 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Insights into Bootstrapping for Bandits
May 24, 2018
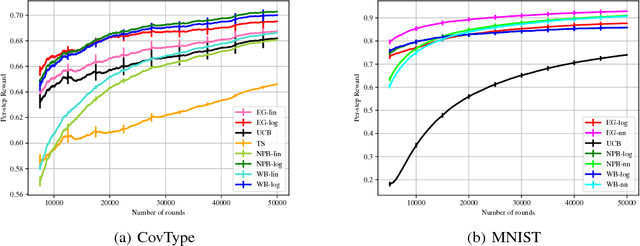


We investigate the use of bootstrapping in the bandit setting. We first show that the commonly used non-parametric bootstrapping (NPB) procedure can be provably inefficient and establish a near-linear lower bound on the regret incurred by it under the bandit model with Bernoulli rewards. We show that NPB with an appropriate amount of forced exploration can result in sub-linear albeit sub-optimal regret. As an alternative to NPB, we propose a weighted bootstrapping (WB) procedure. For Bernoulli rewards, WB with multiplicative exponential weights is mathematically equivalent to Thompson sampling (TS) and results in near-optimal regret bounds. Similarly, in the bandit setting with Gaussian rewards, we show that WB with additive Gaussian weights achieves near-optimal regret. Beyond these special cases, we show that WB leads to better empirical performance than TS for several reward distributions bounded on $[0,1]$. For the contextual bandit setting, we give practical guidelines that make bootstrapping simple and efficient to implement and result in good empirical performance on real-world datasets.
SpectralLeader: Online Spectral Learning for Single Topic Models
Apr 26, 2018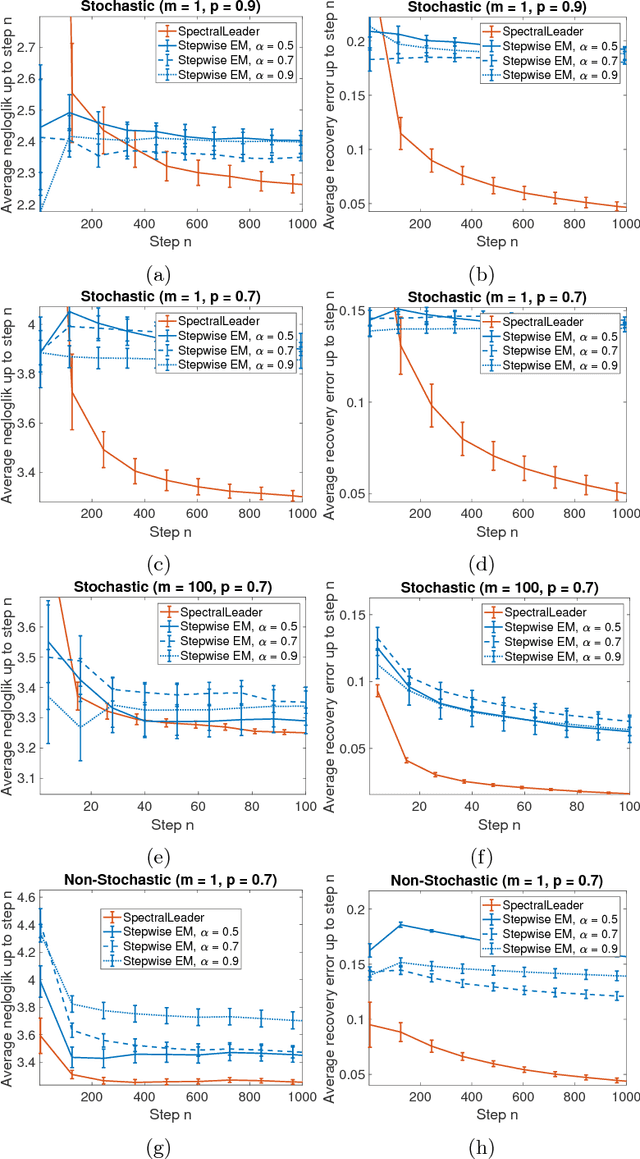
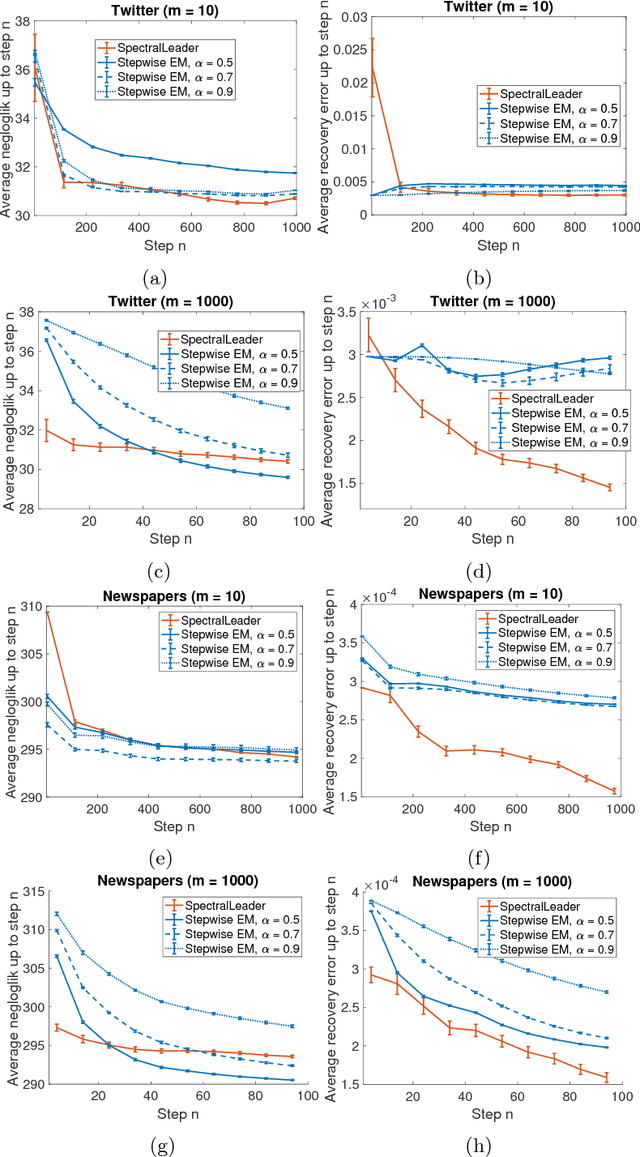
We study the problem of learning a latent variable model from a stream of data. Latent variable models are popular in practice because they can explain observed data in terms of unobserved concepts. These models have been traditionally studied in the offline setting. In the online setting, on the other hand, the online EM is