 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoNav: Collaborative Cross-Modal Reasoning for Embodied Navigation
May 22, 2025Embodied navigation demands comprehensive scene understanding and precise spatial reasoning. While image-text models excel at interpreting pixel-level color and lighting cues, 3D-text models capture volumetric structure and spatial relationships. However, unified fusion approaches that jointly fuse 2D images, 3D point clouds, and textual instructions face challenges in limited availability of triple-modality data and difficulty resolving conflicting beliefs among modalities. In this work, we introduce CoNav, a collaborative cross-modal reasoning framework where a pretrained 3D-text model explicitly guides an image-text navigation agent by providing structured spatial-semantic knowledge to resolve ambiguities during navigation. Specifically, we introduce Cross-Modal Belief Alignment, which operationalizes this cross-modal guidance by simply sharing textual hypotheses from the 3D-text model to the navigation agent. Through lightweight fine-tuning on a small 2D-3D-text corpus, the navigation agent learns to integrate visual cues with spatial-semantic knowledge derived from the 3D-text model, enabling effective reasoning in embodied navigation. CoNav achieves significant improvements on four standard embodied navigation benchmarks (R2R, CVDN, REVERIE, SOON) and two spatial reasoning benchmarks (ScanQA, SQA3D). Moreover, under close navigation Success Rate, CoNav often generates shorter paths compared to other methods (as measured by SPL), showcasing the potential and challenges of fusing data from different modalities in embodied navigation. Project Page: https://oceanhao.github.io/CoNav/
FANeRV: Frequency Separation and Augmentation based Neural Representation for Video
Apr 09, 2025Neural representations for video (NeRV) have gained considerable attention for their strong performance across various video tasks. However, existing NeRV methods often struggle to capture fine spatial details, resulting in vague reconstructions. In this paper, we present a Frequency Separation and Augmentation based Neural Representation for video (FANeRV), which addresses these limitations with its core Wavelet Frequency Upgrade Block.This block explicitly separates input frames into high and low-frequency components using discrete wavelet transform, followed by targeted enhancement using specialized modules. Finally, a specially designed gated network effectively fuses these frequency components for optimal reconstruction. Additionally, convolutional residual enhancement blocks are integrated into the later stages of the network to balance parameter distribution and improve the restoration of high-frequency details. Experimental results demonstrate that FANeRV significantly improves reconstruction performance and excels in multiple tasks, including video compression, inpainting, and interpolation, outperforming existing NeRV methods.
Learning A Zero-shot Occupancy Network from Vision Foundation Models via Self-supervised Adaptation
Mar 10, 2025Estimating the 3D world from 2D monocular images is a fundamental yet challenging task due to the labour-intensive nature of 3D annotations. To simplify label acquisition, this work proposes a novel approach that bridges 2D vision foundation models (VFMs) with 3D tasks by decoupling 3D supervision into an ensemble of image-level primitives, e.g., semantic and geometric components. As a key motivator, we leverage the zero-shot capabilities of vision-language models for image semantics. However, due to the notorious ill-posed problem - multiple distinct 3D scenes can produce identical 2D projections, directly inferring metric depth from a monocular image in a zero-shot manner is unsuitable. In contrast, 2D VFMs provide promising sources of relative depth, which theoretically aligns with metric depth when properly scaled and offset. Thus, we adapt the relative depth derived from VFMs into metric depth by optimising the scale and offset using temporal consistency, also known as novel view synthesis, without access to ground-truth metric depth. Consequently, we project the semantics into 3D space using the reconstructed metric depth, thereby providing 3D supervision. Extensive experiments on nuScenes and SemanticKITTI demonstrate the effectiveness of our framework. For instance, the proposed method surpasses the current state-of-the-art by 3.34% mIoU on nuScenes for voxel occupancy prediction.
