 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX$^{2}$-Gaussian: 4D Radiative Gaussian Splatting for Continuous-time Tomographic Reconstruction
Mar 27, 2025Four-dimensional computed tomography (4D CT) reconstruction is crucial for capturing dynamic anatomical changes but faces inherent limitations from conventional phase-binning workflows. Current methods discretize temporal resolution into fixed phases with respiratory gating devices, introducing motion misalignment and restricting clinical practicality. In this paper, We propose X$^2$-Gaussian, a novel framework that enables continuous-time 4D-CT reconstruction by integrating dynamic radiative Gaussian splatting with self-supervised respiratory motion learning. Our approach models anatomical dynamics through a spatiotemporal encoder-decoder architecture that predicts time-varying Gaussian deformations, eliminating phase discretization. To remove dependency on external gating devices, we introduce a physiology-driven periodic consistency loss that learns patient-specific breathing cycles directly from projections via differentiable optimization. Extensive experiments demonstrate state-of-the-art performance, achieving a 9.93 dB PSNR gain over traditional methods and 2.25 dB improvement against prior Gaussian splatting techniques. By unifying continuous motion modeling with hardware-free period learning, X$^2$-Gaussian advances high-fidelity 4D CT reconstruction for dynamic clinical imaging. Project website at: https://x2-gaussian.github.io/.
Feature4X: Bridging Any Monocular Video to 4D Agentic AI with Versatile Gaussian Feature Fields
Mar 26, 2025Recent advancements in 2D and multimodal models have achieved remarkable success by leveraging large-scale training on extensive datasets. However, extending these achievements to enable free-form interactions and high-level semantic operations with complex 3D/4D scenes remains challenging. This difficulty stems from the limited availability of large-scale, annotated 3D/4D or multi-view datasets, which are crucial for generalizable vision and language tasks such as open-vocabulary and prompt-based segmentation, language-guided editing, and visual question answering (VQA). In this paper, we introduce Feature4X, a universal framework designed to extend any functionality from 2D vision foundation model into the 4D realm, using only monocular video input, which is widely available from user-generated content. The "X" in Feature4X represents its versatility, enabling any task through adaptable, model-conditioned 4D feature field distillation. At the core of our framework is a dynamic optimization strategy that unifies multiple model capabilities into a single representation. Additionally, to the best of our knowledge, Feature4X is the first method to distill and lift the features of video foundation models (e.g. SAM2, InternVideo2) into an explicit 4D feature field using Gaussian Splatting. Our experiments showcase novel view segment anything, geometric and appearance scene editing, and free-form VQA across all time steps, empowered by LLMs in feedback loops. These advancements broaden the scope of agentic AI applications by providing a foundation for scalable, contextually and spatiotemporally aware systems capable of immersive dynamic 4D scene interaction.
VideoLifter: Lifting Videos to 3D with Fast Hierarchical Stereo Alignment
Jan 03, 2025



Efficiently reconstructing accurate 3D models from monocular video is a key challenge in computer vision, critical for advancing applications in virtual reality, robotics, and scene understanding. Existing approaches typically require pre-computed camera parameters and frame-by-frame reconstruction pipelines, which are prone to error accumulation and entail significant computational overhead. To address these limitations, we introduce VideoLifter, a novel framework that leverages geometric priors from a learnable model to incrementally optimize a globally sparse to dense 3D representation directly from video sequences. VideoLifter segments the video sequence into local windows, where it matches and registers frames, constructs consistent fragments, and aligns them hierarchically to produce a unified 3D model. By tracking and propagating sparse point correspondences across frames and fragments, VideoLifter incrementally refines camera poses and 3D structure, minimizing reprojection error for improved accuracy and robustness. This approach significantly accelerates the reconstruction process, reducing training time by over 82% while surpassing current state-of-the-art methods in visual fidelity and computational efficiency.
Large Spatial Model: End-to-end Unposed Images to Semantic 3D
Oct 24, 2024



