 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Video-Text Retrieval with Explicit High-Level Semantics
Aug 09, 2022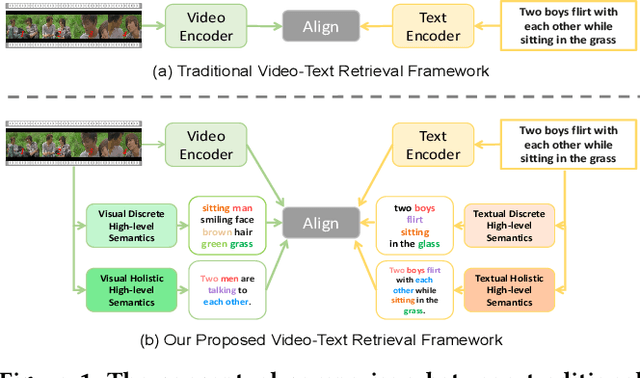
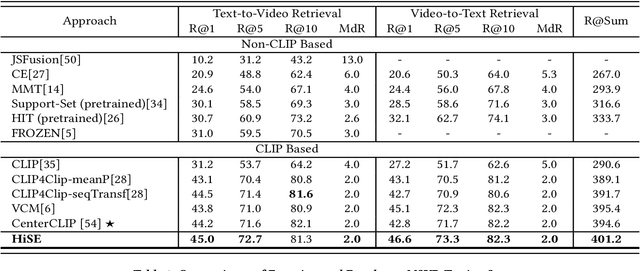
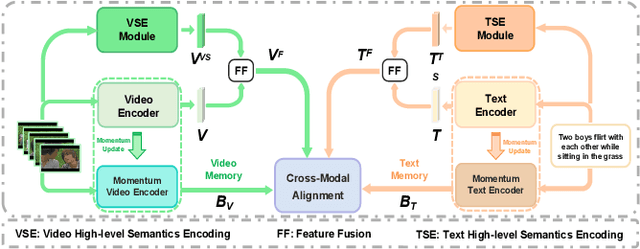
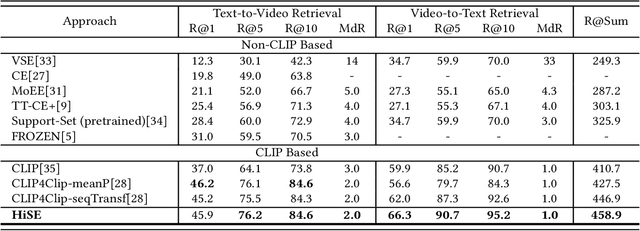
Video-text retrieval (VTR) is an attractive yet challenging task for multi-modal understanding, which aims to search for relevant video (text) given a query (video). Existing methods typically employ completely heterogeneous visual-textual information to align video and text, whilst lacking the awareness of homogeneous high-level semantic information residing in both modalities. To fill this gap, in this work, we propose a novel visual-linguistic aligning model named HiSE for VTR, which improves the cross-modal representation by incorporating explicit high-level semantics. First, we explore the hierarchical property of explicit high-level semantics, and further decompose it into two levels, i.e. discrete semantics and holistic semantics. Specifically, for visual branch, we exploit an off-the-shelf semantic entity predictor to generate discrete high-level semantics. In parallel, a trained video captioning model is employed to output holistic high-level semantics. As for the textual modality, we parse the text into three parts including occurrence, action and entity. In particular, the occurrence corresponds to the holistic high-level semantics, meanwhile both action and entity represent the discrete ones. Then, different graph reasoning techniques are utilized to promote the interaction between holistic and discrete high-level semantics. Extensive experiments demonstrate that, with the aid of explicit high-level semantics, our method achieves the superior performance over state-of-the-art methods on three benchmark datasets, including MSR-VTT, MSVD and DiDeMo.