arguably the most popular algorithm for learning latent variable models. Although the online EM is computationally efficient, it typically converges to a local optimum. In this work, we develop a new online learning algorithm for latent variable models, which we call SpectralLeader. SpectralLeader always converges to the global optimum, and we derive a sublinear upper bound on its $n$-step regret in the bag-of-words model. In both synthetic and real-world experiments, we show that SpectralLeader performs similarly to or better than the online EM with tuned hyper-parameters.
Nearly Optimal Adaptive Procedure for Piecewise-Stationary Bandit: a Change-Point Detection Approach
Feb 17, 2018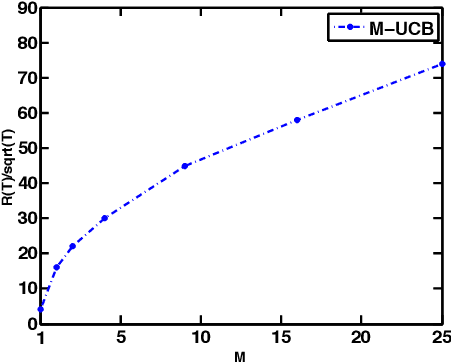
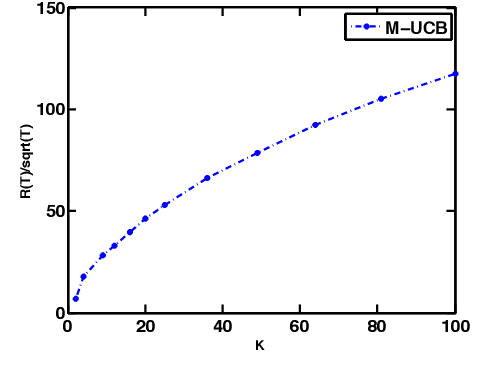
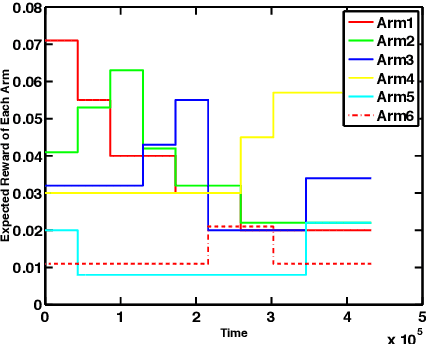
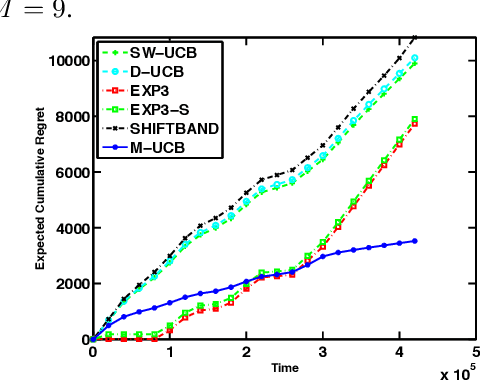
Multi-armed bandit (MAB) is a class of online learning problems where a learning agent aims to maximize its expected cumulative reward while repeatedly selecting to pull arms with unknown reward distributions. In this paper, we consider a scenario in which the arms' reward distributions may change in a piecewise-stationary fashion at unknown time steps. By connecting change-detection techniques with classic UCB algorithms, we motivate and propose a learning algorithm called M-UCB, which can detect and adapt to changes, for the considered scenario. We also establish an $O(\sqrt{MKT\log T})$ regret bound for M-UCB, where $T$ is the number of time steps, $K$ is the number of arms, and $M$ is the number of stationary segments. Comparison with the best available lower bound shows that M-UCB is nearly optimal in $T$ up to a logarithmic factor. We also compare M-UCB with state-of-the-art algorithms in a numerical experiment based on a public Yahoo! dataset. In this experiment, M-UCB achieves about $50 \%$ regret reduction with respect to the best performing state-of-the-art algorithm.