Reconstructing and understanding 3D structures from a limited number of images is a well-established problem in computer vision. Traditional methods usually break this task into multiple subtasks, each requiring complex transformations between different data representations. For instance, dense reconstruction through Structure-from-Motion (SfM) involves converting images into key points, optimizing camera parameters, and estimating structures. Afterward, accurate sparse reconstructions are required for further dense modeling, which is subsequently fed into task-specific neural networks. This multi-step process results in considerable processing time and increased engineering complexity. In this work, we present the Large Spatial Model (LSM), which processes unposed RGB images directly into semantic radiance fields. LSM simultaneously estimates geometry, appearance, and semantics in a single feed-forward operation, and it can generate versatile label maps by interacting with language at novel viewpoints. Leveraging a Transformer-based architecture, LSM integrates global geometry through pixel-aligned point maps. To enhance spatial attribute regression, we incorporate local context aggregation with multi-scale fusion, improving the accuracy of fine local details. To tackle the scarcity of labeled 3D semantic data and enable natural language-driven scene manipulation, we incorporate a pre-trained 2D language-based segmentation model into a 3D-consistent semantic feature field. An efficient decoder then parameterizes a set of semantic anisotropic Gaussians, facilitating supervised end-to-end learning. Extensive experiments across various tasks show that LSM unifies multiple 3D vision tasks directly from unposed images, achieving real-time semantic 3D reconstruction for the first time.
Expressive Gaussian Human Avatars from Monocular RGB Video
Jul 03, 2024



Nuanced expressiveness, particularly through fine-grained hand and facial expressions, is pivotal for enhancing the realism and vitality of digital human representations. In this work, we focus on investigating the expressiveness of human avatars when learned from monocular RGB video; a setting that introduces new challenges in capturing and animating fine-grained details. To this end, we introduce EVA, a drivable human model that meticulously sculpts fine details based on 3D Gaussians and SMPL-X, an expressive parametric human model. Focused on enhancing expressiveness, our work makes three key contributions. First, we highlight the critical importance of aligning the SMPL-X model with RGB frames for effective avatar learning. Recognizing the limitations of current SMPL-X prediction methods for in-the-wild videos, we introduce a plug-and-play module that significantly ameliorates misalignment issues. Second, we propose a context-aware adaptive density control strategy, which is adaptively adjusting the gradient thresholds to accommodate the varied granularity across body parts. Last but not least, we develop a feedback mechanism that predicts per-pixel confidence to better guide the learning of 3D Gaussians. Extensive experiments on two benchmarks demonstrate the superiority of our framework both quantitatively and qualitatively, especially on the fine-grained hand and facial details. See the project website at \url{https://evahuman.github.io}
GaussianStego: A Generalizable Stenography Pipeline for Generative 3D Gaussians Splatting
Jul 01, 2024



Recent advancements in large generative models and real-time neural rendering using point-based techniques pave the way for a future of widespread visual data distribution through sharing synthesized 3D assets. However, while standardized methods for embedding proprietary or copyright information, either overtly or subtly, exist for conventional visual content such as images and videos, this issue remains unexplored for emerging generative 3D formats like Gaussian Splatting. We present GaussianStego, a method for embedding steganographic information in the rendering of generated 3D assets. Our approach employs an optimization framework that enables the accurate extraction of hidden information from images rendered using Gaussian assets derived from large models, while maintaining their original visual quality. We conduct preliminary evaluations of our method across several potential deployment scenarios and discuss issues identified through analysis. GaussianStego represents an initial exploration into the novel challenge of embedding customizable, imperceptible, and recoverable information within the renders produced by current 3D generative models, while ensuring minimal impact on the rendered content's quality.
4K4DGen: Panoramic 4D Generation at 4K Resolution
Jun 19, 2024



The blooming of virtual reality and augmented reality (VR/AR) technologies has driven an increasing demand for the creation of high-quality, immersive, and dynamic environments. However, existing generative techniques either focus solely on dynamic objects or perform outpainting from a single perspective image, failing to meet the needs of VR/AR applications. In this work, we tackle the challenging task of elevating a single panorama to an immersive 4D experience. For the first time, we demonstrate the capability to generate omnidirectional dynamic scenes with 360-degree views at 4K resolution, thereby providing an immersive user experience. Our method introduces a pipeline that facilitates natural scene animations and optimizes a set of 4D Gaussians using efficient splatting techniques for real-time exploration. To overcome the lack of scene-scale annotated 4D data and models, especially in panoramic formats, we propose a novel Panoramic Denoiser that adapts generic 2D diffusion priors to animate consistently in 360-degree images, transforming them into panoramic videos with dynamic scenes at targeted regions. Subsequently, we elevate the panoramic video into a 4D immersive environment while preserving spatial and temporal consistency. By transferring prior knowledge from 2D models in the perspective domain to the panoramic domain and the 4D lifting with spatial appearance and geometry regularization, we achieve high-quality Panorama-to-4D generation at a resolution of (4096 $\times$ 2048) for the first time. See the project website at https://4k4dgen.github.io.
Learning Traffic Crashes as Language: Datasets, Benchmarks, and What-if Causal Analyses
Jun 16, 2024