Reinforced Pedestrian Attribute Recognition with Group Optimization Reward
May 21, 2022

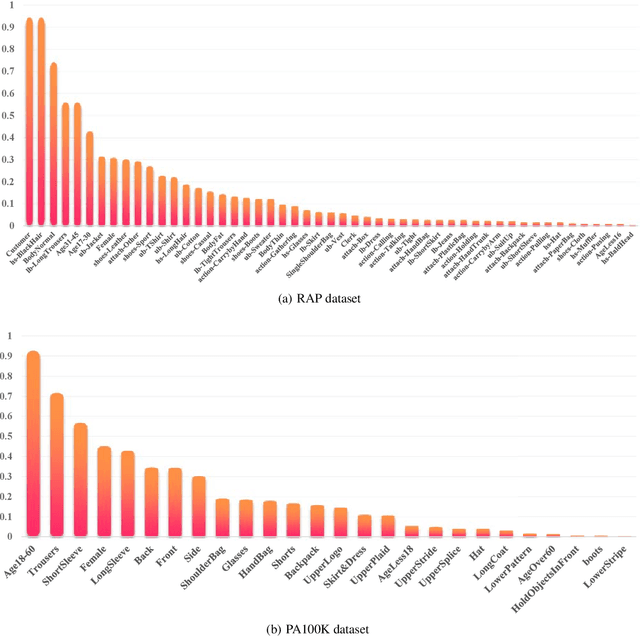

Pedestrian Attribute Recognition (PAR) is a challenging task in intelligent video surveillance. Two key challenges in PAR include complex alignment relations between images and attributes, and imbalanced data distribution. Existing approaches usually formulate PAR as a recognition task. Different from them, this paper addresses it as a decision-making task via a reinforcement learning framework. Specifically, PAR is formulated as a Markov decision process (MDP) by designing ingenious states, action space, reward function and state transition. To alleviate the inter-attribute imbalance problem, we apply an Attribute Grouping Strategy (AGS) by dividing all attributes into subgroups according to their region and category information. Then we employ an agent to recognize each group of attributes, which is trained with Deep Q-learning algorithm. We also propose a Group Optimization Reward (GOR) function to alleviate the intra-attribute imbalance problem. Experimental results on the three benchmark datasets of PETA, RAP and PA100K illustrate the effectiveness and competitiveness of the proposed approach and demonstrate that the application of reinforcement learning to PAR is a valuable research direction.
Complementary Calibration: Boosting General Continual Learning with Collaborative Distillation and Self-Supervision
Sep 03, 2021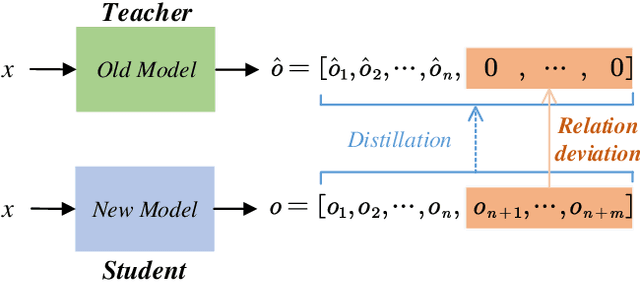
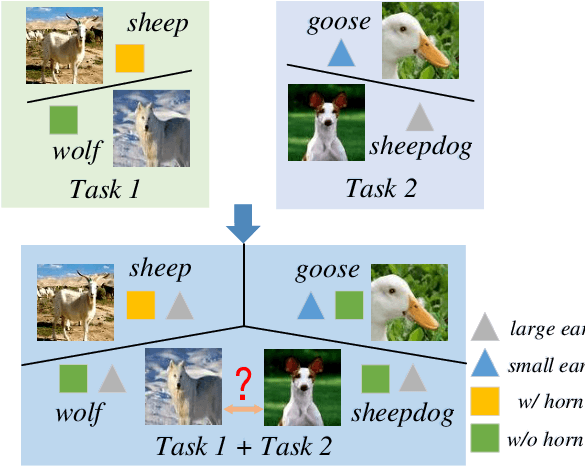
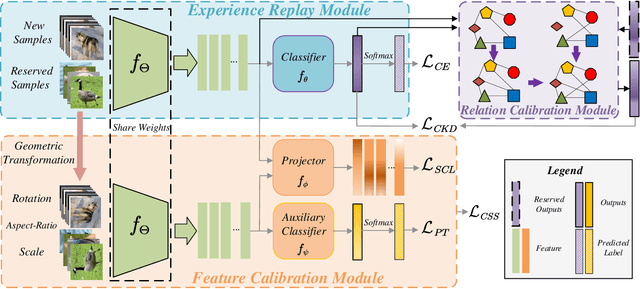
General Continual Learning (GCL) aims at learning from non independent and identically distributed stream data without catastrophic forgetting of the old tasks that don't rely on task boundaries during both training and testing stages. We reveal that the relation and feature deviations are crucial problems for catastrophic forgetting, in which relation deviation refers to the deficiency of the relationship among all classes in knowledge distillation, and feature deviation refers to indiscriminative feature representations. To this end, we propose a Complementary Calibration (CoCa) framework by mining the complementary model's outputs and features to alleviate the two deviations in the process of GCL. Specifically, we propose a new collaborative distillation approach for addressing the relation deviation. It distills model's outputs by utilizing ensemble dark knowledge of new model's outputs and reserved outputs, which maintains the performance of old tasks as well as balancing the relationship among all classes. Furthermore, we explore a collaborative self-supervision idea to leverage pretext tasks and supervised contrastive learning for addressing the feature deviation problem by learning complete and discriminative features for all classes. Extensive experiments on four popular datasets show that our CoCa framework achieves superior performance against state-of-the-art methods.
