 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE-ORNet: Self-Ensembling Orientation-aware Network for Unsupervised Point Cloud Shape Correspondence
Apr 10, 2023



Unsupervised point cloud shape correspondence aims to obtain dense point-to-point correspondences between point clouds without manually annotated pairs. However, humans and some animals have bilateral symmetry and various orientations, which lead to severe mispredictions of symmetrical parts. Besides, point cloud noise disrupts consistent representations for point cloud and thus degrades the shape correspondence accuracy. To address the above issues, we propose a Self-Ensembling ORientation-aware Network termed SE-ORNet. The key of our approach is to exploit an orientation estimation module with a domain adaptive discriminator to align the orientations of point cloud pairs, which significantly alleviates the mispredictions of symmetrical parts. Additionally, we design a selfensembling framework for unsupervised point cloud shape correspondence. In this framework, the disturbances of point cloud noise are overcome by perturbing the inputs of the student and teacher networks with different data augmentations and constraining the consistency of predictions. Extensive experiments on both human and animal datasets show that our SE-ORNet can surpass state-of-the-art unsupervised point cloud shape correspondence methods.
MF-JMoDL-Net: A Deep Network for Azimuth Undersampling Pattern Design and Ambiguity Suppression for Sparse SAR Imaging
Mar 20, 2023repetition frequency (PRF). Given the system complexity and resource constraints, it is often difficult to achieve high imaging performance and low ambiguity without compromising the swath. In this paper, we propose a joint optimization framework for sparse strip SAR imaging algorithms and azimuth undersampling patterns based on a deep convolutional neural network, combined with matched filter (MF) approximate measurement operators and inverse MF operators, referred to as MF-JMoDL-Net, for sparse SAR imaging methods. Compared with conventional sparse SAR imaging, MF-JMoDL-Net enables us to alleviate the limitations imposed by PRF. In the proposed scheme, joint and continuous optimization of azimuth undersampling patterns and convolutional neural network parameters are implemented to suppress azimuth ambiguity and enhance sparse SAR imaging quality. Experiments and comparisons under various conditions demonstrate the effectiveness and superiority of the proposed framework in imaging results.
Efficient Gridless DoA Estimation Method of Non-uniform Linear Arrays with Applications in Automotive Radars
Mar 08, 2023



This paper focuses on the gridless direction-of-arrival (DoA) estimation for data acquired by non-uniform linear arrays (NLAs) in automotive applications. Atomic norm minimization (ANM) is a promising gridless sparse recovery algorithm under the Toeplitz model and solved by convex relaxation, thus it is only applicable to uniform linear arrays (ULAs) with array manifolds having a Vandermonde structure. In automotive applications, it is essential to apply the gridless DoA estimation to NLAs with arbitrary geometry with efficiency. In this paper, a fast ANM-based gridless DoA estimation algorithm for NLAs is proposed, which employs the array manifold separation technique and the accelerated proximal gradient (APG) technique, making it applicable to NLAs without losing of efficiency. Simulation and measurement experiments on automotive multiple-input multiple-output (MIMO) radars demonstrate the superiority of the proposed method.
Coincident Learning for Unsupervised Anomaly Detection
Jan 26, 2023



Anomaly detection is an important task for complex systems (e.g., industrial facilities, manufacturing, large-scale science experiments), where failures in a sub-system can lead to low yield, faulty products, or even damage to components. While complex systems often have a wealth of data, labeled anomalies are typically rare (or even nonexistent) and expensive to acquire. In this paper, we introduce a new method, called CoAD, for training anomaly detection models on unlabeled data, based on the expectation that anomalous behavior in one sub-system will produce coincident anomalies in downstream sub-systems and products. Given data split into two streams $s$ and $q$ (i.e., subsystem diagnostics and final product quality), we define an unsupervised metric, $\hat{F}_\beta$, out of analogy to the supervised classification $F_\beta$ statistic, which quantifies the performance of the independent anomaly detection algorithms on s and q based on their coincidence rate. We demonstrate our method in four cases: a synthetic time-series data set, a synthetic imaging data set generated from MNIST, a metal milling data set, and a data set taken from a particle accelerator.
Deep Attention-Based Alignment Network for Melody Generation from Incomplete Lyrics
Jan 23, 2023



