shows that deepening neural networks can effectively improve their performance under suitable training settings. However, deepening the backbone of neural networks will inevitably and significantly increase computation and parameter size. To mitigate these problems, we propose a simple-yet-effective Recurrent Attention Strategy (RAS), which implicitly increases the depth of neural networks with lightweight attention modules by local parameter sharing. The extensive experiments on three widely-used benchmark datasets demonstrate that RAS can improve the performance of neural networks at a slight addition of parameter size and computation, performing favorably against other existing well-known attention modules.
Layer-wise Shared Attention Network on Dynamical System Perspective
Oct 27, 2022



Attention networks have successfully boosted accuracy in various vision problems. Previous works lay emphasis on designing a new self-attention module and follow the traditional paradigm that individually plugs the modules into each layer of a network. However, such a paradigm inevitably increases the extra parameter cost with the growth of the number of layers. From the dynamical system perspective of the residual neural network, we find that the feature maps from the layers of the same stage are homogenous, which inspires us to propose a novel-and-simple framework, called the dense and implicit attention (DIA) unit, that shares a single attention module throughout different network layers. With our framework, the parameter cost is independent of the number of layers and we further improve the accuracy of existing popular self-attention modules with significant parameter reduction without any elaborated model crafting. Extensive experiments on benchmark datasets show that the DIA is capable of emphasizing layer-wise feature interrelation and thus leads to significant improvement in various vision tasks, including image classification, object detection, and medical application. Furthermore, the effectiveness of the DIA unit is demonstrated by novel experiments where we destabilize the model training by (1) removing the skip connection of the residual neural network, (2) removing the batch normalization of the model, and (3) removing all data augmentation during training. In these cases, we verify that DIA has a strong regularization ability to stabilize the training, i.e., the dense and implicit connections formed by our method can effectively recover and enhance the information communication across layers and the value of the gradient thus alleviate the training instability.