Stochastic Low-Rank Bandits
Dec 13, 2017
Many problems in computer vision and recommender systems involve low-rank matrices. In this work, we study the problem of finding the maximum entry of a stochastic low-rank matrix from sequential observations. At each step, a learning agent chooses pairs of row and column arms, and receives the noisy product of their latent values as a reward. The main challenge is that the latent values are unobserved. We identify a class of non-negative matrices whose maximum entry can be found statistically efficiently and propose an algorithm for finding them, which we call LowRankElim. We derive a $\DeclareMathOperator{\poly}{poly} O((K + L) \poly(d) \Delta^{-1} \log n)$ upper bound on its $n$-step regret, where $K$ is the number of rows, $L$ is the number of columns, $d$ is the rank of the matrix, and $\Delta$ is the minimum gap. The bound depends on other problem-specific constants that clearly do not depend $K L$. To the best of our knowledge, this is the first such result in the literature.
A Tutorial on Thompson Sampling
Nov 19, 2017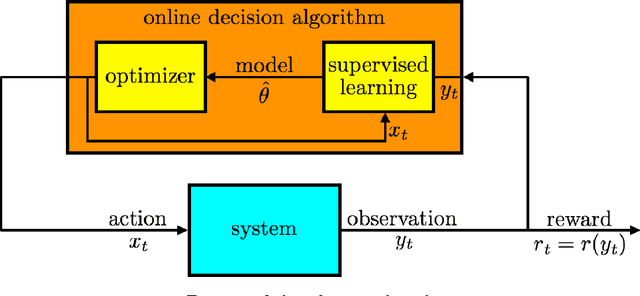
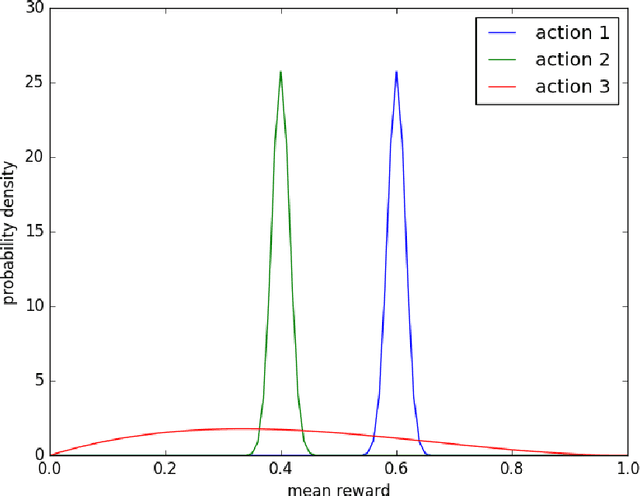
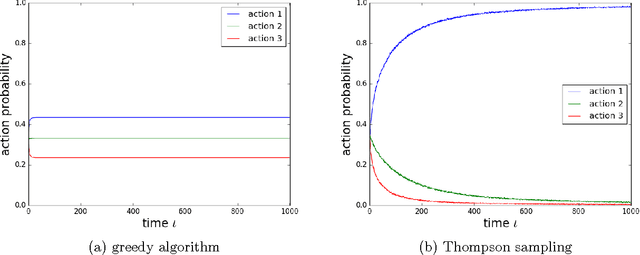
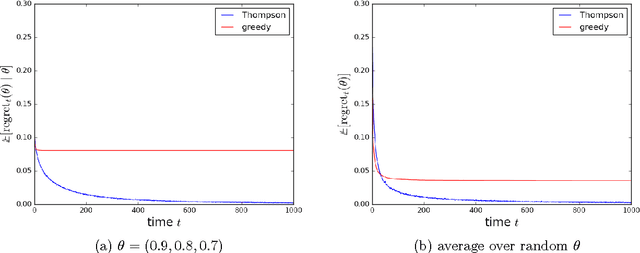
Thompson sampling is an algorithm for online decision problems where actions are taken sequentially in a manner that must balance between exploiting what is known to maximize immediate performance and investing to accumulate new information that may improve future performance. The algorithm addresses