 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Large Language Model Agents through Action Learning
Feb 24, 2024



Large Language Model (LLM) Agents have recently garnered increasing interest yet they are limited in their ability to learn from trial and error, a key element of intelligent behavior. In this work, we argue that the capacity to learn new actions from experience is fundamental to the advancement of learning in LLM agents. While humans naturally expand their action spaces and develop skills through experiential learning, LLM agents typically operate within fixed action spaces, limiting their potential for growth. To address these challenges, our study explores open-action learning for language agents. We introduce a framework LearnAct with an iterative learning strategy to create and improve actions in the form of Python functions. In each iteration, LLM revises and updates the currently available actions based on the errors identified in unsuccessful training tasks, thereby enhancing action effectiveness. Our experimental evaluations across Robotic Planning and Alfworld environments reveal that after learning on a few training task instances, our approach to open-action learning markedly improves agent performance for the type of task (by 32 percent in AlfWorld compared to ReAct+Reflexion, for instance) highlighting the importance of experiential action learning in the development of more intelligent LLM agents.
Revisiting the Parameter Efficiency of Adapters from the Perspective of Precision Redundancy
Jul 31, 2023



Current state-of-the-art results in computer vision depend in part on fine-tuning large pre-trained vision models. However, with the exponential growth of model sizes, the conventional full fine-tuning, which needs to store a individual network copy for each tasks, leads to increasingly huge storage and transmission overhead. Adapter-based Parameter-Efficient Tuning (PET) methods address this challenge by tuning lightweight adapters inserted into the frozen pre-trained models. In this paper, we investigate how to make adapters even more efficient, reaching a new minimum size required to store a task-specific fine-tuned network. Inspired by the observation that the parameters of adapters converge at flat local minima, we find that adapters are resistant to noise in parameter space, which means they are also resistant to low numerical precision. To train low-precision adapters, we propose a computational-efficient quantization method which minimizes the quantization error. Through extensive experiments, we find that low-precision adapters exhibit minimal performance degradation, and even 1-bit precision is sufficient for adapters. The experimental results demonstrate that 1-bit adapters outperform all other PET methods on both the VTAB-1K benchmark and few-shot FGVC tasks, while requiring the smallest storage size. Our findings show, for the first time, the significant potential of quantization techniques in PET, providing a general solution to enhance the parameter efficiency of adapter-based PET methods. Code: https://github.com/JieShibo/PETL-ViT
Dual-Alignment Pre-training for Cross-lingual Sentence Embedding
May 16, 2023



Recent studies have shown that dual encoder models trained with the sentence-level translation ranking task are effective methods for cross-lingual sentence embedding. However, our research indicates that token-level alignment is also crucial in multilingual scenarios, which has not been fully explored previously. Based on our findings, we propose a dual-alignment pre-training (DAP) framework for cross-lingual sentence embedding that incorporates both sentence-level and token-level alignment. To achieve this, we introduce a novel representation translation learning (RTL) task, where the model learns to use one-side contextualized token representation to reconstruct its translation counterpart. This reconstruction objective encourages the model to embed translation information into the token representation. Compared to other token-level alignment methods such as translation language modeling, RTL is more suitable for dual encoder architectures and is computationally efficient. Extensive experiments on three sentence-level cross-lingual benchmarks demonstrate that our approach can significantly improve sentence embedding. Our code is available at https://github.com/ChillingDream/DAP.
Masked Image Modeling with Local Multi-Scale Reconstruction
Mar 09, 2023Masked Image Modeling (MIM) achieves outstanding success in self-supervised representation learning. Unfortunately, MIM models typically have huge computational burden and slow learning process, which is an inevitable obstacle for their industrial applications. Although the lower layers play the key role in MIM, existing MIM models conduct reconstruction task only at the top layer of encoder. The lower layers are not explicitly guided and the interaction among their patches is only used for calculating new activations. Considering the reconstruction task requires non-trivial inter-patch interactions to reason target signals, we apply it to multiple local layers including lower and upper layers. Further, since the multiple layers expect to learn the information of different scales, we design local multi-scale reconstruction, where the lower and upper layers reconstruct fine-scale and coarse-scale supervision signals respectively. This design not only accelerates the representation learning process by explicitly guiding multiple layers, but also facilitates multi-scale semantical understanding to the input. Extensive experiments show that with significantly less pre-training burden, our model achieves comparable or better performance on classification, detection and segmentation tasks than existing MIM models.
Are More Layers Beneficial to Graph Transformers?
