 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser
Mar 18, 2021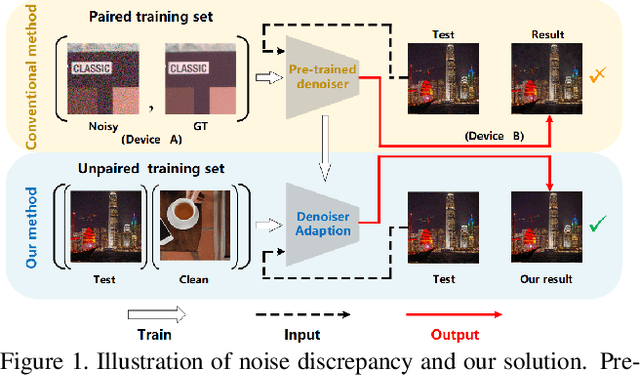
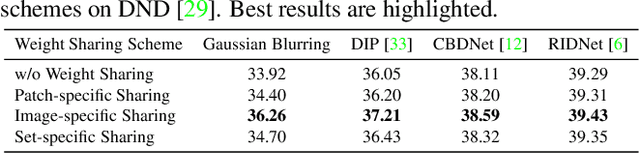
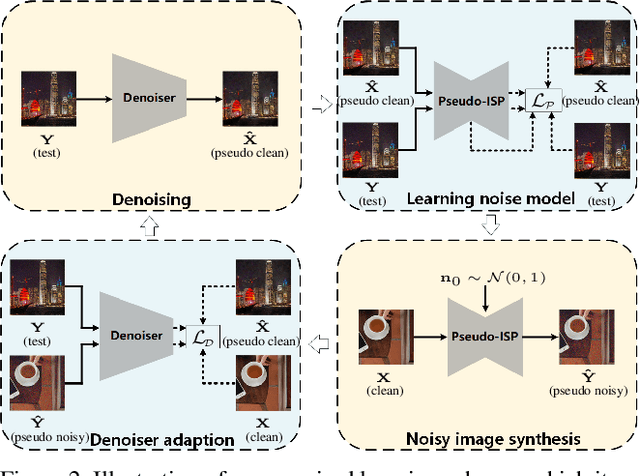
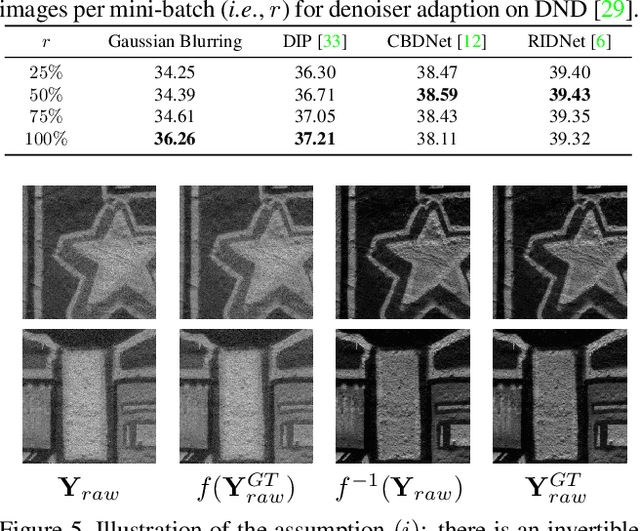
The success of deep denoisers on real-world color photographs usually relies on the modeling of sensor noise and in-camera signal processing (ISP) pipeline. Performance drop will inevitably happen when the sensor and ISP pipeline of test images are different from those for training the deep denoisers (i.e., noise discrepancy). In this paper, we present an unpaired learning scheme to adapt a color image denoiser for handling test images with noise discrepancy. We consider a practical training setting, i.e., a pre-trained denoiser, a set of test noisy images, and an unpaired set of clean images. To begin with, the pre-trained denoiser is used to generate the pseudo clean images for the test images. Pseudo-ISP is then suggested to jointly learn the pseudo ISP pipeline and signal-dependent rawRGB noise model using the pairs of test and pseudo clean images. We further apply the learned pseudo ISP and rawRGB noise model to clean color images to synthesize realistic noisy images for denoiser adaption. Pseudo-ISP is effective in synthesizing realistic noisy sRGB images, and improved denoising performance can be achieved by alternating between Pseudo-ISP training and denoiser adaption. Experiments show that our Pseudo-ISP not only can boost simple Gaussian blurring-based denoiser to achieve competitive performance against CBDNet, but also is effective in improving state-of-the-art deep denoisers, e.g., CBDNet and RIDNet.
