 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualCritic: Making LMMs Perceive Visual Quality Like Humans
Mar 19, 2024



At present, large multimodal models (LMMs) have exhibited impressive generalization capabilities in understanding and generating visual signals. However, they currently still lack sufficient capability to perceive low-level visual quality akin to human perception. Can LMMs achieve this and show the same degree of generalization in this regard? If so, not only could the versatility of LMMs be further enhanced, but also the challenge of poor cross-dataset performance in the field of visual quality assessment could be addressed. In this paper, we explore this question and provide the answer "Yes!". As the result of this initial exploration, we present VisualCritic, the first LMM for broad-spectrum image subjective quality assessment. VisualCritic can be used across diverse data right out of box, without any requirements of dataset-specific adaptation operations like conventional specialist models. As an instruction-following LMM, VisualCritic enables new capabilities of (1) quantitatively measuring the perceptual quality of given images in terms of their Mean Opinion Score (MOS), noisiness, colorfulness, sharpness, and other numerical indicators, (2) qualitatively evaluating visual quality and providing explainable descriptions, (3) discerning whether a given image is AI-generated or photographic. Extensive experiments demonstrate the efficacy of VisualCritic by comparing it with other open-source LMMs and conventional specialist models over both AI-generated and photographic images.
Adaptive Frequency Filters As Efficient Global Token Mixers
Jul 26, 2023Recent vision transformers, large-kernel CNNs and MLPs have attained remarkable successes in broad vision tasks thanks to their effective information fusion in the global scope. However, their efficient deployments, especially on mobile devices, still suffer from noteworthy challenges due to the heavy computational costs of self-attention mechanisms, large kernels, or fully connected layers. In this work, we apply conventional convolution theorem to deep learning for addressing this and reveal that adaptive frequency filters can serve as efficient global token mixers. With this insight, we propose Adaptive Frequency Filtering (AFF) token mixer. This neural operator transfers a latent representation to the frequency domain via a Fourier transform and performs semantic-adaptive frequency filtering via an elementwise multiplication, which mathematically equals to a token mixing operation in the original latent space with a dynamic convolution kernel as large as the spatial resolution of this latent representation. We take AFF token mixers as primary neural operators to build a lightweight neural network, dubbed AFFNet. Extensive experiments demonstrate the effectiveness of our proposed AFF token mixer and show that AFFNet achieve superior accuracy and efficiency trade-offs compared to other lightweight network designs on broad visual tasks, including visual recognition and dense prediction tasks.
A Latent Space Model for HLA Compatibility Networks in Kidney Transplantation
Nov 04, 2022



Kidney transplantation is the preferred treatment for people suffering from end-stage renal disease. Successful kidney transplants still fail over time, known as graft failure; however, the time to graft failure, or graft survival time, can vary significantly between different recipients. A significant biological factor affecting graft survival times is the compatibility between the human leukocyte antigens (HLAs) of the donor and recipient. We propose to model HLA compatibility using a network, where the nodes denote different HLAs of the donor and recipient, and edge weights denote compatibilities of the HLAs, which can be positive or negative. The network is indirectly observed, as the edge weights are estimated from transplant outcomes rather than directly observed. We propose a latent space model for such indirectly-observed weighted and signed networks. We demonstrate that our latent space model can not only result in more accurate estimates of HLA compatibilities, but can also be incorporated into survival analysis models to improve accuracy for the downstream task of predicting graft survival times.
