 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Steps are Informative: On the Linearity of LLMs' RLVR Training
Jan 08, 2026Reinforcement learning with verifiable rewards (RLVR) has become a central component of large language model (LLM) post-training. Unlike supervised fine-tuning (SFT), RLVR lets an LLM generate multiple candidate solutions and reinforces those that lead to a verifiably correct final answer. However, in practice, RLVR often requires thousands of training steps to reach strong performance, incurring substantial computation largely attributed to prolonged exploration. In this work, we make a surprising observation: during RLVR, LLMs evolve in a strongly linear manner. Specifically, both model weights and model output log-probabilities exhibit strong linear correlations with RL training steps. This suggests that RLVR predominantly amplifies trends that emerge early in training, rather than continuously discovering new behaviors throughout the entire optimization trajectory. Motivated by this linearity, we investigate whether future model states can be predicted from intermediate checkpoints via extrapolation, avoiding continued expensive training. We show that Weight Extrapolation produces models with performance comparable to standard RL training while requiring significantly less computation. Moreover, Logits Extrapolation consistently outperforms continued RL training on all four benchmarks by extrapolating beyond the step range where RL training remains stable.
ReflectionCoder: Learning from Reflection Sequence for Enhanced One-off Code Generation
May 27, 2024



Code generation plays a crucial role in various tasks, such as code auto-completion and mathematical reasoning. Previous work has proposed numerous methods to enhance code generation performance, including integrating feedback from the compiler. Inspired by this, we present ReflectionCoder, a novel approach that effectively leverages reflection sequences constructed by integrating compiler feedback to improve one-off code generation performance. Furthermore, we propose reflection self-distillation and dynamically masked distillation to effectively utilize these reflection sequences. Extensive experiments on three benchmarks, i.e., HumanEval (+), MBPP (+), and MultiPl-E, demonstrate that models fine-tuned with our method achieve state-of-the-art performance. Notably, ReflectionCoder-DeepSeek-Coder-33B reaches pass@1 of 82.9 (76.8) on HumanEval (+) and 84.1 (72.0) on MBPP (+), on par with GPT-3.5-Turbo and Claude-3-opus, and surpasses early GPT-4. Beyond the code domain, we believe this approach can benefit other domains that focus on final results and require long reasoning paths. Code and data are available at https://github.com/SenseLLM/ReflectionCoder.
Empowering Character-level Text Infilling by Eliminating Sub-Tokens
May 27, 2024



