 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Online Learning with Probabilistic Graph Feedback
Mar 04, 2019We consider a problem of stochastic online learning with general probabilistic graph feedback. Two cases are covered. (a) The one-step case where for each edge $(i,j)$ with probability $p_{ij}$ in the probabilistic feedback graph. After playing arm $i$ the learner observes a sample reward feedback of arm $j$ with independent probability $p_{ij}$. (b) The cascade case where after playing arm $i$ the learner observes feedback of all arms $j$ in a probabilistic cascade starting from $i$ -- for each $(i,j)$ with probability $p_{ij}$, if arm $i$ is played or observed, then a reward sample of arm $j$ would be observed with independent probability $p_{ij}$. Previous works mainly focus on deterministic graphs which corresponds to one-step case with $p_{ij} \in \{0,1\}$, an adversarial sequence of graphs with certain topology guarantees or a specific type of random graphs. We analyze the asymptotic lower bounds and design algorithms in both cases. The regret upper bounds of the algorithms match the lower bounds with high probability.
Scalable Thompson Sampling via Optimal Transport
Feb 19, 2019

Thompson sampling (TS) is a class of algorithms for sequential decision-making, which requires maintaining a posterior distribution over a model. However, calculating exact posterior distributions is intractable for all but the simplest models. Consequently, efficient computation of an approximate posterior distribution is a crucial problem for scalable TS with complex models, such as neural networks. In this paper, we use distribution optimization techniques to approximate the posterior distribution, solved via Wasserstein gradient flows. Based on the framework, a principled particle-optimization algorithm is developed for TS to approximate the posterior efficiently. Our approach is scalable and does not make explicit distribution assumptions on posterior approximations. Extensive experiments on both synthetic data and real large-scale data demonstrate the superior performance of the proposed methods.
Garbage In, Reward Out: Bootstrapping Exploration in Multi-Armed Bandits
Nov 13, 2018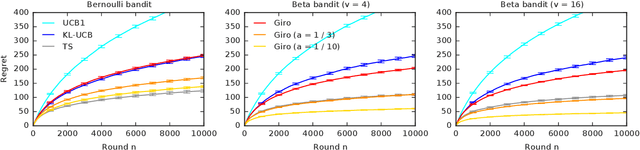
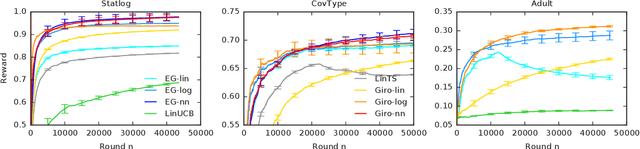
We propose a multi-armed bandit algorithm that explores based on randomizing its history. The key idea is to estimate the value of the arm from the bootstrap sample of its history, where we add pseudo observations after each pull of the arm. The pseudo observations seem to be harmful. But on the contrary, they guarantee that the bootstrap sample is optimistic with a high probability. Because of this, we call our algorithm Giro, which is an abbreviation for garbage in, reward out. We analyze Giro in a $K$-armed Bernoulli bandit and prove a $O(K \Delta^{-1} \log n)$ bound on its $n$-round regret, where $\Delta$ denotes the difference in the expected rewards of the optimal and best suboptimal arms. The main advantage of our exploration strategy is that it can be applied to any reward function generalization, such as neural networks. We evaluate Giro and its contextual variant on multiple synthetic and real-world problems, and observe that Giro is comparable to or better than state-of-the-art algorithms.