A Mutually Exciting Latent Space Hawkes Process Model for Continuous-time Networks
May 19, 2022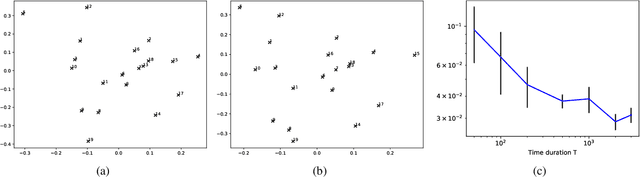
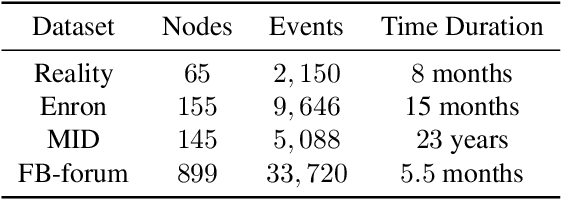
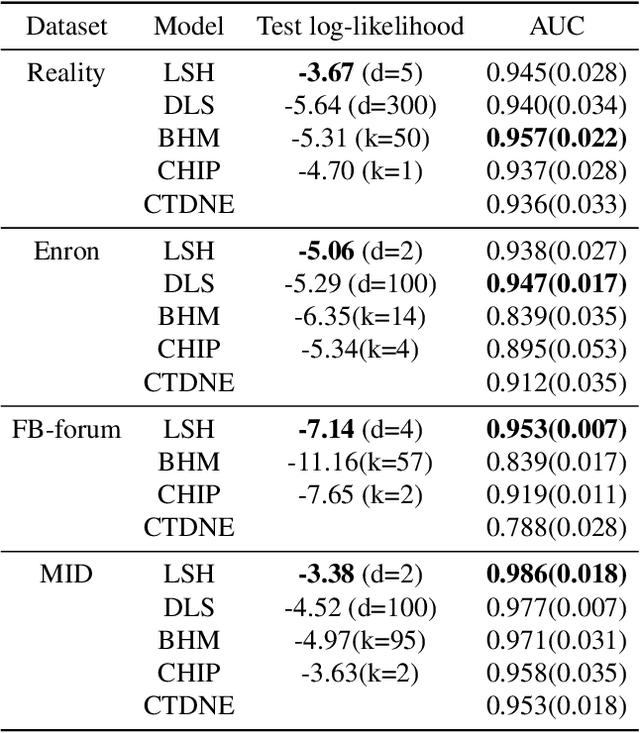
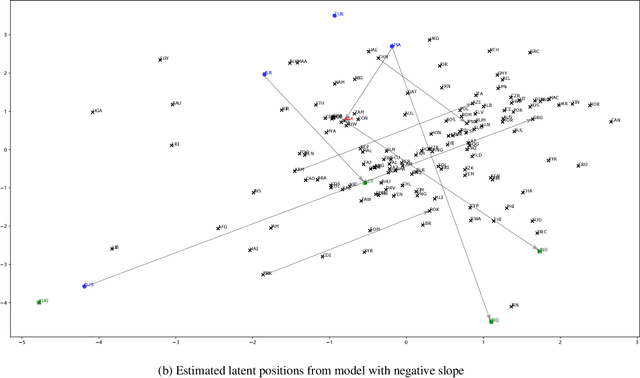
Networks and temporal point processes serve as fundamental building blocks for modeling complex dynamic relational data in various domains. We propose the latent space Hawkes (LSH) model, a novel generative model for continuous-time networks of relational events, using a latent space representation for nodes. We model relational events between nodes using mutually exciting Hawkes processes with baseline intensities dependent upon the distances between the nodes in the latent space and sender and receiver specific effects. We propose an alternating minimization algorithm to jointly estimate the latent positions of the nodes and other model parameters. We demonstrate that our proposed LSH model can replicate many features observed in real temporal networks including reciprocity and transitivity, while also achieves superior prediction accuracy and provides more interpretability compared to existing models.
The Multivariate Community Hawkes Model for Dependent Relational Events in Continuous-time Networks
May 02, 2022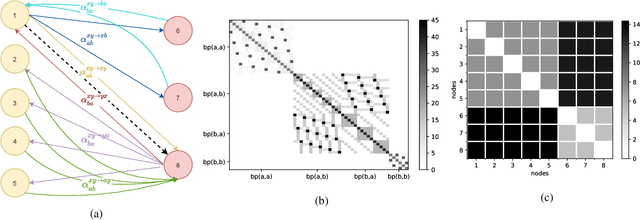

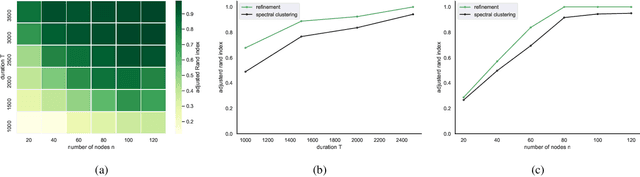
The stochastic block model (SBM) is one of the most widely used generative models for network data. Many continuous-time dynamic network models are built upon the same assumption as the SBM: edges or events between all pairs of nodes are conditionally independent given the block or community memberships, which prevents them from reproducing higher-order motifs such as triangles that are commonly observed in real networks. We propose the multivariate community Hawkes (MULCH) model, an extremely flexible community-based model for continuous-time networks that introduces dependence between node pairs using structured multivariate Hawkes processes. We fit the model using a spectral clustering and likelihood-based local refinement procedure. We find that our proposed MULCH model is far more accurate than existing models both for predictive and generative tasks.