Self-Taught Cross-Domain Few-Shot Learning with Weakly Supervised Object Localization and Task-Decomposition
Sep 03, 2021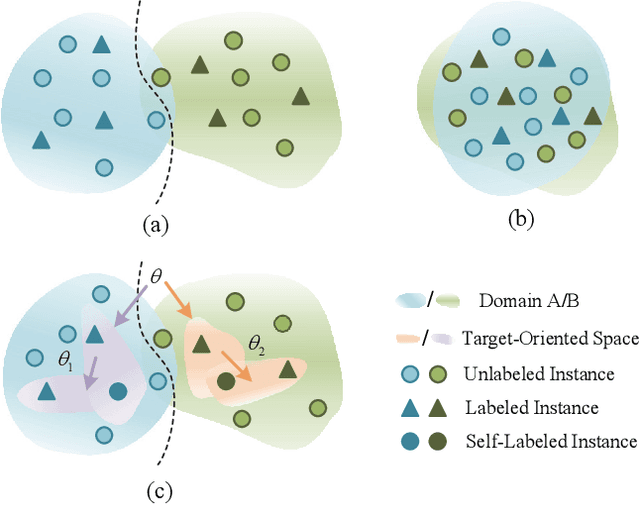

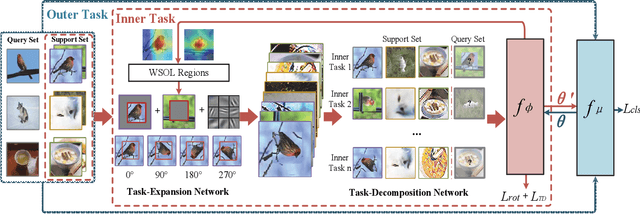
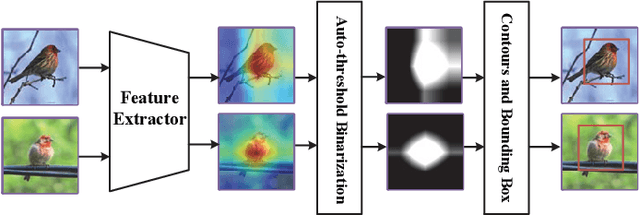
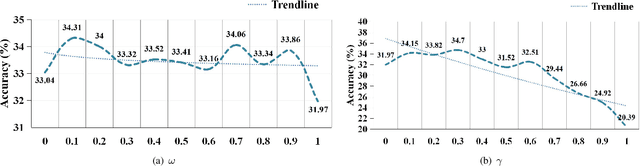
The domain shift between the source and target domain is the main challenge in Cross-Domain Few-Shot Learning (CD-FSL). However, the target domain is absolutely unknown during the training on the source domain, which results in lacking directed guidance for target tasks. We observe that since there are similar backgrounds in target domains, it can apply self-labeled samples as prior tasks to transfer knowledge onto target tasks. To this end, we propose a task-expansion-decomposition framework for CD-FSL, called Self-Taught (ST) approach, which alleviates the problem of non-target guidance by constructing task-oriented metric spaces. Specifically, Weakly Supervised Object Localization (WSOL) and self-supervised technologies are employed to enrich task-oriented samples by exchanging and rotating the discriminative regions, which generates a more abundant task set. Then these tasks are decomposed into several tasks to finish the task of few-shot recognition and rotation classification. It helps to transfer the source knowledge onto the target tasks and focus on discriminative regions. We conduct extensive experiments under the cross-domain setting including 8 target domains: CUB, Cars, Places, Plantae, CropDieases, EuroSAT, ISIC, and ChestX. Experimental results demonstrate that the proposed ST approach is applicable to various metric-based models, and provides promising improvements in CD-FSL.