Online Diverse Learning to Rank from Partial-Click Feedback
Nov 01, 2018
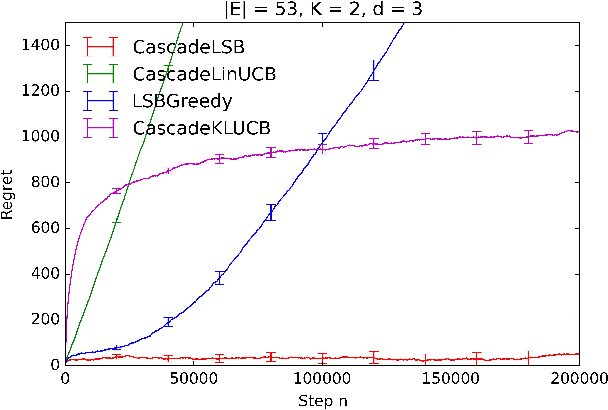

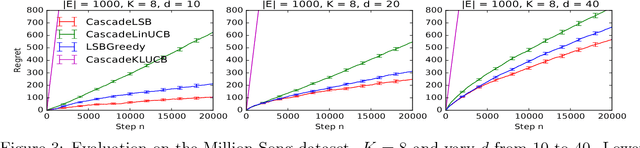
Learning to rank is an important problem in machine learning and recommender systems. In a recommender system, a user is typically recommended a list of items. Since the user is unlikely to examine the entire recommended list, partial feedback arises naturally. At the same time, diverse recommendations are important because it is challenging to model all tastes of the user in practice. In this paper, we propose the first algorithm for online learning to rank diverse items from partial-click feedback. We assume that the user examines the list of recommended items until the user is attracted by an item, which is clicked, and does not examine the rest of the items. This model of user behavior is known as the cascade model. We propose an online learning algorithm, cascadelsb, for solving our problem. The algorithm actively explores the tastes of the user with the objective of learning to recommend the optimal diverse list. We analyze the algorithm and prove a gap-free upper bound on its n-step regret. We evaluate cascadelsb on both synthetic and real-world datasets, compare it to various baselines, and show that it learns even when our modeling assumptions do not hold exactly.
Posterior Sampling for Large Scale Reinforcement Learning
Oct 22, 2018
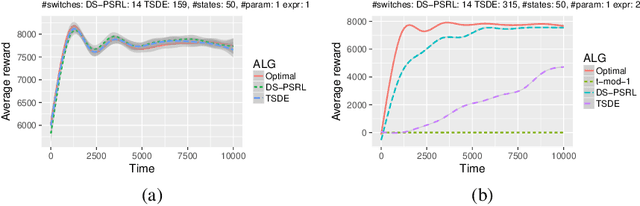
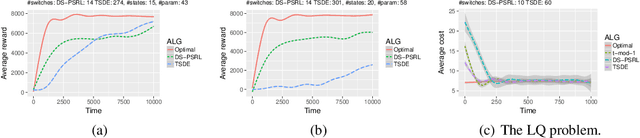
We propose a practical non-episodic PSRL algorithm that unlike recent state-of-the-art PSRL algorithms uses a deterministic, model-independent episode switching schedule. Our algorithm termed deterministic schedule PSRL (DS-PSRL) is efficient in terms of time, sample, and space complexity. We prove a Bayesian regret bound under mild assumptions. Our result is more generally applicable to multiple parameters and continuous state action problems. We compare our algorithm with state-of-the-art PSRL algorithms on standard discrete and continuous problems from the literature. Finally, we show how the assumptions of our algorithm satisfy a sensible parametrization for a large class of problems in sequential recommendations.