AdvExpander: Generating Natural Language Adversarial Examples by Expanding Text
Dec 18, 2020
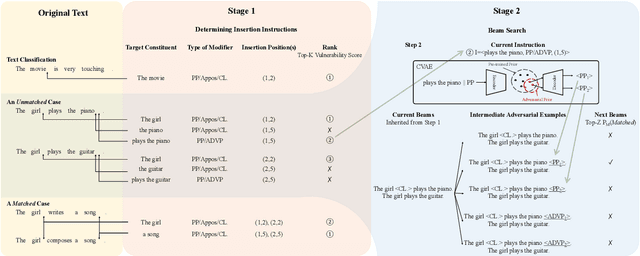
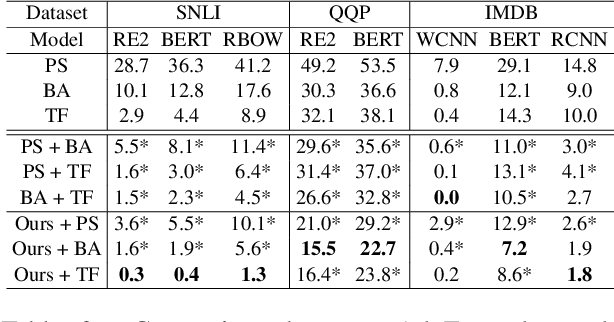
Adversarial examples are vital to expose the vulnerability of machine learning models. Despite the success of the most popular substitution-based methods which substitutes some characters or words in the original examples, only substitution is insufficient to uncover all robustness issues of models. In this paper, we present AdvExpander, a method that crafts new adversarial examples by expanding text, which is complementary to previous substitution-based methods. We first utilize linguistic rules to determine which constituents to expand and what types of modifiers to expand with. We then expand each constituent by inserting an adversarial modifier searched from a CVAE-based generative model which is pre-trained on a large scale corpus. To search adversarial modifiers, we directly search adversarial latent codes in the latent space without tuning the pre-trained parameters. To ensure that our adversarial examples are label-preserving for text matching, we also constrain the modifications with a heuristic rule. Experiments on three classification tasks verify the effectiveness of AdvExpander and the validity of our adversarial examples. AdvExpander crafts a new type of adversarial examples by text expansion, thereby promising to reveal new robustness issues.
Personalized Multimodal Feedback Generation in Education
Oct 31, 2020



The automatic evaluation for school assignments is an important application of AI in the education field. In this work, we focus on the task of personalized multimodal feedback generation, which aims to generate personalized feedback for various teachers to evaluate students' assignments involving multimodal inputs such as images, audios, and texts. This task involves the representation and fusion of multimodal information and natural language generation, which presents the challenges from three aspects: 1) how to encode and integrate multimodal inputs; 2) how to generate feedback specific to each modality; and 3) how to realize personalized feedback generation. In this paper, we propose a novel Personalized Multimodal Feedback Generation Network (PMFGN) armed with a modality gate mechanism and a personalized bias mechanism to address these challenges. The extensive experiments on real-world K-12 education data show that our model significantly outperforms several baselines by generating more accurate and diverse feedback. In addition, detailed ablation experiments are conducted to deepen our understanding of the proposed framework.
Mathematical Word Problem Generation from Commonsense Knowledge Graph and Equations
Oct 13, 2020
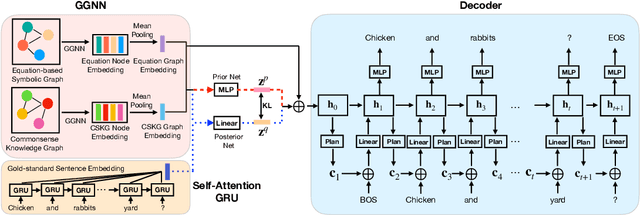
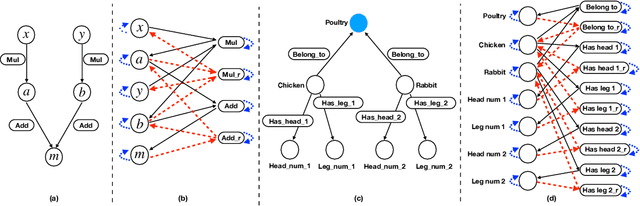
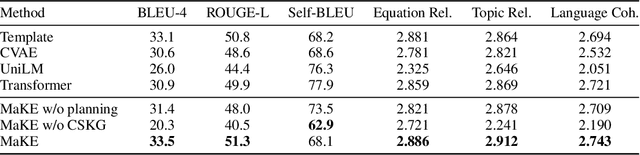
There is an increasing interest in the use of automatic mathematical word problem (MWP) generation in educational assessment. Different from standard natural question generation, MWP generation needs to maintain the underlying mathematical operations between quantities and variables, while at the same time ensuring the relevance between the output and the given topic. To address above problem we develop an end-to-end neural model to generate personalized and diverse MWPs in real-world scenarios from commonsense knowledge graph and equations. The proposed model (1) learns both representations from edge-enhanced Levi graphs of symbolic equations and commonsense knowledge; (2) automatically fuses equation and commonsense knowledge information via a self-planning module when generating the MWPs. Experiments on an educational gold-standard set and a large-scale generated MWP set show that our approach is superior on the MWP generation task, and it outperforms the state-of-the-art models in terms of both automatic evaluation metrics, i.e., BLEU-4, ROUGE-L, Self-BLEU, and human evaluation metrics, i.e, equation relevance, topic relevance, and language coherence.
