 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoDE: Effective Multi-task Parameter Efficient Fine-Tuning with a Mixture of Dyadic Experts
Aug 02, 2024Parameter-efficient fine-tuning techniques like Low-Rank Adaptation (LoRA) have revolutionized the adaptation of large language models (LLMs) to diverse tasks. Recent efforts have explored mixtures of LoRA modules for multi-task settings. However, our analysis reveals redundancy in the down-projection matrices of these architectures. This observation motivates our proposed method, Mixture of Dyadic Experts (MoDE), which introduces a novel design for efficient multi-task adaptation. This is done by sharing the down-projection matrix across tasks and employing atomic rank-one adapters, coupled with routers that allow more sophisticated task-level specialization. Our design allows for more fine-grained mixing, thereby increasing the model's ability to jointly handle multiple tasks. We evaluate MoDE on the Supernatural Instructions (SNI) benchmark consisting of a diverse set of 700+ tasks and demonstrate that it outperforms state-of-the-art multi-task parameter-efficient fine-tuning (PEFT) methods, without introducing additional parameters. Our findings contribute to a deeper understanding of parameter efficiency in multi-task LLM adaptation and provide a practical solution for deploying high-performing, lightweight models.
ImageArg: A Multi-modal Tweet Dataset for Image Persuasiveness Mining
Sep 14, 2022


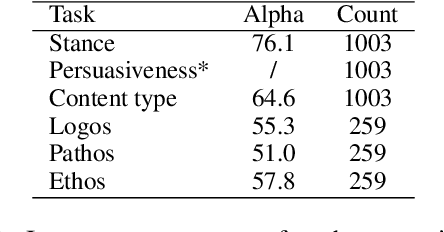
The growing interest in developing corpora of persuasive texts has promoted applications in automated systems, e.g., debating and essay scoring systems; however, there is little prior work mining image persuasiveness from an argumentative perspective. To expand persuasiveness mining into a multi-modal realm, we present a multi-modal dataset, ImageArg, consisting of annotations of image persuasiveness in tweets. The annotations are based on a persuasion taxonomy we developed to explore image functionalities and the means of persuasion. We benchmark image persuasiveness tasks on ImageArg using widely-used multi-modal learning methods. The experimental results show that our dataset offers a useful resource for this rich and challenging topic, and there is ample room for modeling improvement.
Inflating Topic Relevance with Ideology: A Case Study of Political Ideology Bias in Social Topic Detection Models
Nov 29, 2020
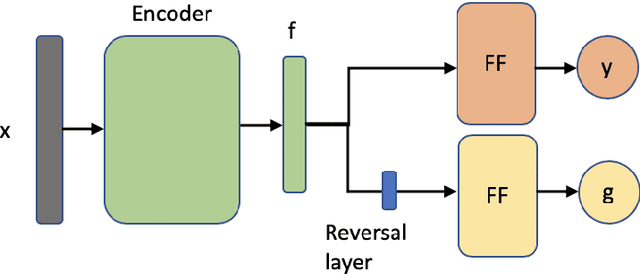
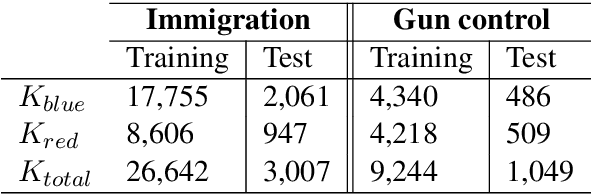
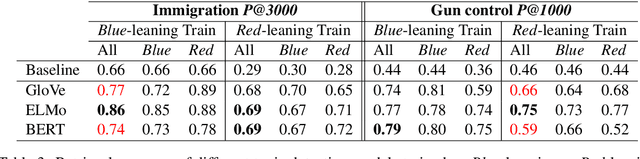
We investigate the impact of political ideology biases in training data. Through a set of comparison studies, we examine the propagation of biases in several widely-used NLP models and its effect on the overall retrieval accuracy. Our work highlights the susceptibility of large, complex models to propagating the biases from human-selected input, which may lead to a deterioration of retrieval accuracy, and the importance of controlling for these biases. Finally, as a way to mitigate the bias, we propose to learn a text representation that is invariant to political ideology while still judging topic relevance.