Deep Frequency Filtering for Domain Generalization
Mar 23, 2022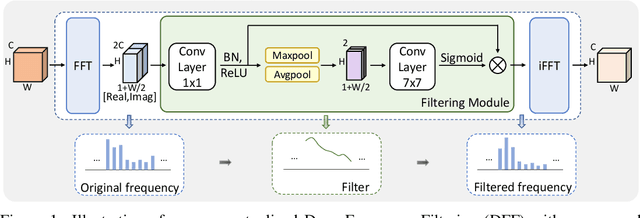
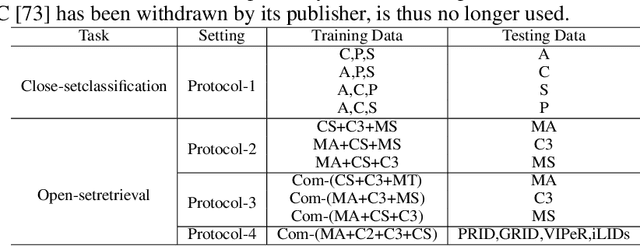
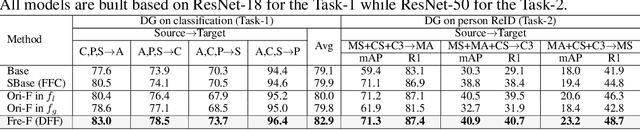

Improving the generalization capability of Deep Neural Networks (DNNs) is critical for their practical uses, which has been a longstanding challenge. Some theoretical studies have revealed that DNNs have preferences to different frequency components in the learning process and indicated that this may affect the robustness of learned features. In this paper, we propose Deep Frequency Filtering (DFF) for learning domain-generalizable features, which is the first endeavour to explicitly modulate frequency components of different transfer difficulties across domains during training. To achieve this, we perform Fast Fourier Transform (FFT) on feature maps at different layers, then adopt a light-weight module to learn the attention masks from frequency representations after FFT to enhance transferable frequency components while suppressing the components not conductive to generalization. Further, we empirically compare different types of attention for implementing our conceptualized DFF. Extensive experiments demonstrate the effectiveness of the proposed DFF and show that applying DFF on a plain baseline outperforms the state-of-the-art methods on different domain generalization tasks, including close-set classification and open-set retrieval.