Information Symmetry Matters: A Modal-Alternating Propagation Network for Few-Shot Learning
Sep 03, 2021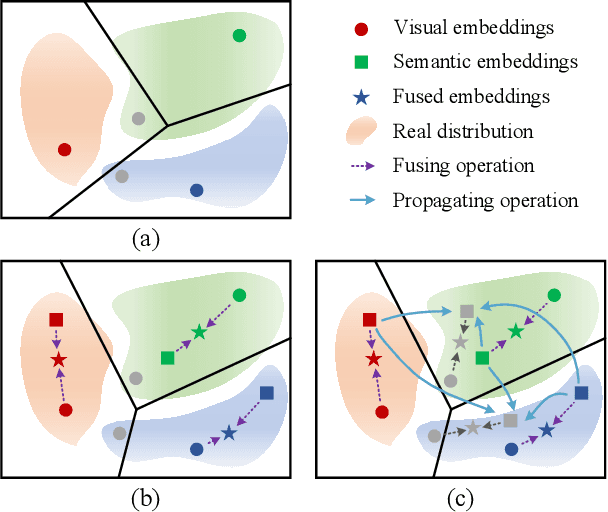
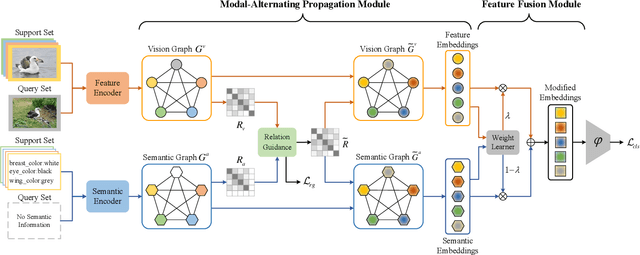
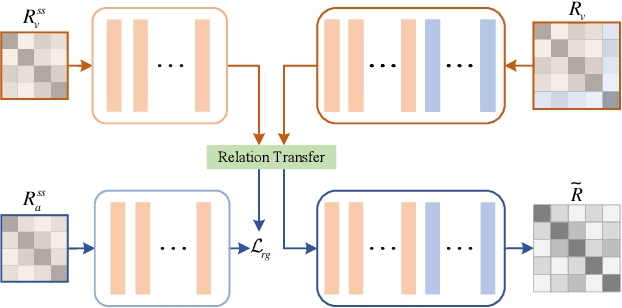
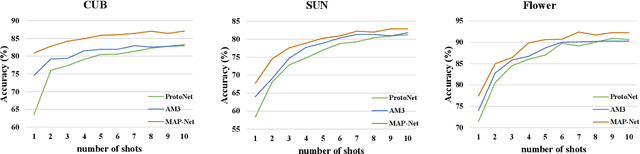
Semantic information provides intra-class consistency and inter-class discriminability beyond visual concepts, which has been employed in Few-Shot Learning (FSL) to achieve further gains. However, semantic information is only available for labeled samples but absent for unlabeled samples, in which the embeddings are rectified unilaterally by guiding the few labeled samples with semantics. Therefore, it is inevitable to bring a cross-modal bias between semantic-guided samples and nonsemantic-guided samples, which results in an information asymmetry problem. To address this problem, we propose a Modal-Alternating Propagation Network (MAP-Net) to supplement the absent semantic information of unlabeled samples, which builds information symmetry among all samples in both visual and semantic modalities. Specifically, the MAP-Net transfers the neighbor information by the graph propagation to generate the pseudo-semantics for unlabeled samples guided by the completed visual relationships and rectify the feature embeddings. In addition, due to the large discrepancy between visual and semantic modalities, we design a Relation Guidance (RG) strategy to guide the visual relation vectors via semantics so that the propagated information is more beneficial. Extensive experimental results on three semantic-labeled datasets, i.e., Caltech-UCSD-Birds 200-2011, SUN Attribute Database, and Oxford 102 Flower, have demonstrated that our proposed method achieves promising performance and outperforms the state-of-the-art approaches, which indicates the necessity of information symmetry.