High-Frequency Enhanced Hybrid Neural Representation for Video Compression
Nov 11, 2024Neural Representations for Videos (NeRV) have simplified the video codec process and achieved swift decoding speeds by encoding video content into a neural network, presenting a promising solution for video compression. However, existing work overlooks the crucial issue that videos reconstructed by these methods lack high-frequency details. To address this problem, this paper introduces a High-Frequency Enhanced Hybrid Neural Representation Network. Our method focuses on leveraging high-frequency information to improve the synthesis of fine details by the network. Specifically, we design a wavelet high-frequency encoder that incorporates Wavelet Frequency Decomposer (WFD) blocks to generate high-frequency feature embeddings. Next, we design the High-Frequency Feature Modulation (HFM) block, which leverages the extracted high-frequency embeddings to enhance the fitting process of the decoder. Finally, with the refined Harmonic decoder block and a Dynamic Weighted Frequency Loss, we further reduce the potential loss of high-frequency information. Experiments on the Bunny and UVG datasets demonstrate that our method outperforms other methods, showing notable improvements in detail preservation and compression performance.
Unsupervised Visible-Infrared Person ReID by Collaborative Learning with Neighbor-Guided Label Refinement
May 22, 2023Unsupervised learning visible-infrared person re-identification (USL-VI-ReID) aims at learning modality-invariant features from unlabeled cross-modality dataset, which is crucial for practical applications in video surveillance systems. The key to essentially address the USL-VI-ReID task is to solve the cross-modality data association problem for further heterogeneous joint learning. To address this issue, we propose a Dual Optimal Transport Label Assignment (DOTLA) framework to simultaneously assign the generated labels from one modality to its counterpart modality. The proposed DOTLA mechanism formulates a mutual reinforcement and efficient solution to cross-modality data association, which could effectively reduce the side-effects of some insufficient and noisy label associations. Besides, we further propose a cross-modality neighbor consistency guided label refinement and regularization module, to eliminate the negative effects brought by the inaccurate supervised signals, under the assumption that the prediction or label distribution of each example should be similar to its nearest neighbors. Extensive experimental results on the public SYSU-MM01 and RegDB datasets demonstrate the effectiveness of the proposed method, surpassing existing state-of-the-art approach by a large margin of 7.76% mAP on average, which even surpasses some supervised VI-ReID methods.
Reentry Risk and Safety Assessment of Spacecraft Debris Based on Machine Learning
Feb 21, 2023Uncontrolled spacecraft will disintegrate and generate a large amount of debris in the reentry process, and ablative debris may cause potential risks to the safety of human life and property on the ground. Therefore, predicting the landing points of spacecraft debris and forecasting the degree of risk of debris to human life and property is very important. In view that it is difficult to predict the process of reentry process and the reentry point in advance, and the debris generated from reentry disintegration may cause ground damage for the uncontrolled space vehicle on expiration of service. In this paper, we adopt the object-oriented approach to consider the spacecraft and its disintegrated components as consisting of simple basic geometric models, and introduce three machine learning models: the support vector regression (SVR), decision tree regression (DTR) and multilayer perceptron (MLP) to predict the velocity, longitude and latitude of spacecraft debris landing points for the first time. Then, we compare the prediction accuracy of the three models. Furthermore, we define the reentry risk and the degree of danger, and we calculate the risk level for each spacecraft debris and make warnings accordingly. The experimental results show that the proposed method can obtain high accuracy prediction results in at least 15 seconds and make safety level warning more real-time.