Online Influence Maximization under Independent Cascade Model with Semi-Bandit Feedback
Jun 19, 2018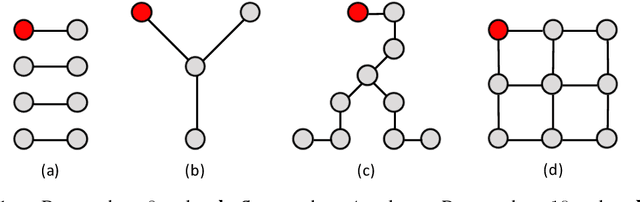
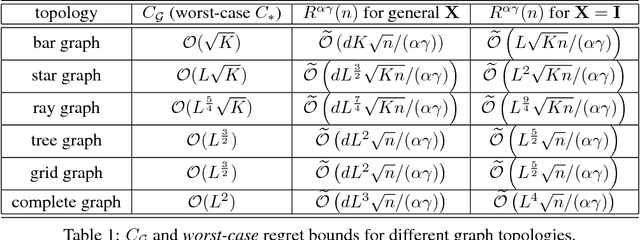
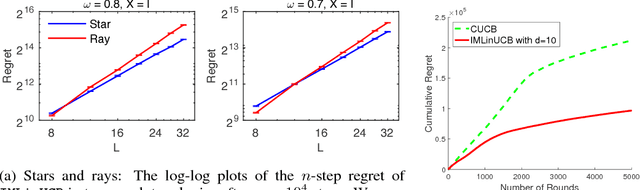
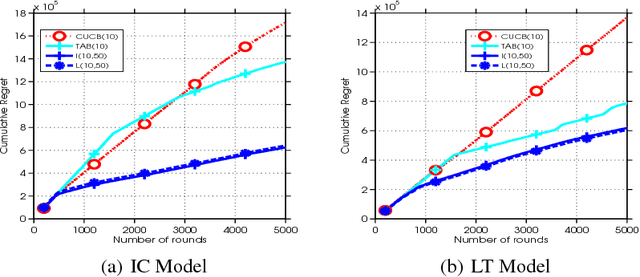
We study the online influence maximization problem in social networks under the independent cascade model. Specifically, we aim to learn the set of "best influencers" in a social network online while repeatedly interacting with it. We address the challenges of (i) combinatorial action space, since the number of feasible influencer sets grows exponentially with the maximum number of influencers, and (ii) limited feedback, since only the influenced portion of the network is observed. Under a stochastic semi-bandit feedback, we propose and analyze IMLinUCB, a computationally efficient UCB-based algorithm. Our bounds on the cumulative regret are polynomial in all quantities of interest, achieve near-optimal dependence on the number of interactions and reflect the topology of the network and the activation probabilities of its edges, thereby giving insights on the problem complexity. To the best of our knowledge, these are the first such results. Our experiments show that in several representative graph topologies, the regret of IMLinUCB scales as suggested by our upper bounds. IMLinUCB permits linear generalization and thus is both statistically and computationally suitable for large-scale problems. Our experiments also show that IMLinUCB with linear generalization can lead to low regret in real-world online influence maximization.
* Compared with the previous version, this version has fixed a mistake. This version is also consistent with the NIPS camera-ready version
Offline Evaluation of Ranking Policies with Click Models
Jun 13, 2018

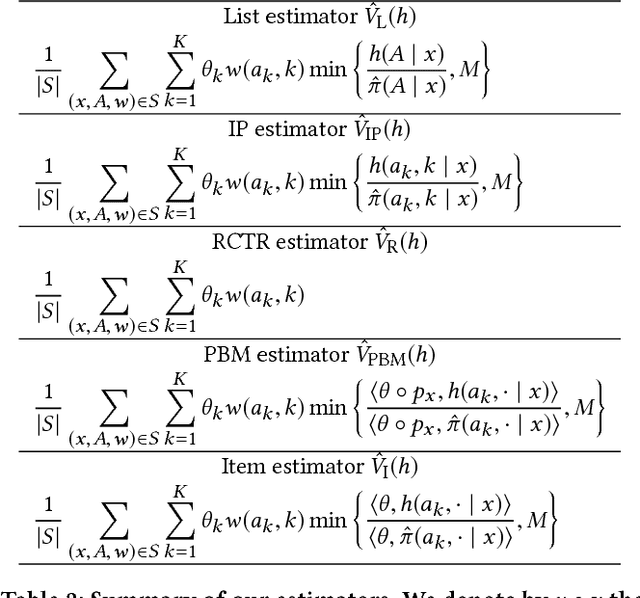
Many web systems rank and present a list of items to users, from recommender systems to search and advertising. An important problem in practice is to evaluate new ranking policies offline and optimize them before they are deployed. We address this problem by proposing evaluation algorithms for estimating the expected number of clicks on ranked lists from historical logged data. The existing algorithms are not guaranteed to be statistically efficient in our problem because the number of recommended lists can grow exponentially with their length. To overcome this challenge, we use models of user interaction with the list of items, the so-called click models, to construct estimators that learn statistically efficiently. We analyze our estimators and prove that they are more efficient than the estimators that do not use the structure of the click model, under the assumption that the click model holds. We evaluate our estimators in a series of experiments on a real-world dataset and show that they consistently outperform prior estimators.