Step-Wise Hierarchical Alignment Network for Image-Text Matching
Jun 11, 2021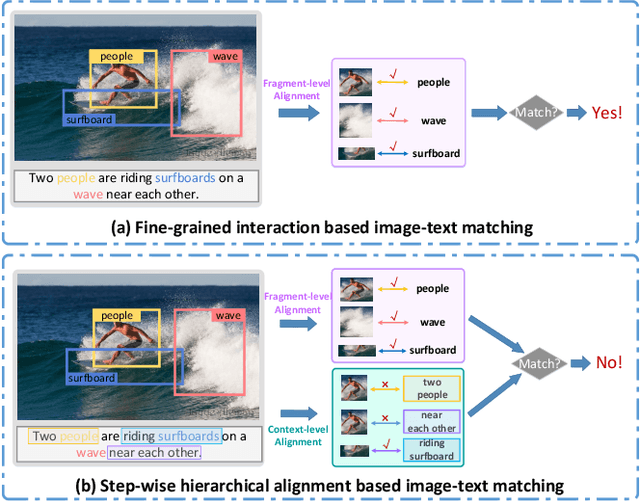
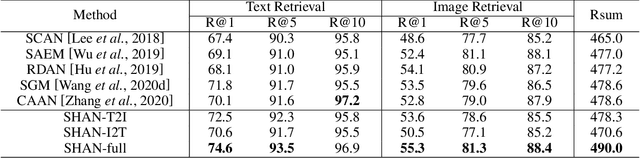
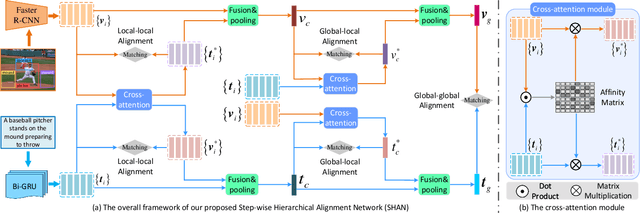
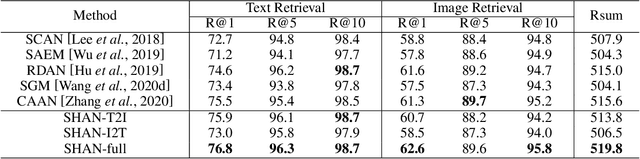
Image-text matching plays a central role in bridging the semantic gap between vision and language. The key point to achieve precise visual-semantic alignment lies in capturing the fine-grained cross-modal correspondence between image and text. Most previous methods rely on single-step reasoning to discover the visual-semantic interactions, which lacks the ability of exploiting the multi-level information to locate the hierarchical fine-grained relevance. Different from them, in this work, we propose a step-wise hierarchical alignment network (SHAN) that decomposes image-text matching into multi-step cross-modal reasoning process. Specifically, we first achieve local-to-local alignment at fragment level, following by performing global-to-local and global-to-global alignment at context level sequentially. This progressive alignment strategy supplies our model with more complementary and sufficient semantic clues to understand the hierarchical correlations between image and text. The experimental results on two benchmark datasets demonstrate the superiority of our proposed method.
Consensus-Aware Visual-Semantic Embedding for Image-Text Matching
Jul 17, 2020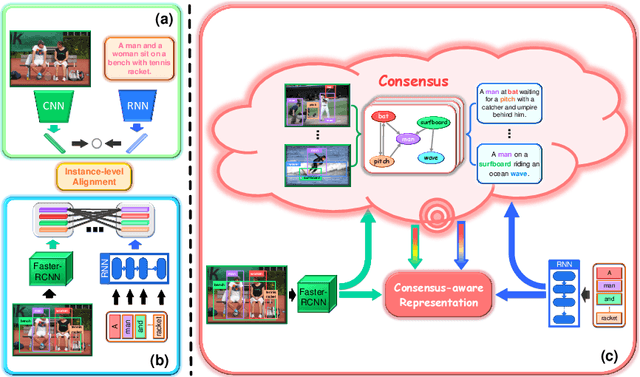
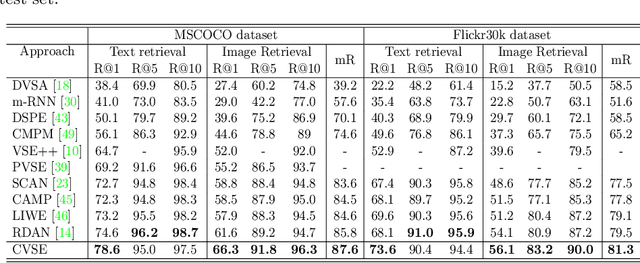
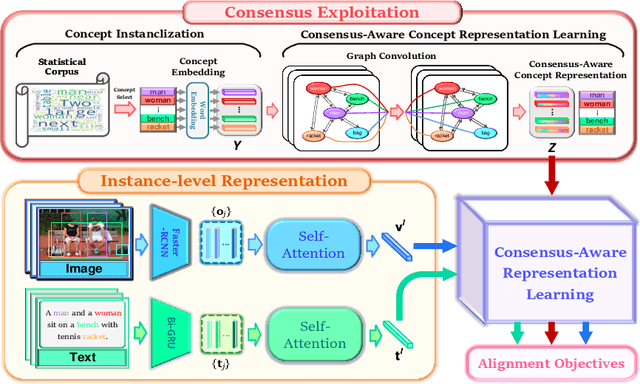
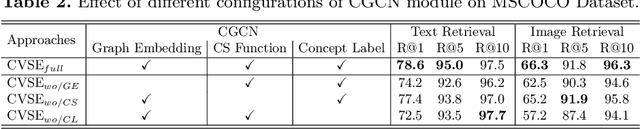
Image-text matching plays a central role in bridging vision and language. Most existing approaches only rely on the image-text instance pair to learn their representations, thereby exploiting their matching relationships and making the corresponding alignments. Such approaches only exploit the superficial associations contained in the instance pairwise data, with no consideration of any external commonsense knowledge, which may hinder their capabilities to reason the higher-level relationships between image and text. In this paper, we propose a Consensus-aware Visual-Semantic Embedding (CVSE) model to incorporate the consensus information, namely the commonsense knowledge shared between both modalities, into image-text