We propose a deep attention-based alignment network, which aims to automatically predict lyrics and melody with given incomplete lyrics as input in a way similar to the music creation of humans. Most importantly, a deep neural lyrics-to-melody net is trained in an encoder-decoder way to predict possible pairs of lyrics-melody when given incomplete lyrics (few keywords). The attention mechanism is exploited to align the predicted lyrics with the melody during the lyrics-to-melody generation. The qualitative and quantitative evaluation metrics reveal that the proposed method is indeed capable of generating proper lyrics and corresponding melody for composing new songs given a piece of incomplete seed lyrics.
A novel TomoSAR imaging method with few observations based on nested array
Dec 01, 2022



Synthetic aperture radar tomography (TomoSAR) baseline optimization technique is capable of reducing system complexity and improving the temporal coherence of data, which has become an important research in the field of TomoSAR. In this paper, we propose a nested TomoSAR technique, which introduces the nested array into TomoSAR as the baseline configuration. This technique obtains uniform and continuous difference co-array through nested array to increase the degrees of freedom (DoF) of the system and expands the virtual aperture along the elevation direction. In order to make full use of the difference co-array, covariance matrix of the echo needs to be obtained. Therefore, we propose a TomoSAR sparse reconstruction algorithm based on nested array, which uses adaptive covariance matrix estimation to improve the estimation performance in complex scenes. We demonstrate the effectiveness of the proposed method through simulated and real data experiments. Compared with traditional TomoSAR and coprime TomoSAR, the imaging results of our proposed method have a better anti-noise performance and retain more image information.
ATASI-Net: An Efficient Sparse Reconstruction Network for Tomographic SAR Imaging with Adaptive Threshold
Nov 30, 2022



Tomographic SAR technique has attracted remarkable interest for its ability of three-dimensional resolving along the elevation direction via a stack of SAR images collected from different cross-track angles. The emerged compressed sensing (CS)-based algorithms have been introduced into TomoSAR considering its super-resolution ability with limited samples. However, the conventional CS-based methods suffer from several drawbacks, including weak noise resistance, high computational complexity, and complex parameter fine-tuning. Aiming at efficient TomoSAR imaging, this paper proposes a novel efficient sparse unfolding network based on the analytic learned iterative shrinkage thresholding algorithm (ALISTA) architecture with adaptive threshold, named Adaptive Threshold ALISTA-based Sparse Imaging Network (ATASI-Net). The weight matrix in each layer of ATASI-Net is pre-computed as the solution of an off-line optimization problem, leaving only two scalar parameters to be learned from data, which significantly simplifies the training stage. In addition, adaptive threshold is introduced for each azimuth-range pixel, enabling the threshold shrinkage to be not only layer-varied but also element-wise. Moreover, the final learned thresholds can be visualized and combined with the SAR image semantics for mutual feedback. Finally, extensive experiments on simulated and real data are carried out to demonstrate the effectiveness and efficiency of the proposed method.
Fault Diagnosis for Power Electronics Converters based on Deep Feedforward Network and Wavelet Compression
Oct 27, 2022