Deep Exploration via Randomized Value Functions
Jun 06, 2018
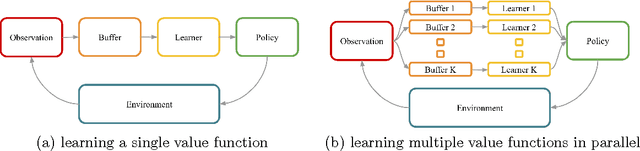
We study the use of randomized value functions to guide deep exploration in reinforcement learning. This offers an elegant means for synthesizing statistically and computationally efficient exploration with common practical approaches to value function learning. We present several reinforcement learning algorithms that leverage randomized value functions and demonstrate their efficacy through computational studies. We also prove a regret bound that establishes statistical efficiency with a tabular representation.
Conservative Exploration using Interleaving
Jun 03, 2018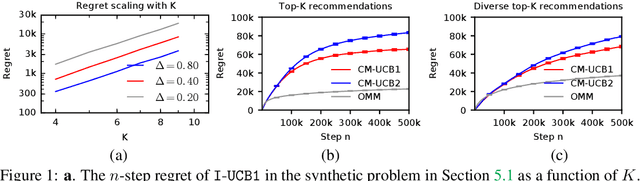
In many practical problems, a learning agent may want to learn the best action in hindsight without ever taking a bad action, which is significantly worse than the default production action. In general, this is impossible because the agent has to explore unknown actions, some of which can be bad, to learn better actions. However, when the actions are combinatorial, this may be possible if the unknown action can be evaluated by interleaving it with the production action. We formalize this concept as learning in stochastic combinatorial semi-bandits with exchangeable actions. We design efficient learning algorithms for this problem, bound their n-step regret, and evaluate them on both synthetic and real-world problems. Our real-world experiments show that our algorithms can learn to recommend K most attractive movies without ever violating a strict production constraint, both overall and subject to a diversity constraint.
Model-Independent Online Learning for Influence Maximization
May 24, 2018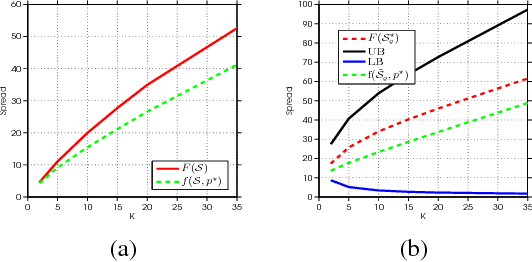
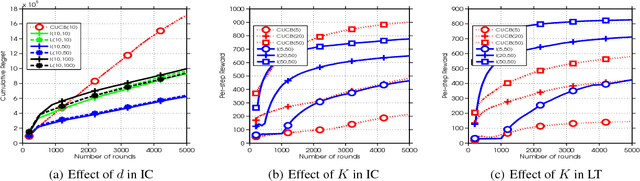
We consider influence maximization (IM) in social networks, which is the problem of maximizing the number of users that become aware of a product by selecting a set of "seed" users to expose the product to. While prior work assumes a known model of information diffusion, we propose a novel parametrization that not only makes our framework agnostic to the underlying diffusion model, but also statistically efficient to learn from data. We give a corresponding monotone, submodular surrogate function, and show that it is a good approximation to the original IM objective. We also consider the case of a new marketer looking to exploit an existing social network, while simultaneously learning the factors governing information propagation. For this, we propose a pairwise-influence semi-bandit feedback model and develop a LinUCB-based bandit algorithm. Our model-independent analysis shows that our regret bound has a better (as compared to previous work) dependence on the size of the network. Experimental evaluation suggests that our framework is robust to the underlying diffusion model and can efficiently learn a near-optimal solution.