In infilling tasks, sub-tokens, representing instances where a complete token is segmented into two parts, often emerge at the boundaries of prefixes, middles, and suffixes. Traditional methods focused on training models at the token level, leading to sub-optimal performance in character-level infilling tasks during the inference stage. Alternately, some approaches considered character-level infilling, but they relied on predicting sub-tokens in inference, yet this strategy diminished ability in character-level infilling tasks due to the large perplexity of the model on sub-tokens. In this paper, we introduce FIM-SE, which stands for Fill-In-the-Middle with both Starting and Ending character constraints. The proposed method addresses character-level infilling tasks by utilizing a line-level format to avoid predicting any sub-token in inference. In addition, we incorporate two special tokens to signify the rest of the incomplete lines, thereby enhancing generation guidance. Extensive experiments demonstrate that our proposed approach surpasses previous methods, offering a significant advantage. Code is available at https://github.com/SenseLLM/FIM-SE.
Hybrid attention network based on progressive embedding scale-context for crowd counting
Jun 04, 2021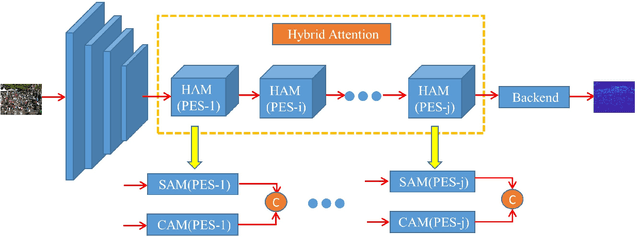
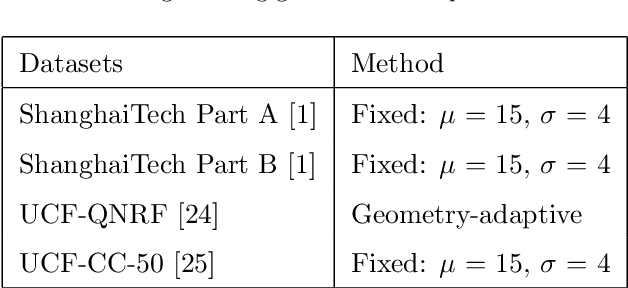
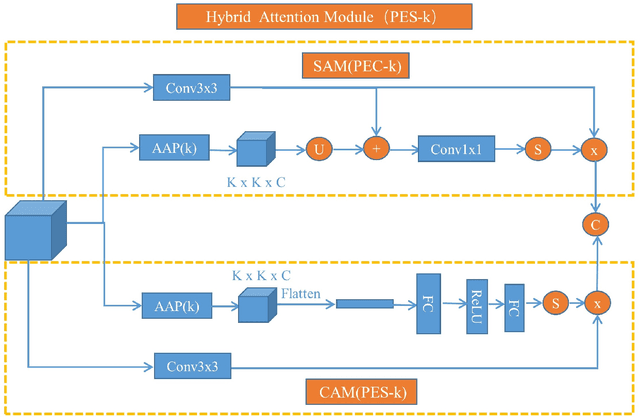
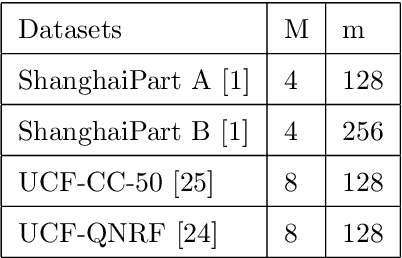
The existing crowd counting methods usually adopted attention mechanism to tackle background noise, or applied multi-level features or multi-scales context fusion to tackle scale variation. However, these approaches deal with these two problems separately. In this paper, we propose a Hybrid Attention Network (HAN) by employing Progressive Embedding Scale-context (PES) information, which enables the network to simultaneously suppress noise and adapt head scale variation. We build the hybrid attention mechanism through paralleling spatial attention and channel attention module, which makes the network to focus more on the human head area and reduce the interference of background objects. Besides, we embed certain scale-context to the hybrid attention along the spatial and channel dimensions for alleviating these counting errors caused by the variation of perspective and head scale. Finally, we propose a progressive learning strategy through cascading multiple hybrid attention modules with embedding different scale-context, which can gradually integrate different scale-context information into the current feature map from global to local. Ablation experiments provides that the network architecture can gradually learn multi-scale features and suppress background noise. Extensive experiments demonstrate that HANet obtain state-of-the-art counting performance on four mainstream datasets.
BigDL: A Distributed Deep Learning Framework for Big Data
Jun 25, 2018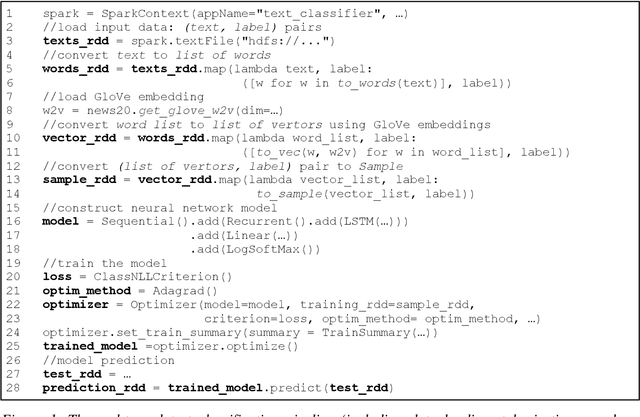
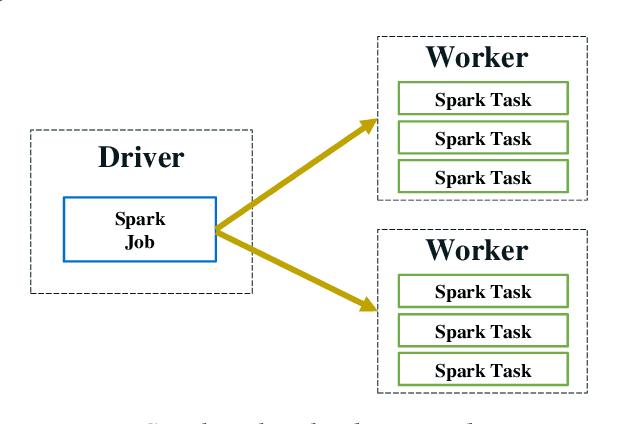

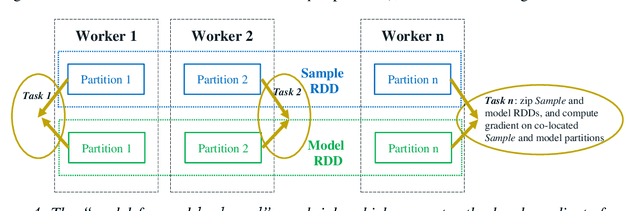
In this paper, we present BigDL, a distributed deep learning framework for Big Data platforms and workflows. It is implemented on top of Apache Spark, and allows users to write their deep learning applications as standard Spark programs (running directly on large-scale big data clusters in a distributed fashion). It provides an expressive, "data-analytics integrated" deep learning programming model, so that users can easily build the end-to-end analytics + AI pipelines under a unified programming paradigm; by implementing an AllReduce like operation using existing primitives in Spark (e.g., shuffle, broadcast, and in-memory data persistence), it also provides a highly efficient "parameter server" style architecture, so as to achieve highly scalable, data-parallel distributed training. Since its initial open source release, BigDL users have built many analytics and deep learning applications (e.g., object detection, sequence-to-sequence generation, visual similarity, neural recommendations, fraud detection, etc.) on Spark.