SU-Net: Pose estimation network for non-cooperative spacecraft on-orbit
Feb 21, 2023Spacecraft pose estimation plays a vital role in many on-orbit space missions, such as rendezvous and docking, debris removal, and on-orbit maintenance. At present, space images contain widely varying lighting conditions, high contrast and low resolution, pose estimation of space objects is more challenging than that of objects on earth. In this paper, we analyzing the radar image characteristics of spacecraft on-orbit, then propose a new deep learning neural Network structure named Dense Residual U-shaped Network (DR-U-Net) to extract image features. We further introduce a novel neural network based on DR-U-Net, namely Spacecraft U-shaped Network (SU-Net) to achieve end-to-end pose estimation for non-cooperative spacecraft. Specifically, the SU-Net first preprocess the image of non-cooperative spacecraft, then transfer learning was used for pre-training. Subsequently, in order to solve the problem of radar image blur and low ability of spacecraft contour recognition, we add residual connection and dense connection to the backbone network U-Net, and we named it DR-U-Net. In this way, the feature loss and the complexity of the model is reduced, and the degradation of deep neural network during training is avoided. Finally, a layer of feedforward neural network is used for pose estimation of non-cooperative spacecraft on-orbit. Experiments prove that the proposed method does not rely on the hand-made object specific features, and the model has robust robustness, and the calculation accuracy outperforms the state-of-the-art pose estimation methods. The absolute error is 0.1557 to 0.4491 , the mean error is about 0.302 , and the standard deviation is about 0.065 .
DS-Net++: Dynamic Weight Slicing for Efficient Inference in CNNs and Transformers
Sep 21, 2021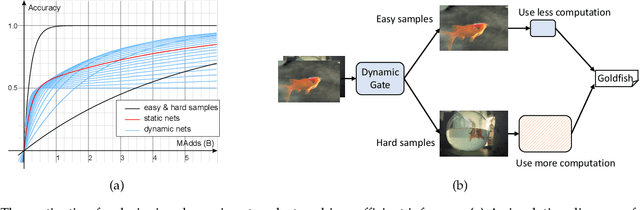
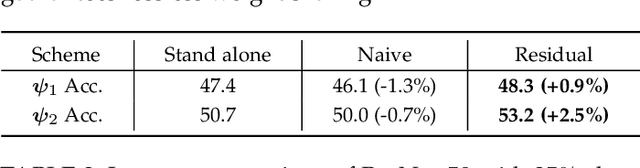
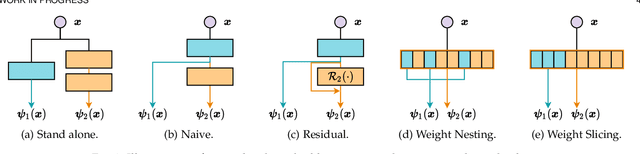
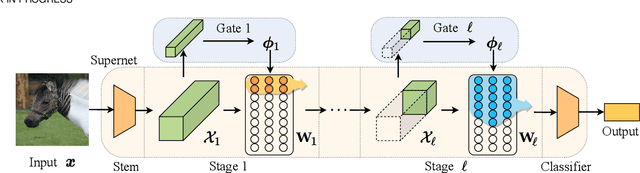
Dynamic networks have shown their promising capability in reducing theoretical computation complexity by adapting their architectures to the input during inference. However, their practical runtime usually lags behind the theoretical acceleration due to inefficient sparsity. Here, we explore a hardware-efficient dynamic inference regime, named dynamic weight slicing, which adaptively slice a part of network parameters for inputs with diverse difficulty levels, while keeping parameters stored statically and contiguously in hardware to prevent the extra burden of sparse computation. Based on this scheme, we present dynamic slimmable network (DS-Net) and dynamic slice-able network (DS-Net++) by input-dependently adjusting filter