Debiased Batch Normalization via Gaussian Process for Generalizable Person Re-Identification
Mar 16, 2022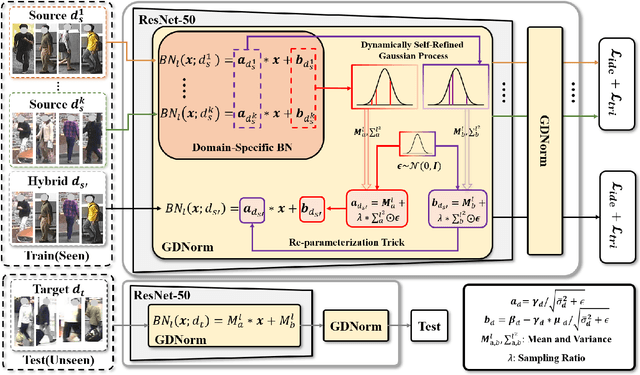
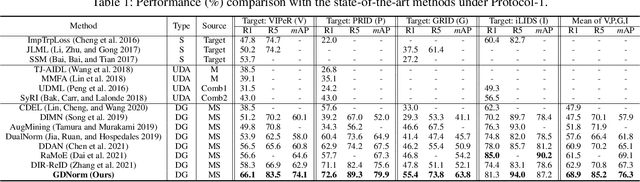
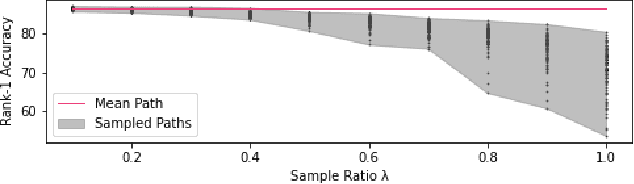
Generalizable person re-identification aims to learn a model with only several labeled source domains that can perform well on unseen domains. Without access to the unseen domain, the feature statistics of the batch normalization (BN) layer learned from a limited number of source domains is doubtlessly biased for unseen domain. This would mislead the feature representation learning for unseen domain and deteriorate the generalizaiton ability of the model. In this paper, we propose a novel Debiased Batch Normalization via Gaussian Process approach (GDNorm) for generalizable person re-identification, which models the feature statistic estimation from BN layers as a dynamically self-refining Gaussian process to alleviate the bias to unseen domain for improving the generalization. Specifically, we establish a lightweight model with multiple set of domain-specific BN layers to capture the discriminability of individual source domain, and learn the corresponding parameters of the domain-specific BN layers. These parameters of different source domains are employed to deduce a Gaussian process. We randomly sample several paths from this Gaussian process served as the BN estimations of potential new domains outside of existing source domains, which can further optimize these learned parameters from source domains, and estimate more accurate Gaussian process by them in return, tending to real data distribution. Even without a large number of source domains, GDNorm can still provide debiased BN estimation by using the mean path of the Gaussian process, while maintaining low computational cost during testing. Extensive experiments demonstrate that our GDNorm effectively improves the generalization ability of the model on unseen domain.
Modality-Adaptive Mixup and Invariant Decomposition for RGB-Infrared Person Re-Identification
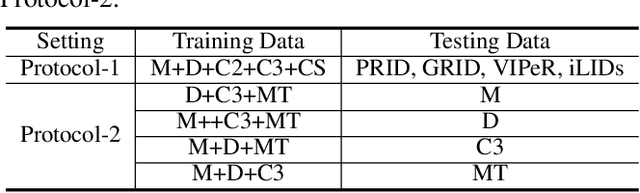
Mar 16, 2022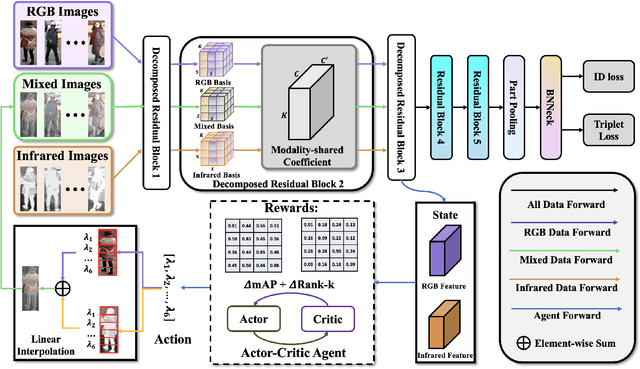
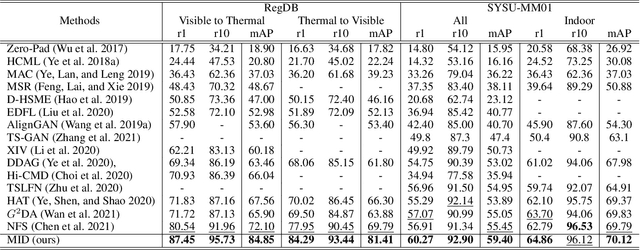

RGB-infrared person re-identification is an emerging cross-modality re-identification task, which is very challenging due to significant modality discrepancy between RGB and infrared images. In this work, we propose a novel modality-adaptive mixup and invariant decomposition (MID) approach for RGB-infrared person re-identification towards learning modality-invariant and discriminative representations. MID designs a modality-adaptive mixup scheme to generate suitable mixed modality images between RGB and infrared images for mitigating the inherent modality discrepancy at the pixel-level. It formulates modality mixup procedure as Markov decision process, where an actor-critic agent learns dynamical and local linear interpolation policy between different regions of cross-modality images under a deep reinforcement learning framework. Such policy guarantees modality-invariance in a more continuous latent space and avoids manifold intrusion by the corrupted mixed modality samples. Moreover, to further counter modality discrepancy and enforce invariant visual semantics at the feature-level, MID employs modality-adaptive convolution decomposition to disassemble a regular convolution layer into modality-specific basis layers and a modality-shared coefficient layer. Extensive experimental results on two challenging benchmarks demonstrate superior performance of MID over state-of-the-art methods.