matching. Specifically, the consensus information is exploited by computing the statistical co-occurrence correlations between the semantic concepts from the image captioning corpus and deploying the constructed concept correlation graph to yield the consensus-aware concept (CAC) representations. Afterwards, CVSE learns the associations and alignments between image and text based on the exploited consensus as well as the instance-level representations for both modalities. Extensive experiments conducted on two public datasets verify that the exploited consensus makes significant contributions to constructing more meaningful visual-semantic embeddings, with the superior performances over the state-of-the-art approaches on the bidirectional image and text retrieval task. Our code of this paper is available at: https://github.com/BruceW91/CVSE.
GTNet: Generative Transfer Network for Zero-Shot Object Detection
Jan 24, 2020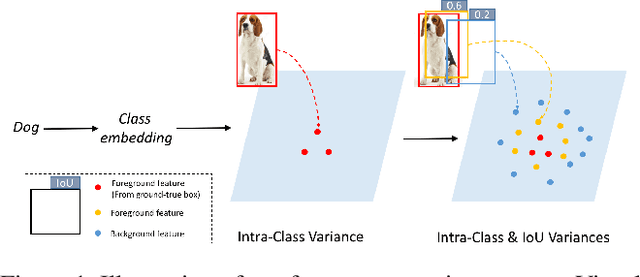
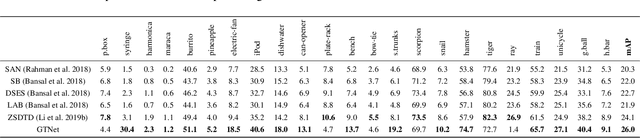
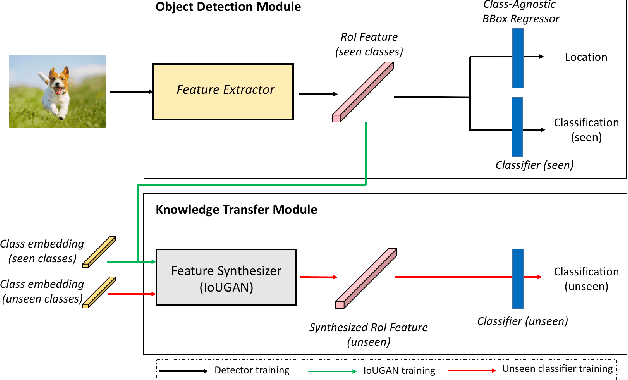
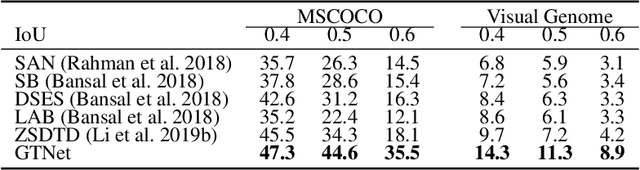
We propose a Generative Transfer Network (GTNet) for zero shot object detection (ZSD). GTNet consists of an Object Detection Module and a Knowledge Transfer Module. The Object Detection Module can learn large-scale seen domain knowledge. The Knowledge Transfer Module leverages a feature synthesizer to generate unseen class features, which are applied to train a new classification layer for the Object Detection Module. In order to synthesize features for each unseen class with both the intra-class variance and the IoU variance, we design an IoU-Aware Generative Adversarial Network (IoUGAN) as the feature synthesizer, which can be easily integrated into GTNet. Specifically, IoUGAN consists of three unit models: Class Feature Generating Unit (CFU), Foreground Feature Generating Unit (FFU), and Background Feature Generating Unit (BFU). CFU generates unseen features with the intra-class variance conditioned on the class semantic embeddings. FFU and BFU add the IoU variance to the results of CFU, yielding class-specific foreground and background features, respectively. We evaluate our method on three public datasets and the results demonstrate that our method performs favorably against the state-of-the-art ZSD approaches.