Mar 01, 2023Despite that going deep has proven successful in many neural architectures, the existing graph transformers are relatively shallow. In this work, we explore whether more layers are beneficial to graph transformers, and find that current graph transformers suffer from the bottleneck of improving performance by increasing depth. Our further analysis reveals the reason is that deep graph transformers are limited by the vanishing capacity of global attention, restricting the graph transformer from focusing on the critical substructure and obtaining expressive features. To this end, we propose a novel graph transformer model named DeepGraph that explicitly employs substructure tokens in the encoded representation, and applies local attention on related nodes to obtain substructure based attention encoding. Our model enhances the ability of the global attention to focus on substructures and promotes the expressiveness of the representations, addressing the limitation of self-attention as the graph transformer deepens. Experiments show that our method unblocks the depth limitation of graph transformers and results in state-of-the-art performance across various graph benchmarks with deeper models.
Detachedly Learn a Classifier for Class-Incremental Learning
Feb 23, 2023



In continual learning, model needs to continually learn a feature extractor and classifier on a sequence of tasks. This paper focuses on how to learn a classifier based on a pretrained feature extractor under continual learning setting. We present an probabilistic analysis that the failure of vanilla experience replay (ER) comes from unnecessary re-learning of previous tasks and incompetence to distinguish current task from the previous ones, which is the cause of knowledge degradation and prediction bias. To overcome these weaknesses, we propose a novel replay strategy task-aware experience replay. It rebalances the replay loss and detaches classifier weight for the old tasks from the update process, by which the previous knowledge is kept intact and the overfitting on episodic memory is alleviated. Experimental results show our method outperforms current state-of-the-art methods.
FacT: Factor-Tuning for Lightweight Adaptation on Vision Transformer
Dec 06, 2022Recent work has explored the potential to adapt a pre-trained vision transformer (ViT) by updating only a few parameters so as to improve storage efficiency, called parameter-efficient transfer learning (PETL). Current PETL methods have shown that by tuning only 0.5% of the parameters, ViT can be adapted to downstream tasks with even better performance than full fine-tuning. In this paper, we aim to further promote the efficiency of PETL to meet the extreme storage constraint in real-world applications. To this end, we propose a tensorization-decomposition framework to store the weight increments, in which the weights of each ViT are tensorized into a single 3D tensor, and their increments are then decomposed into lightweight factors. In the fine-tuning process, only the factors need to be updated and stored, termed Factor-Tuning (FacT). On VTAB-1K benchmark, our method performs on par with NOAH, the state-of-the-art PETL method, while being 5x more parameter-efficient. We also present a tiny version that only uses 8K (0.01% of ViT's parameters) trainable parameters but outperforms full fine-tuning and many other PETL methods such as VPT and BitFit. In few-shot settings, FacT also beats all PETL baselines using the fewest parameters, demonstrating its strong capability in the low-data regime.