numbers of CNNs and multiple dimensions in both CNNs and transformers, respectively. To ensure sub-network generality and routing fairness, we propose a disentangled two-stage optimization scheme with training techniques such as in-place bootstrapping (IB), multi-view consistency (MvCo) and sandwich gate sparsification (SGS) to train supernet and gate separately. Extensive experiments on 4 datasets and 3 different network architectures demonstrate our method consistently outperforms state-of-the-art static and dynamic model compression methods by a large margin (up to 6.6%). Typically, DS-Net++ achieves 2-4x computation reduction and 1.62x real-world acceleration over MobileNet, ResNet-50 and Vision Transformer, with minimal accuracy drops (0.1-0.3%) on ImageNet. Code release: https://github.com/changlin31/DS-Net
Dynamic Slimmable Network
Mar 24, 2021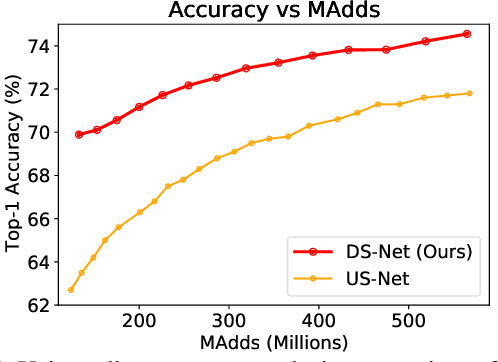

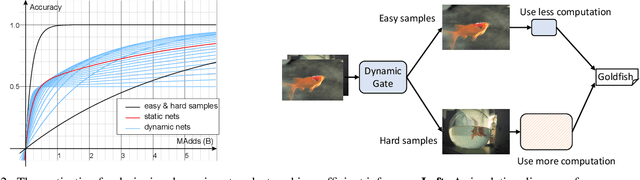
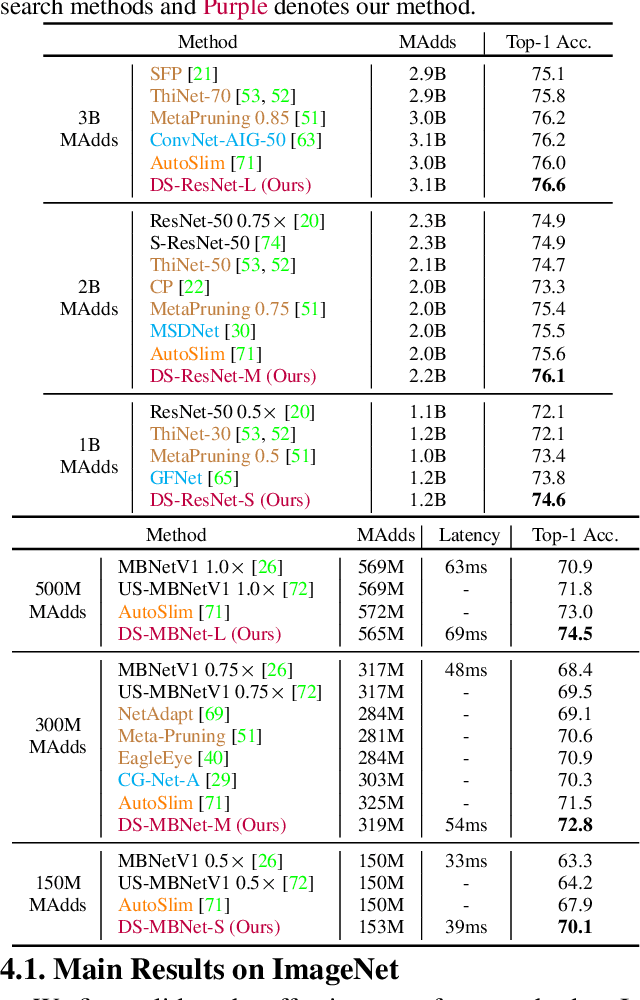
Current dynamic networks and dynamic pruning methods have shown their promising capability in reducing theoretical computation complexity. However, dynamic sparse patterns on convolutional filters fail to achieve actual acceleration in real-world implementation, due to the extra burden of indexing, weight-copying, or zero-masking. Here, we explore a dynamic network slimming regime, named Dynamic Slimmable Network (DS-Net), which aims to achieve good hardware-efficiency via dynamically adjusting filter numbers of networks at test time with respect to different inputs, while keeping filters stored statically and contiguously in hardware to prevent the extra burden. Our DS-Net is empowered with the ability of dynamic inference by the proposed double-headed dynamic gate that comprises an attention head and a slimming head to predictively adjust network width with negligible extra computation cost. To ensure generality of each candidate architecture and the fairness of gate, we propose a disentangled two-stage training scheme inspired by one-shot NAS. In the first stage, a novel training technique for weight-sharing networks named In-place Ensemble Bootstrapping is proposed to improve the supernet training efficacy. In the second stage, Sandwich Gate Sparsification is proposed to assist the gate training by identifying easy and hard samples in an online way. Extensive experiments demonstrate our DS-Net consistently outperforms its static counterparts as well as state-of-the-art static and dynamic model compression methods by a large margin (up to 5.9%). Typically, DS-Net achieves 2-4x computation reduction and 1.62x real-world acceleration over ResNet-50 and MobileNet with minimal accuracy drops on ImageNet. Code release: https://github.com/changlin31/DS-Net .