A fault diagnosis method for power electronics converters based on deep feedforward network and wavelet compression is proposed in this paper. The transient historical data after wavelet compression are used to realize the training of fault diagnosis classifier. Firstly, the correlation analysis of the voltage or current data running in various fault states is performed to remove the redundant features and the sampling point. Secondly, the wavelet transform is used to remove the redundant data of the features, and then the training sample data is greatly compressed. The deep feedforward network is trained by the low frequency component of the features, while the training speed is greatly accelerated. The average accuracy of fault diagnosis classifier can reach over 97%. Finally, the fault diagnosis classifier is tested, and final diagnosis result is determined by multiple-groups transient data, by which the reliability of diagnosis results is improved. The experimental result proves that the classifier has strong generalization ability and can accurately locate the open-circuit faults in IGBTs.
Review for AI-based Open-Circuit Faults Diagnosis Methods in Power Electronics Converters
Sep 26, 2022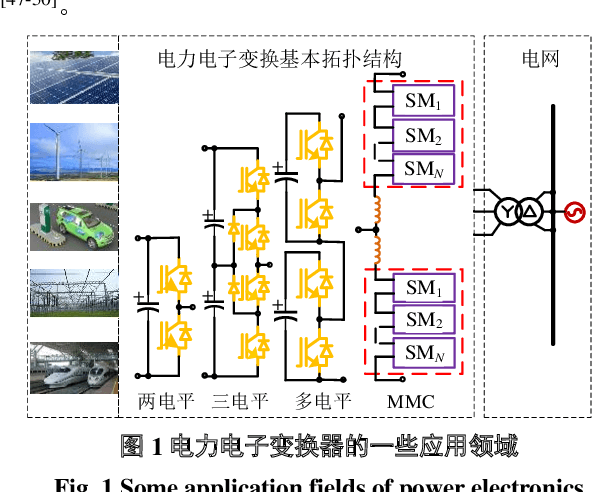
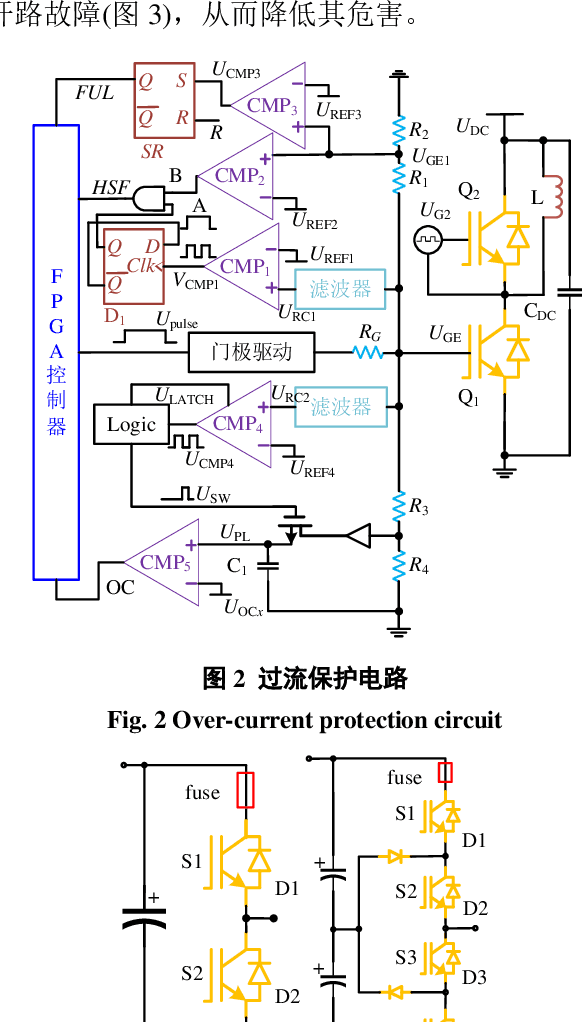
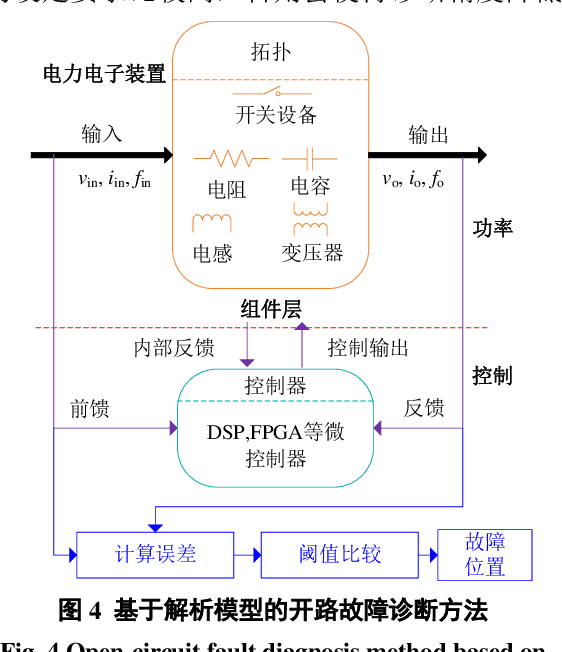
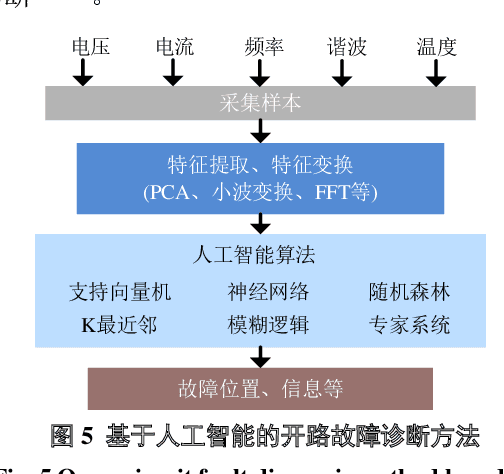
Power electronics converters have been widely used in aerospace system, DC transmission, distributed energy, smart grid and so forth, and the reliability of power electronics converters has been a hotspot in academia and industry. It is of great significance to carry out power electronics converters open-circuit faults monitoring and intelligent fault diagnosis to avoid secondary faults, reduce time and cost of operation and maintenance, and