Causal Inference for Chatting Handoff
Oct 06, 2022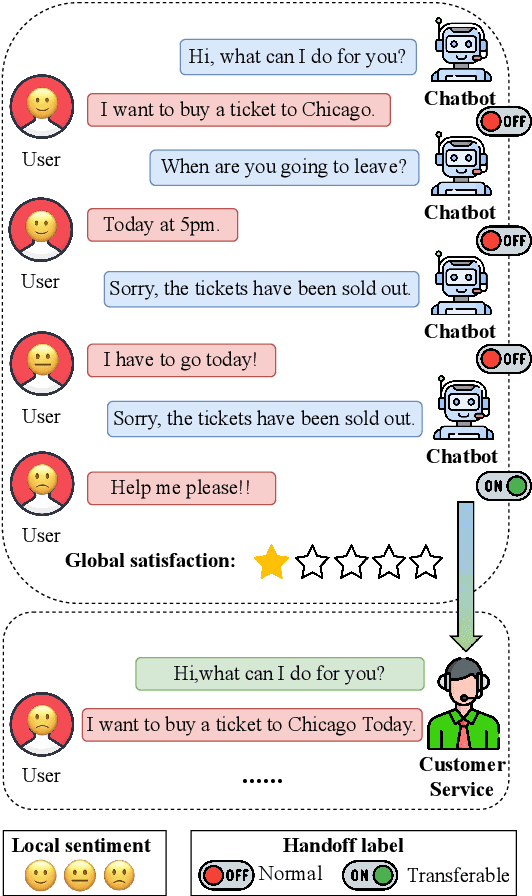
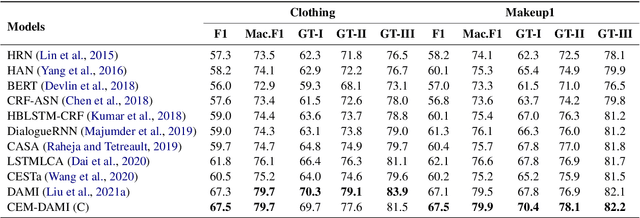
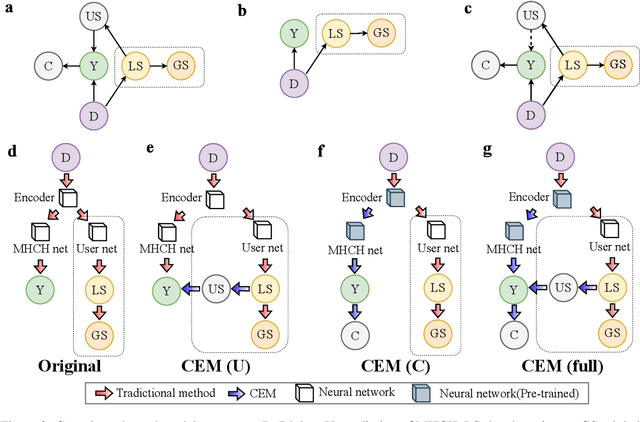
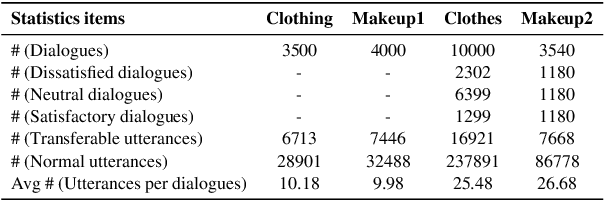
Aiming to ensure chatbot quality by predicting chatbot failure and enabling human-agent collaboration, Machine-Human Chatting Handoff (MHCH) has attracted lots of attention from both industry and academia in recent years. However, most existing methods mainly focus on the dialogue context or assist with global satisfaction prediction based on multi-task learning, which ignore the grounded relationships among the causal variables, like the user state and labor cost. These variables are significantly associated with handoff decisions, resulting in prediction bias and cost increasement. Therefore, we propose Causal-Enhance Module (CEM) by establishing the causal graph of MHCH based on these two variables, which is a simple yet effective module and can be easy to plug into the existing MHCH methods. For the impact of users, we use the user state to correct the prediction bias according to the causal relationship of multi-task. For the labor cost, we train an auxiliary cost simulator to calculate unbiased labor cost through counterfactual learning so that a model becomes cost-aware. Extensive experiments conducted on four real-world benchmarks demonstrate the effectiveness of CEM in generally improving the performance of existing MHCH methods without any elaborated model crafting.
Accelerating Numerical Solvers for Large-Scale Simulation of Dynamical System via NeurVec
Aug 07, 2022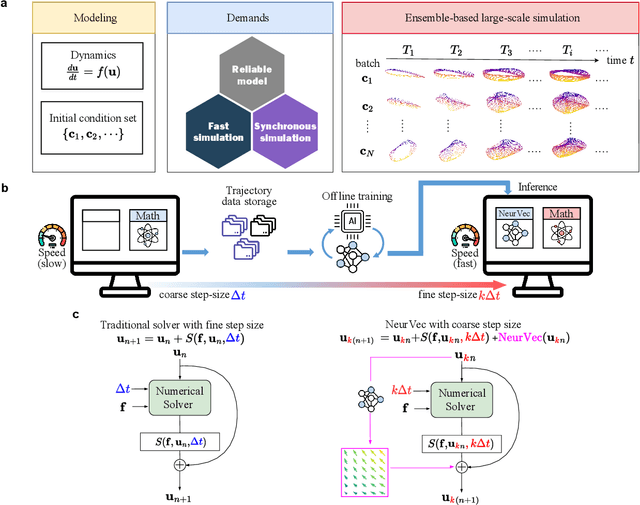

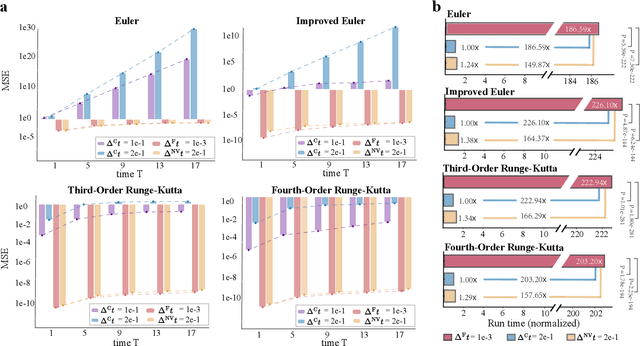
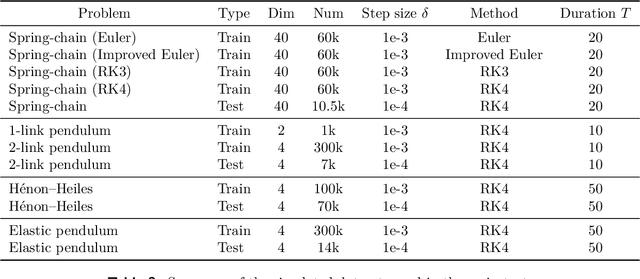
Ensemble-based large-scale simulation of dynamical systems is essential to a wide range of science and engineering problems. Conventional numerical solvers used in the simulation are significantly limited by the step size for time integration, which hampers efficiency and feasibility especially when high accuracy is desired. To overcome this limitation, we propose a data-driven corrector method that allows using large step sizes while compensating for the integration error for high accuracy. This corrector is represented in the form of a vector-valued function and is modeled by a neural network to regress the error in the