a broad range of problems in a computationally efficient manner and is therefore enjoying wide use. This tutorial covers the algorithm and its application, illustrating concepts through a range of examples, including Bernoulli bandit problems, shortest path problems, dynamic pricing, recommendation, active learning with neural networks, and reinforcement learning in Markov decision processes. Most of these problems involve complex information structures, where information revealed by taking an action informs beliefs about other actions. We will also discuss when and why Thompson sampling is or is not effective and relations to alternative algorithms.
Online Learning to Rank in Stochastic Click Models
Jun 20, 2017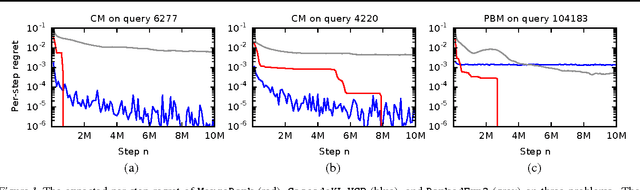
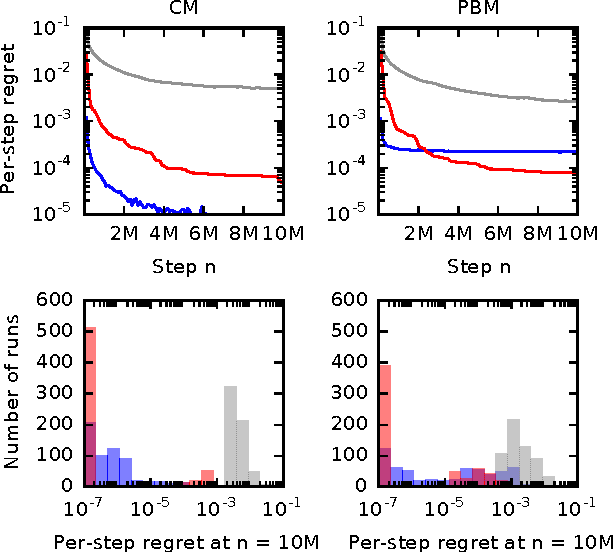
Online learning to rank is a core problem in information retrieval and machine learning. Many provably efficient algorithms have been recently proposed for this problem in specific click models. The click model is a model of how the user interacts with a list of documents. Though these results are significant, their impact on practice is limited, because all proposed algorithms are designed for specific click models and lack convergence guarantees in other models. In this work, we propose BatchRank, the first online learning to rank algorithm for a broad class of click models. The class encompasses two most fundamental click models, the cascade and position-based models. We derive a gap-dependent upper bound on the $T$-step regret of BatchRank and evaluate it on a range of web search queries. We observe that BatchRank outperforms ranked bandits and is more robust than CascadeKL-UCB, an existing algorithm for the cascade model.