TAL EmotioNet Challenge 2020 Rethinking the Model Chosen Problem in Multi-Task Learning
Apr 21, 2020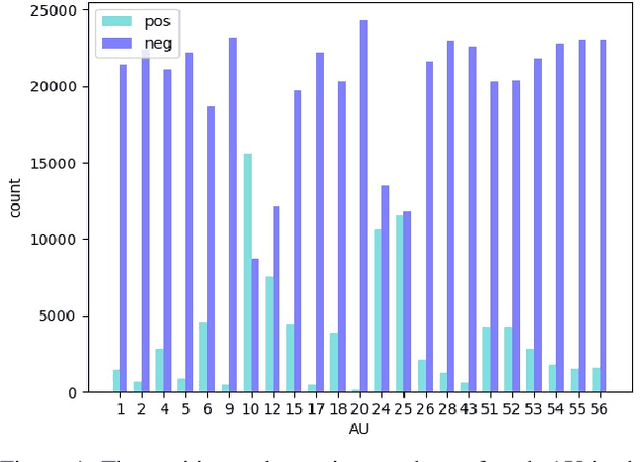
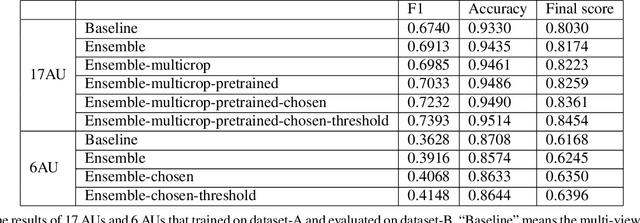
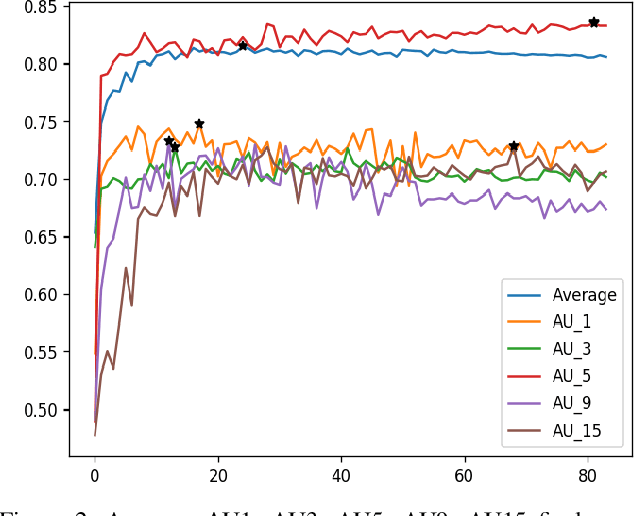
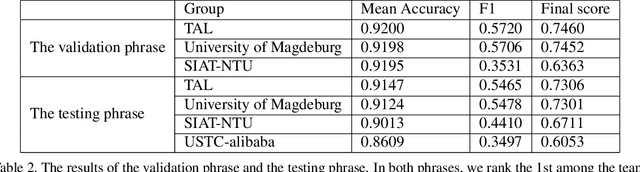
This paper introduces our approach to the EmotioNet Challenge 2020. We pose the AU recognition problem as a multi-task learning problem, where the non-rigid facial muscle motion (mainly the first 17 AUs) and the rigid head motion (the last 6 AUs) are modeled separately. The co-occurrence of the expression features and the head pose features are explored. We observe that different AUs converge at various speed. By choosing the optimal checkpoint for each AU, the recognition results are improved. We are able to obtain a final score of 0.746 in validation set and 0.7306 in the test set of the challenge.