Lifelong Unsupervised Domain Adaptive Person Re-identification with Coordinated Anti-forgetting and Adaptation
Dec 13, 2021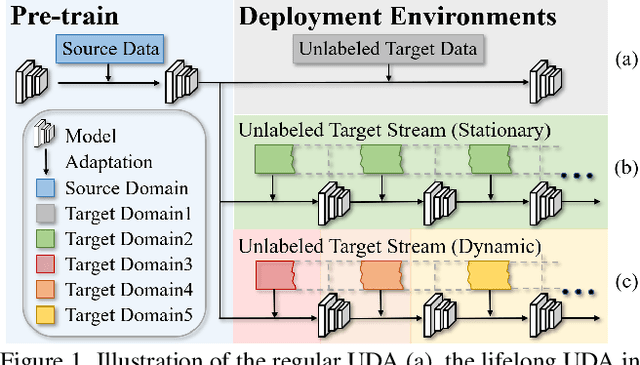

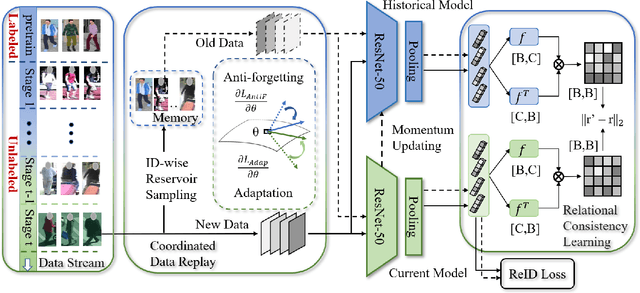
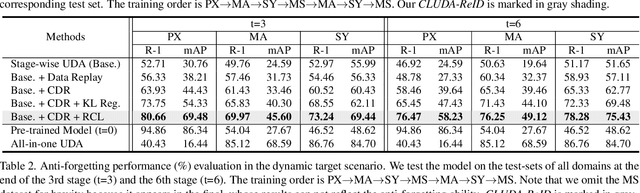
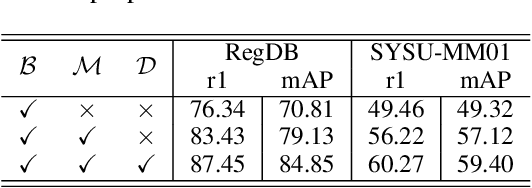
Unsupervised domain adaptive person re-identification (ReID) has been extensively investigated to mitigate the adverse effects of domain gaps. Those works assume the target domain data can be accessible all at once. However, for the real-world streaming data, this hinders the timely adaptation to changing data statistics and sufficient exploitation of increasing samples. In this paper, to address more practical scenarios, we propose a new task, Lifelong Unsupervised Domain Adaptive (LUDA) person ReID. This is challenging because it requires the model to continuously adapt to unlabeled data of the target environments while alleviating catastrophic forgetting for such a fine-grained person retrieval task. We design an effective scheme for this task, dubbed CLUDA-ReID, where the anti-forgetting is harmoniously coordinated with the adaptation. Specifically, a meta-based Coordinated Data Replay strategy is proposed to replay old data and update the network with a coordinated optimization direction for both adaptation and memorization. Moreover, we propose Relational Consistency Learning for old knowledge distillation/inheritance in line with the objective of retrieval-based tasks. We set up two evaluation settings to simulate the practical application scenarios. Extensive experiments demonstrate the effectiveness of our CLUDA-ReID for both scenarios with stationary target streams and scenarios with dynamic target streams.