Convolutional Bypasses Are Better Vision Transformer Adapters
Jul 18, 2022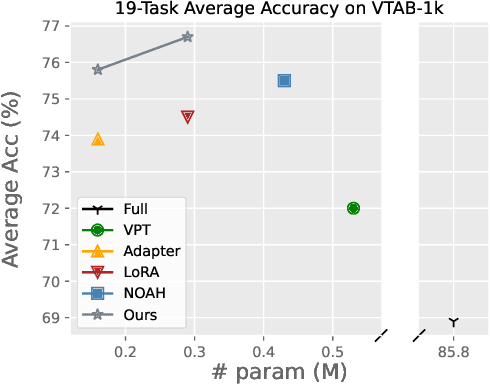
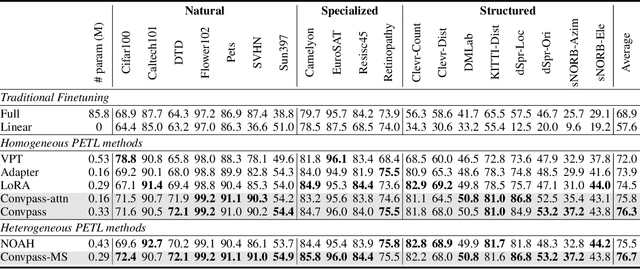
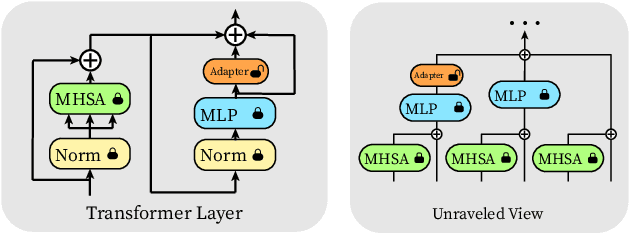
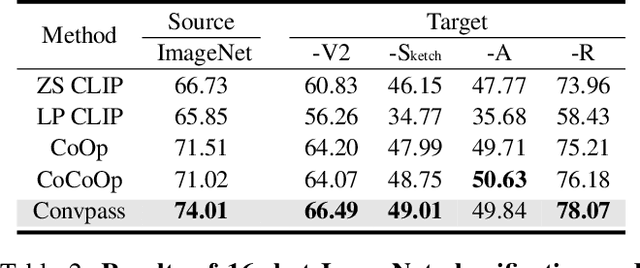
The pretrain-then-finetune paradigm has been widely adopted in computer vision. But as the size of Vision Transformer (ViT) grows exponentially, the full finetuning becomes prohibitive in view of the heavier storage overhead. Motivated by parameter-efficient transfer learning (PETL) on language transformers, recent studies attempt to insert lightweight adaptation modules (e.g., adapter layers or prompt tokens) to pretrained ViT and only finetune these modules while the pretrained weights are frozen. However, these modules were originally proposed to finetune language models. Although ported well to ViT, their design lacks prior knowledge for visual tasks. In this paper, we propose to construct Convolutional Bypasses (Convpass) in ViT as adaptation modules, introducing only a small amount (less than 0.5% of model parameters) of trainable parameters to adapt the large ViT. Different from other PETL methods, Convpass benefits from the hard-coded inductive bias of convolutional layers and thus is more suitable for visual tasks, especially in the low-data regime. Experimental results on VTAB-1k benchmark and few-shot learning datasets demonstrate that Convpass outperforms current language-oriented adaptation modules, demonstrating the necessity to tailor vision-oriented adaptation modules for vision models.
Certified Robustness Against Natural Language Attacks by Causal Intervention
May 26, 2022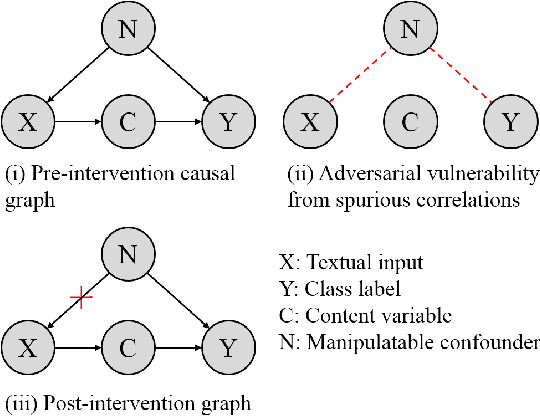
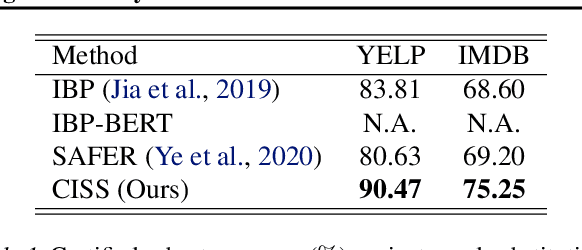
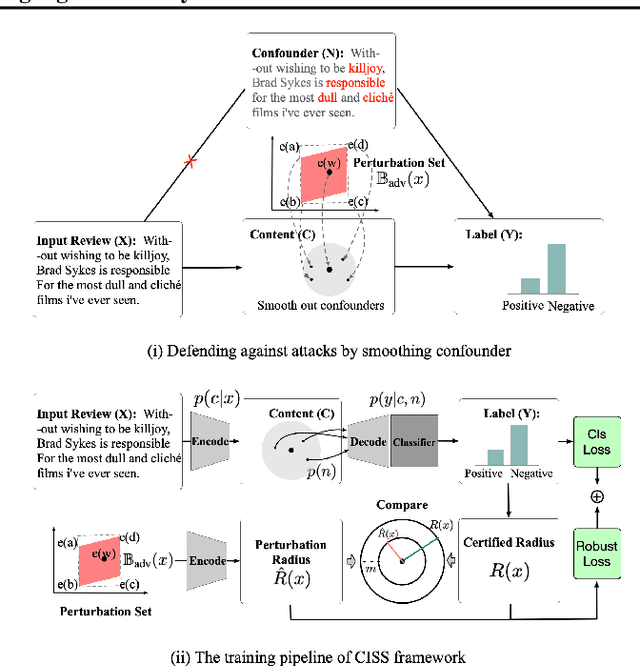
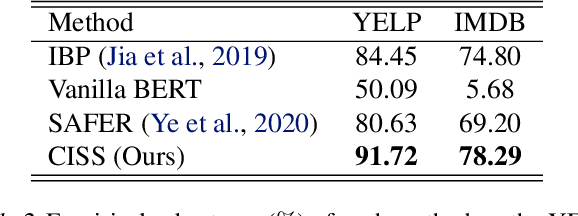
Deep learning models have achieved great success in many fields, yet they are vulnerable to adversarial examples. This paper follows a causal perspective to look into the adversarial vulnerability and proposes Causal Intervention by Semantic Smoothing (CISS), a novel framework towards robustness against natural language attacks. Instead of merely fitting observational data, CISS learns causal effects p(y|do(x)) by smoothing in the latent semantic space to make robust predictions, which scales to deep architectures and avoids tedious construction of noise customized for specific attacks. CISS is provably robust against word substitution attacks, as well as empirically robust even when perturbations are strengthened by unknown attack algorithms. For example, on YELP, CISS surpasses the runner-up by 6.7% in terms of certified robustness against word substitutions, and achieves 79.4% empirical robustness when syntactic attacks are integrated.