phase space. Hence we name the corrector neural vector (NeurVec). We show that NeurVec can achieve the same accuracy as traditional solvers with much larger step sizes. We empirically demonstrate that NeurVec can accelerate a variety of numerical solvers significantly and overcome the stability restriction of these solvers. Our results on benchmark problems, ranging from high-dimensional problems to chaotic systems, suggest that NeurVec is capable of capturing the leading error term and maintaining the statistics of ensemble forecasts.
The Lottery Ticket Hypothesis for Self-attention in Convolutional Neural Network
Jul 16, 2022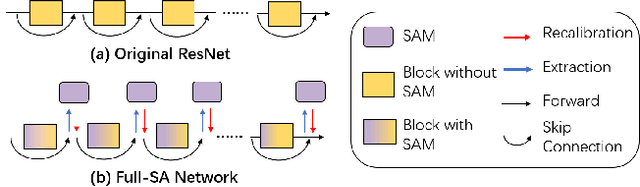
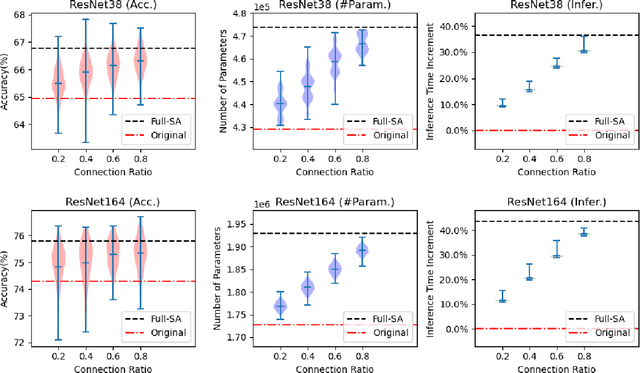
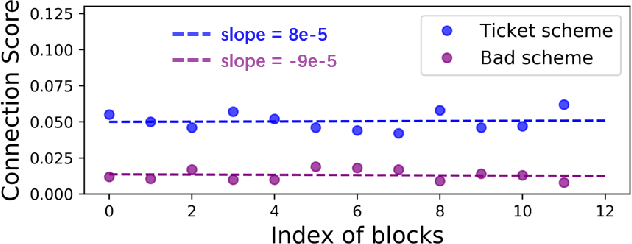
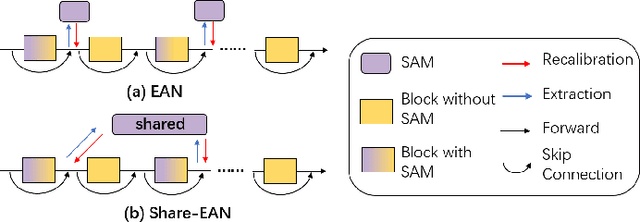
Recently many plug-and-play self-attention modules (SAMs) are proposed to enhance the model generalization by exploiting the internal information of deep convolutional neural networks (CNNs). In general, previous works ignore where to plug in the SAMs since they connect the SAMs individually with each block of the entire CNN backbone for granted, leading to incremental computational cost and the number of parameters with the growth of network depth. However, we empirically find and verify some counterintuitive phenomena that: (a) Connecting the SAMs to all the blocks may not always bring the largest performance boost, and connecting to partial blocks would be even better; (b) Adding the SAMs to a CNN may not always bring a performance boost, and instead it may even harm the performance of the original CNN backbone. Therefore, we articulate and demonstrate the Lottery Ticket Hypothesis for Self-attention Networks: a full self-attention network contains a subnetwork with sparse self-attention connections that can (1) accelerate inference, (2) reduce extra parameter increment, and (3) maintain accuracy. In addition to the empirical evidence, this hypothesis is also supported by our theoretical evidence. Furthermore, we propose a simple yet effective reinforcement-learning-based method to search the ticket, i.e., the connection scheme that satisfies the three above-mentioned conditions. Extensive experiments on widely-used benchmark datasets and popular self-attention networks show the effectiveness of our method. Besides, our experiments illustrate that our searched ticket has the capacity of transferring to some vision tasks, e.g., crowd counting and segmentation.