Does Weather Matter? Causal Analysis of TV Logs
Mar 24, 2017
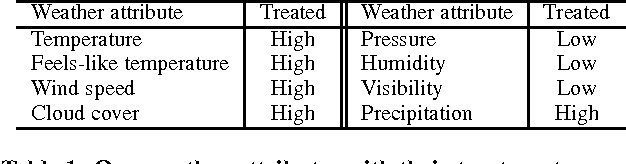
Weather affects our mood and behaviors, and many aspects of our life. When it is sunny, most people become happier; but when it rains, some people get depressed. Despite this evidence and the abundance of data, weather has mostly been overlooked in the machine learning and data science research. This work presents a causal analysis of how weather affects TV watching patterns. We show that some weather attributes, such as pressure and precipitation, cause major changes in TV watching patterns. To the best of our knowledge, this is the first large-scale causal study of the impact of weather on TV watching patterns.
Bernoulli Rank-$1$ Bandits for Click Feedback
Mar 19, 2017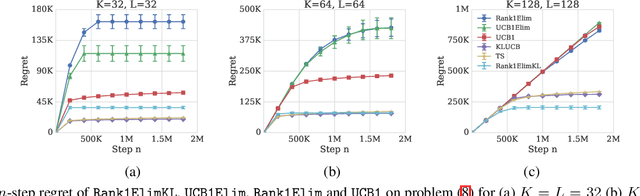
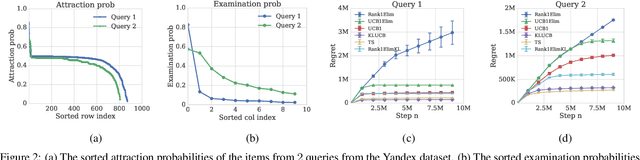
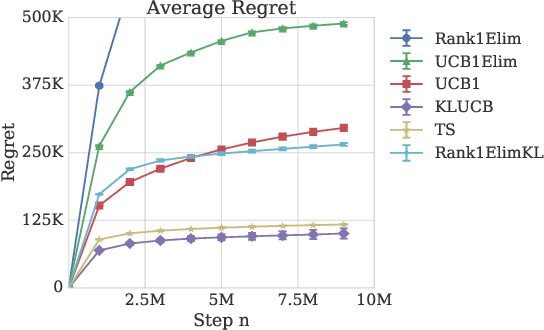
The probability that a user will click a search result depends both on its relevance and its position on the results page. The position based model explains this behavior by ascribing to every item an attraction probability, and to every position an examination probability. To be clicked, a result must be both attractive and examined. The probabilities of an item-position pair being clicked thus form the entries of a rank-$1$ matrix. We propose the learning problem of a Bernoulli rank-$1$ bandit where at each step, the learning agent chooses a pair of row and column arms, and receives the product of their Bernoulli-distributed values as a reward. This is a special case of the stochastic rank-$1$ bandit problem considered in recent work that proposed an elimination based algorithm Rank1Elim, and showed that Rank1Elim's regret scales linearly with the number of rows and columns on "benign" instances. These are the instances where the minimum of the average row and column rewards $\mu$ is bounded away from zero. The issue with Rank1Elim is that it fails to be competitive with straightforward bandit strategies as $\mu \rightarrow 0$. In this paper we propose Rank1ElimKL which simply replaces the (crude) confidence intervals of Rank1Elim with confidence intervals based on Kullback-Leibler (KL) divergences, and with the help of a novel result concerning the scaling of KL divergences we prove that with this change, our algorithm will be competitive no matter the value of $\mu$. Experiments with synthetic data confirm that on benign instances the performance of Rank1ElimKL is significantly better than that of even Rank1Elim, while experiments with models derived from real data confirm that the improvements are significant across the board, regardless of whether the data is benign or not.
Stochastic Rank-1 Bandits
Mar 08, 2017
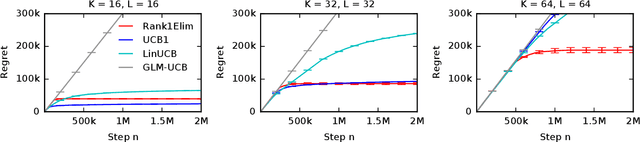
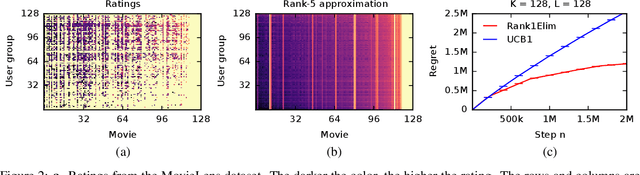
We propose stochastic rank-$1$ bandits, a class of online learning problems where at each step a learning agent chooses a pair of row and column arms, and receives the product of their values as a reward. The main challenge of the problem is that the individual values of the row and column are unobserved. We assume that these values are stochastic and drawn independently. We propose a computationally-efficient algorithm for solving our problem, which we call Rank1Elim. We derive a $O((K + L) (1 / \Delta) \log n)$ upper bound on its $n$-step regret, where $K$ is the number of rows, $L$ is the number of columns, and $\Delta$ is the minimum of the row and column gaps; under the assumption that the mean row and column rewards are bounded away from zero. To the best of our knowledge, we present the first bandit algorithm that finds the maximum entry of a rank-$1$ matrix whose regret is linear in $K + L$, $1 / \Delta$, and $\log n$. We also derive a nearly matching lower bound. Finally, we evaluate Rank1Elim empirically on multiple problems. We observe that it leverages the structure of our problems and can learn near-optimal solutions even if our modeling assumptions are mildly violated.