Scene Graphs: A Survey of Generations and Applications
Mar 17, 2021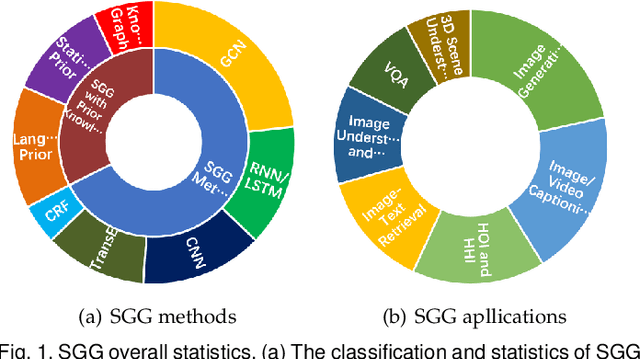

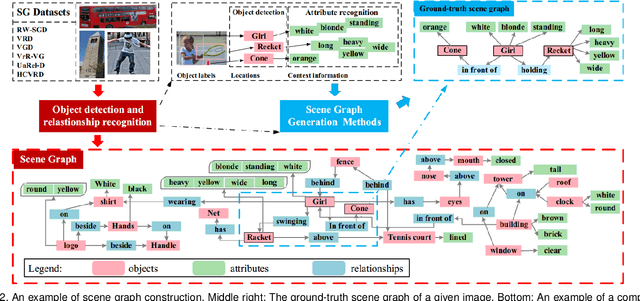
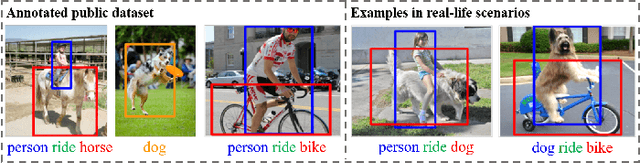
Scene graph is a structured representation of a scene that can clearly express the objects, attributes, and relationships between objects in the scene. As computer vision technology continues to develop, people are no longer satisfied with simply detecting and recognizing objects in images; instead, people look forward to a higher level of understanding and reasoning about visual scenes. For example, given an image, we want to not only detect and recognize objects in the image, but also know the relationship between objects (visual relationship detection), and generate a text description (image captioning) based on the image content. Alternatively, we might want the machine to tell us what the little girl in the image is doing (Visual Question Answering (VQA)), or even remove the dog from the image and find similar images (image editing and retrieval), etc. These tasks require a higher level of understanding and reasoning for image vision tasks. The scene graph is just such a powerful tool for scene understanding. Therefore, scene graphs have attracted the attention of a large number of researchers, and related research is often cross-modal, complex, and rapidly developing. However, no relatively systematic survey of scene graphs exists at present. To this end, this survey conducts a comprehensive investigation of the current scene graph research. More specifically, we first summarized the general definition of the scene graph, then conducted a comprehensive and systematic discussion on the generation method of the scene graph (SGG) and the SGG with the aid of prior knowledge. We then investigated the main applications of scene graphs and summarized the most commonly used datasets. Finally, we provide some insights into the future development of scene graphs. We believe this will be a very helpful foundation for future research on scene graphs.