Bypassing Logits Bias in Online Class-Incremental Learning with a Generative Framework
May 19, 2022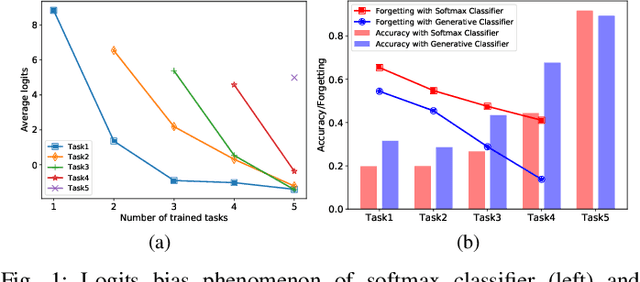
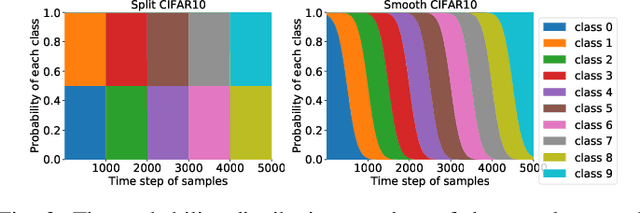
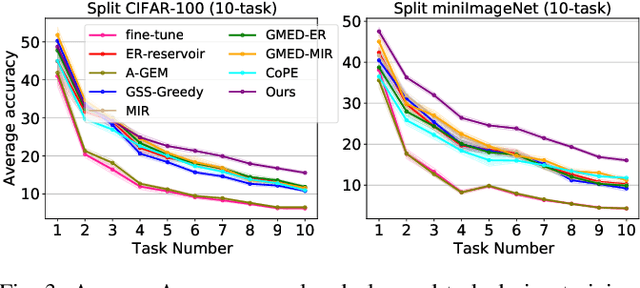
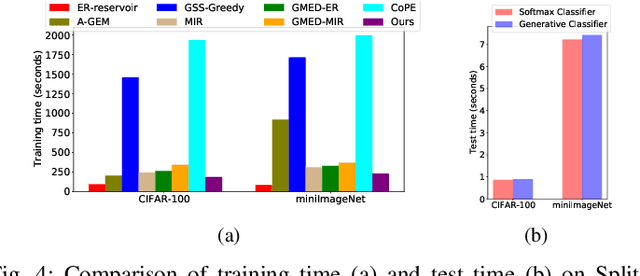
Continual learning requires the model to maintain the learned knowledge while learning from a non-i.i.d data stream continually. Due to the single-pass training setting, online continual learning is very challenging, but it is closer to the real-world scenarios where quick adaptation to new data is appealing. In this paper, we focus on online class-incremental learning setting in which new classes emerge over time. Almost all existing methods are replay-based with a softmax classifier. However, the inherent logits bias problem in the softmax classifier is a main cause of catastrophic forgetting while existing solutions are not applicable for online settings. To bypass this problem, we abandon the softmax classifier and propose a novel generative framework based on the feature space. In our framework, a generative classifier which utilizes replay memory is used for inference, and the training objective is a pair-based metric learning loss which is proven theoretically to optimize the feature space in a generative way. In order to improve the ability to learn new data, we further propose a hybrid of generative and discriminative loss to train the model. Extensive experiments on several benchmarks, including newly introduced task-free datasets, show that our method beats a series of state-of-the-art replay-based methods with discriminative classifiers, and reduces catastrophic forgetting consistently with a remarkable margin.