The increasing rate of road accidents worldwide results not only in significant loss of life but also imposes billions financial burdens on societies. Current research in traffic crash frequency modeling and analysis has predominantly approached the problem as classification tasks, focusing mainly on learning-based classification or ensemble learning methods. These approaches often overlook the intricate relationships among the complex infrastructure, environmental, human and contextual factors related to traffic crashes and risky situations. In contrast, we initially propose a large-scale traffic crash language dataset, named CrashEvent, summarizing 19,340 real-world crash reports and incorporating infrastructure data, environmental and traffic textual and visual information in Washington State. Leveraging this rich dataset, we further formulate the crash event feature learning as a novel text reasoning problem and further fine-tune various large language models (LLMs) to predict detailed accident outcomes, such as crash types, severity and number of injuries, based on contextual and environmental factors. The proposed model, CrashLLM, distinguishes itself from existing solutions by leveraging the inherent text reasoning capabilities of LLMs to parse and learn from complex, unstructured data, thereby enabling a more nuanced analysis of contributing factors. Our experiments results shows that our LLM-based approach not only predicts the severity of accidents but also classifies different types of accidents and predicts injury outcomes, all with averaged F1 score boosted from 34.9% to 53.8%. Furthermore, CrashLLM can provide valuable insights for numerous open-world what-if situational-awareness traffic safety analyses with learned reasoning features, which existing models cannot offer. We make our benchmark, datasets, and model public available for further exploration.
LLMGeo: Benchmarking Large Language Models on Image Geolocation In-the-wild
May 30, 2024



Image geolocation is a critical task in various image-understanding applications. However, existing methods often fail when analyzing challenging, in-the-wild images. Inspired by the exceptional background knowledge of multimodal language models, we systematically evaluate their geolocation capabilities using a novel image dataset and a comprehensive evaluation framework. We first collect images from various countries via Google Street View. Then, we conduct training-free and training-based evaluations on closed-source and open-source multi-modal language models. we conduct both training-free and training-based evaluations on closed-source and open-source multimodal language models. Our findings indicate that closed-source models demonstrate superior geolocation abilities, while open-source models can achieve comparable performance through fine-tuning.
DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
Apr 10, 2024

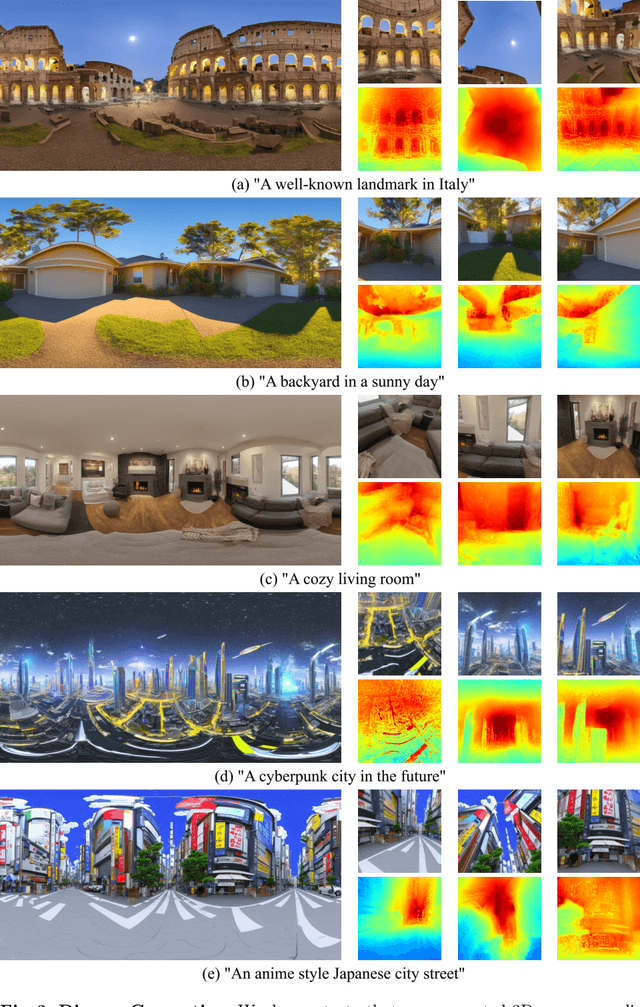

The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360$^{\circ}$ scene generation pipeline that facilitates the creation of comprehensive 360$^{\circ}$ scenes for in-the-wild environments in a matter of minutes. Our approach utilizes the generative power of a 2D diffusion model and prompt self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary "flat" (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration. To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians. In order to address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions. In summary, our method offers a globally consistent 3D scene within a 360$^{\circ}$ perspective, providing an enhanced immersive experience over existing techniques. Project website at: http://dreamscene360.github.io/