AlterSGD: Finding Flat Minima for Continual Learning by Alternative Training
Jul 13, 2021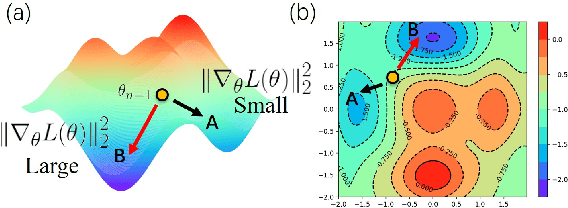
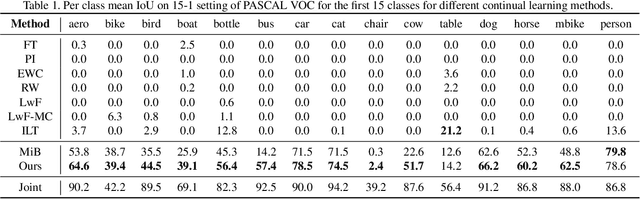
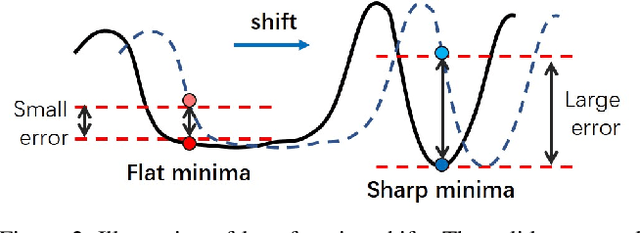
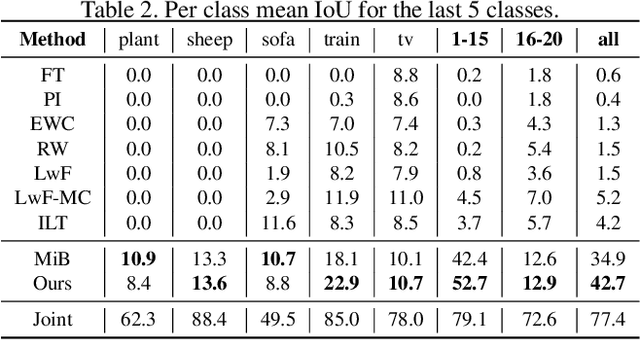
Deep neural networks suffer from catastrophic forgetting when learning multiple knowledge sequentially, and a growing number of approaches have been proposed to mitigate this problem. Some of these methods achieved considerable performance by associating the flat local minima with forgetting mitigation in continual learning. However, they inevitably need (1) tedious hyperparameters tuning, and (2) additional computational cost. To alleviate these problems, in this paper, we propose a simple yet effective optimization method, called AlterSGD, to search for a flat minima in the loss landscape. In AlterSGD, we conduct gradient descent and ascent alternatively when the network tends to converge at each session of learning new knowledge. Moreover, we theoretically prove that such a strategy can encourage the optimization to converge to a flat minima. We verify AlterSGD on continual learning benchmark for semantic segmentation and the empirical results show that we can significantly mitigate the forgetting and outperform the state-of-the-art methods with a large margin under challenging continual learning protocols.