A Semantics-Guided Class Imbalance Learning Model for Zero-Shot Classification
Aug 26, 2019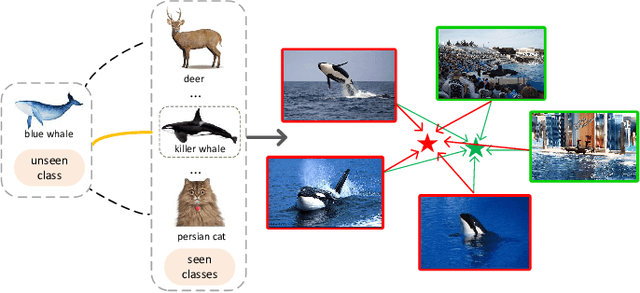
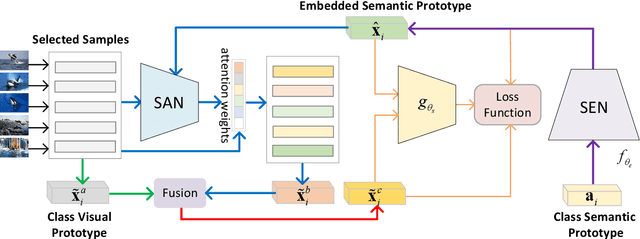
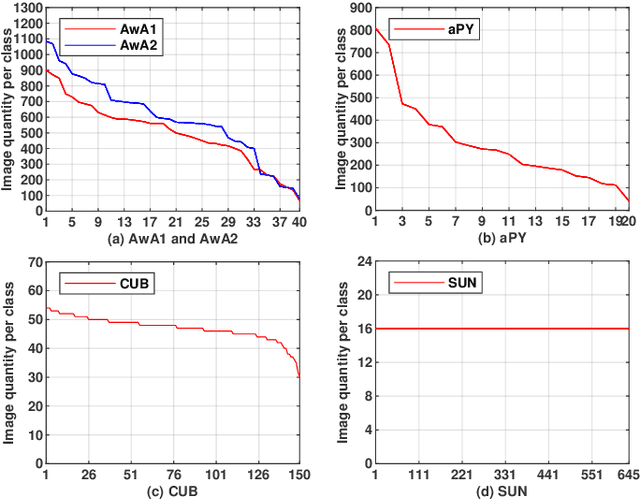
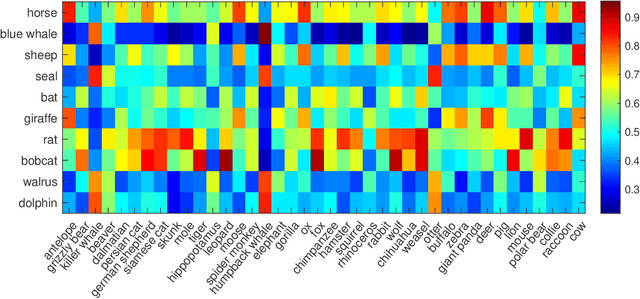
Zero-Shot Classification (ZSC) equips the learned model with the ability to recognize the visual instances from the novel classes via constructing the interactions between the visual and the semantic modalities. In contrast to the traditional image classification, ZSC is easily suffered from the class-imbalance issue since it is more concerned with the class-level knowledge transfer capability. In the real world, the class samples follow a long-tailed distribution, and the discriminative information in the sample-scarce seen classes is hard to be transferred to the related unseen classes in the traditional batch-based training manner, which degrades the overall generalization ability a lot. Towards alleviating the class imbalance issue in ZSC, we propose a sample-balanced training process to encourage all training classes to contribute equally to the learned model. Specifically, we randomly select the same number of images from each class across all training classes to form a training batch to ensure that the sample-scarce classes contribute equally as those classes with sufficient samples during each iteration. Considering that the instances from the same class differ in class representativeness, we further develop an efficient semantics-guided feature fusion model to obtain discriminative class visual prototype for the following visual-semantic interaction process via distributing different weights to the selected samples based on their class representativeness. Extensive experiments on three imbalanced ZSC benchmark datasets for both the Traditional ZSC (TZSC) and the Generalized ZSC (GZSC) tasks demonstrate our approach achieves promising results especially for the unseen categories those are closely related to the sample-scarce seen categories.