improve the reliability of power electronics system. Firstly, the faults features of power electronic converters are analyzed and summarized. Secondly, some AI-based fault diagnosis methods and application examples in power electronics converters are reviewed, and a fault diagnosis method based on the combination of random forests and transient fault features is proposed for three-phase power electronics converters. Finally, the future research challenges and directions of AI-based fault diagnosis methods are pointed out.
M$^2$DQN: A Robust Method for Accelerating Deep Q-learning Network
Sep 16, 2022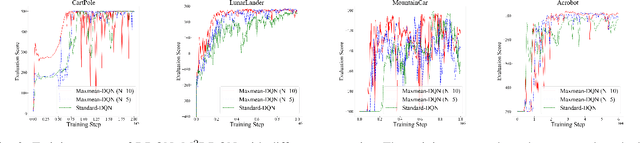
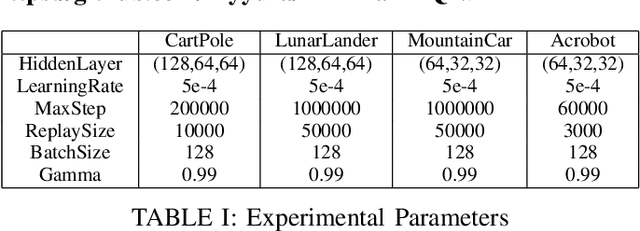
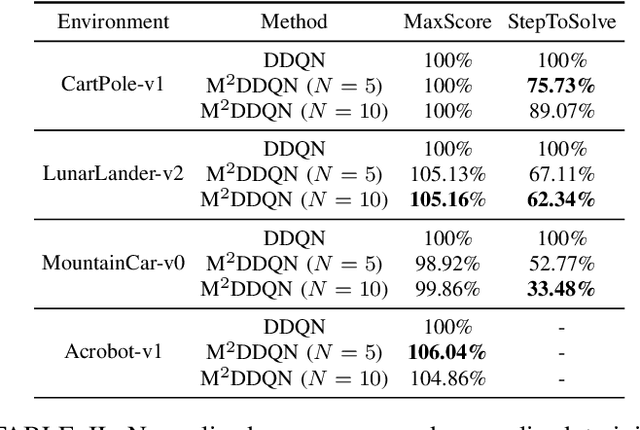
Deep Q-learning Network (DQN) is a successful way which combines reinforcement learning with deep neural networks and leads to a widespread application of reinforcement learning. One challenging problem when applying DQN or other reinforcement learning algorithms to real world problem is data collection. Therefore, how to improve data efficiency is one of the most important problems in the research of reinforcement learning. In this paper, we propose a framework which uses the Max-Mean loss in Deep Q-Network (M$^2$DQN). Instead of sampling one batch of experiences in the training step, we sample several batches from the experience replay and update the parameters such that the maximum TD-error of these batches is minimized. The proposed method can be combined with most of existing techniques of DQN algorithm by replacing the loss function. We verify the effectiveness of this framework with one of the most widely used techniques, Double DQN (DDQN), in several gym games. The results show that our method leads to a substantial improvement in both the learning speed and performance.