Efficient Learning in Large-Scale Combinatorial Semi-Bandits
Jan 31, 2017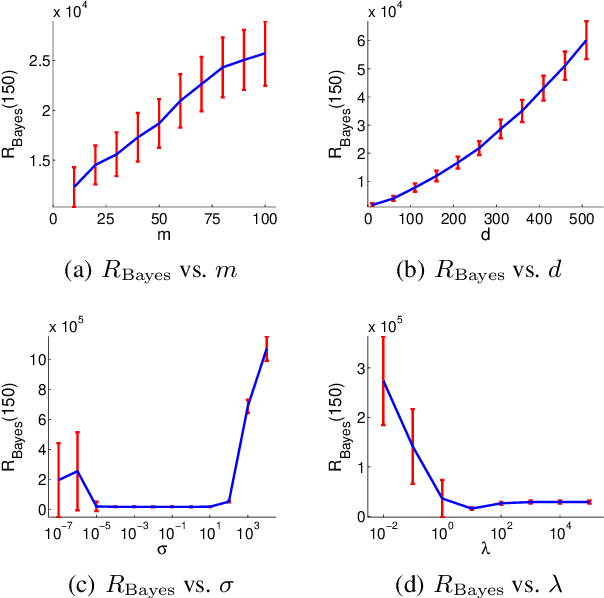
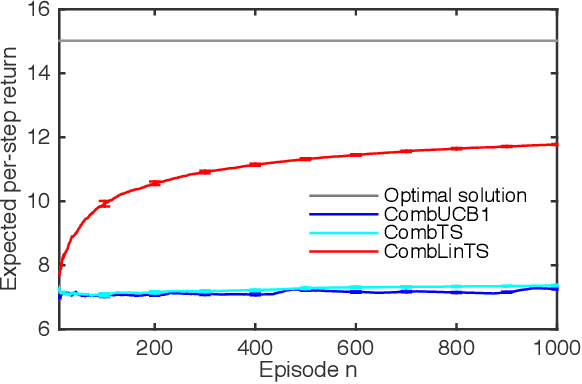
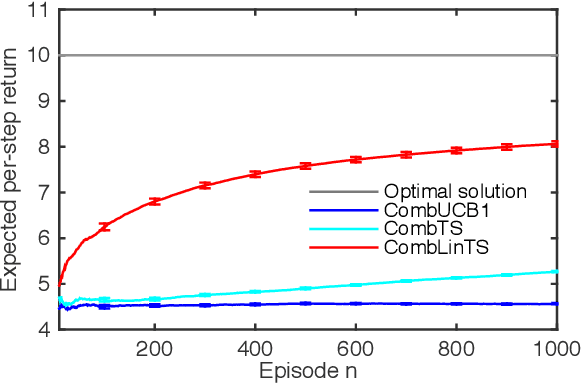
A stochastic combinatorial semi-bandit is an online learning problem where at each step a learning agent chooses a subset of ground items subject to combinatorial constraints, and then observes stochastic weights of these items and receives their sum as a payoff. In this paper, we consider efficient learning in large-scale combinatorial semi-bandits with linear generalization, and as a solution, propose two learning algorithms called Combinatorial Linear Thompson Sampling (CombLinTS) and Combinatorial Linear UCB (CombLinUCB). Both algorithms are computationally efficient as long as the offline version of the combinatorial problem can be solved efficiently. We establish that CombLinTS and CombLinUCB are also provably statistically efficient under reasonable assumptions, by developing regret bounds that are independent of the problem scale (number of items) and sublinear in time. We also evaluate CombLinTS on a variety of problems with thousands of items. Our experiment results demonstrate that CombLinTS is scalable, robust to the choice of algorithm parameters, and significantly outperforms the best of our baselines.