Saliency-Guided Attention Network for Image-Sentence Matching
Apr 20, 2019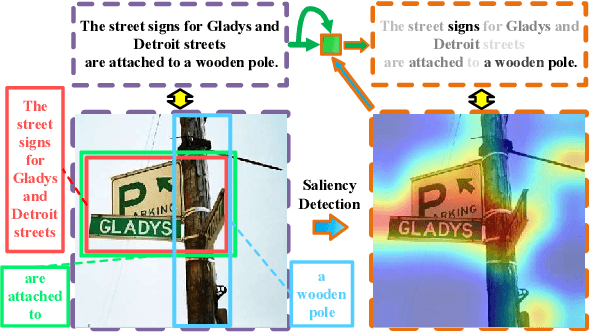
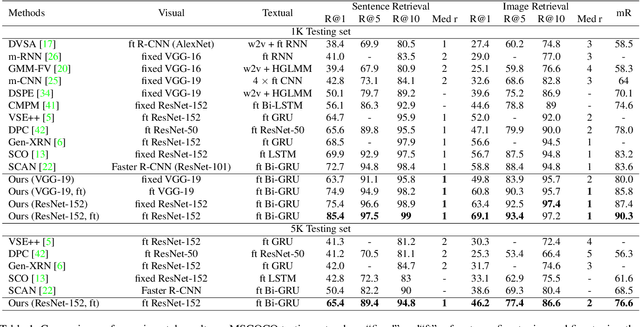
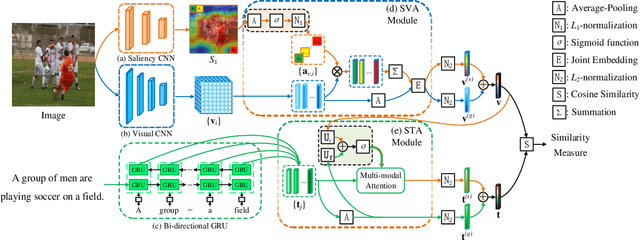
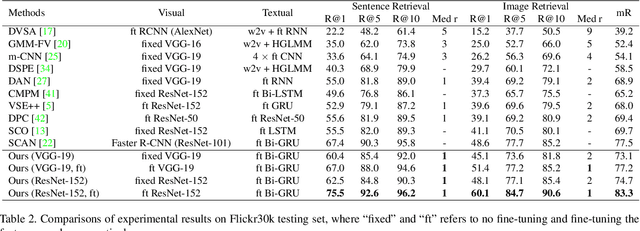
This paper studies the task of matching image and sentence, where learning appropriate representations across the multi-modal data appears to be the main challenge. Unlike previous approaches that predominantly deploy symmetrical architecture to represent both modalities, we propose Saliency-guided Attention Network (SAN) that asymmetrically employs visual and textual attention modules to learn the fine-grained correlation intertwined between vision and language. The proposed SAN mainly includes three components: saliency detector, Saliency-weighted Visual Attention (SVA) module, and Saliency-guided Textual Attention (STA) module. Concretely, the saliency detector provides the visual saliency information as the guidance for the two attention modules. SVA is designed to leverage the advantage of the saliency information to improve discrimination of visual representations. By fusing the visual information from SVA and textual information as a multi-modal guidance, STA learns discriminative textual representations that are highly sensitive to visual clues. Extensive experiments demonstrate SAN can substantially improve the state-of-the-art results on the benchmark Flickr30K and MSCOCO datasets by a large margin.