Adaptive Domain-Specific Normalization for Generalizable Person Re-Identification
May 11, 2021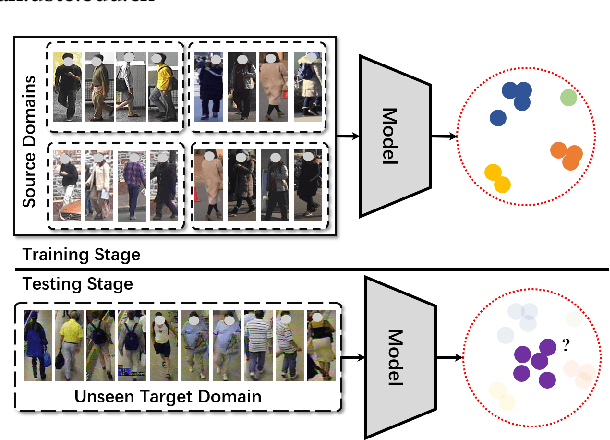
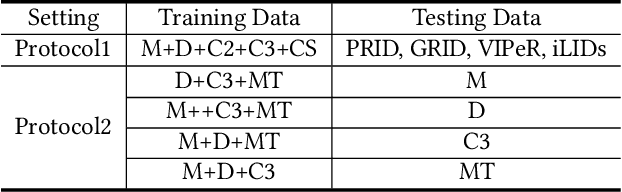
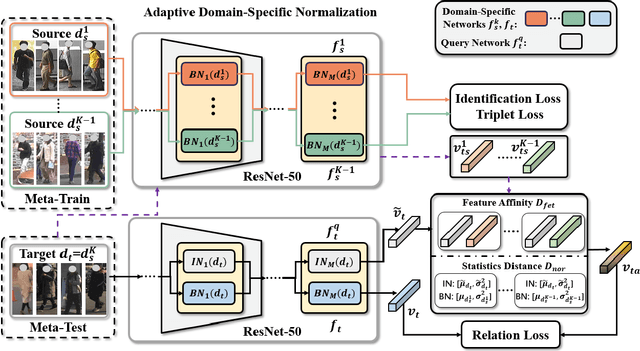
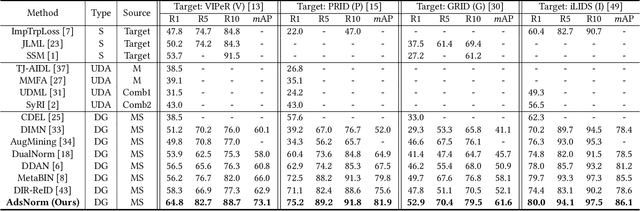
Although existing person re-identification (Re-ID) methods have shown impressive accuracy, most of them usually suffer from poor generalization on unseen target domain. Thus, generalizable person Re-ID has recently drawn increasing attention, which trains a model on source domains that generalizes well on unseen target domain without model updating. In this work, we propose a novel adaptive domain-specific normalization approach (AdsNorm) for generalizable person Re-ID. It describes unseen target domain as a combination of the known source ones, and explicitly learns domain-specific representation with target distribution to improve the model's generalization by a meta-learning pipeline. Specifically, AdsNorm utilizes batch normalization layers to collect individual source domains' characteristics, and maps source domains into a shared latent space by using these characteristics, where the domain relevance is measured by a distance function of different domain-specific normalization statistics and features. At the testing stage, AdsNorm projects images from unseen target domain into the same latent space, and adaptively integrates the domain-specific features carrying the source distributions by domain relevance for learning more generalizable aggregated representation on unseen target domain. Considering that target domain is unavailable during training, a meta-learning algorithm combined with a customized relation loss is proposed to optimize an effective and efficient ensemble model. Extensive experiments demonstrate that AdsNorm outperforms the state-of-the-art methods. The code is available at: https://github.com/hzphzp/AdsNorm.