 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Perceptron: Towards End-to-End Arbitrary-Shaped Text Spotting
Feb 17, 2020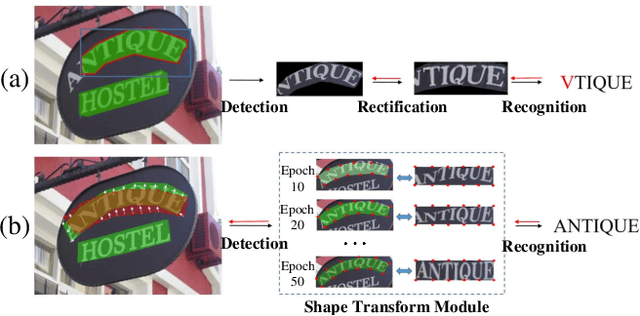
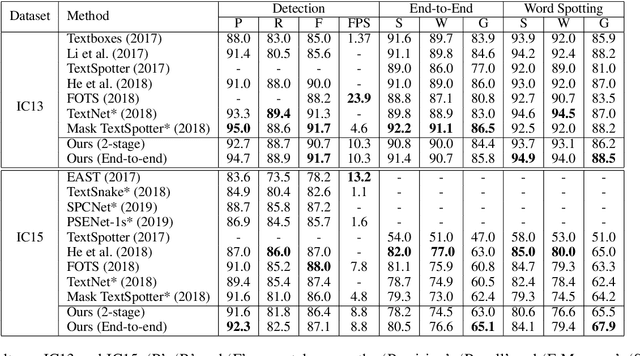
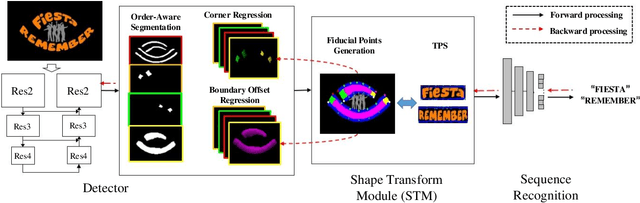
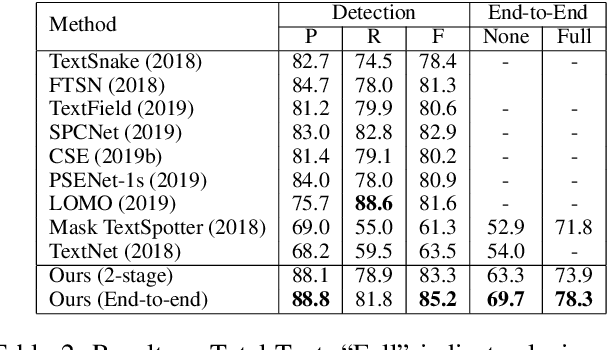
Many approaches have recently been proposed to detect irregular scene text and achieved promising results. However, their localization results may not well satisfy the following text recognition part mainly because of two reasons: 1) recognizing arbitrary shaped text is still a challenging task, and 2) prevalent non-trainable pipeline strategies between text detection and text recognition will lead to suboptimal performances. To handle this incompatibility problem, in this paper we propose an end-to-end trainable text spotting approach named Text Perceptron. Concretely, Text Perceptron first employs an efficient segmentation-based text detector that learns the latent text reading order and boundary information. Then a novel Shape Transform Module (abbr. STM) is designed to transform the detected feature regions into regular morphologies without extra parameters. It unites text detection and the following recognition part into a whole framework, and helps the whole network achieve global optimization. Experiments show that our method achieves competitive performance on two standard text benchmarks, i.e., ICDAR 2013 and ICDAR 2015, and also obviously outperforms existing methods on irregular text benchmarks SCUT-CTW1500 and Total-Text.
Adversarial Seeded Sequence Growing for Weakly-Supervised Temporal Action Localization
Aug 07, 2019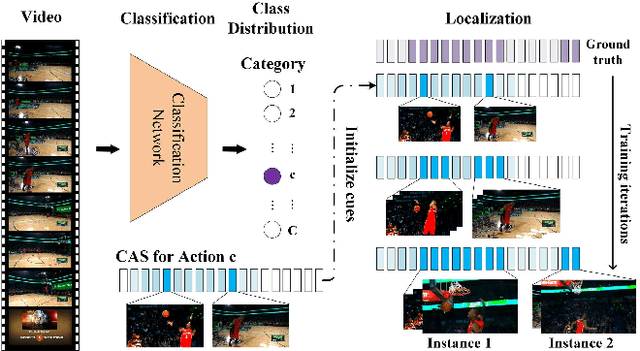
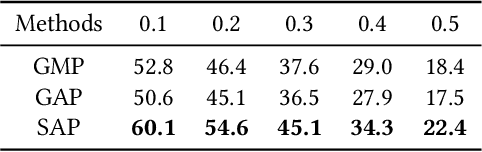
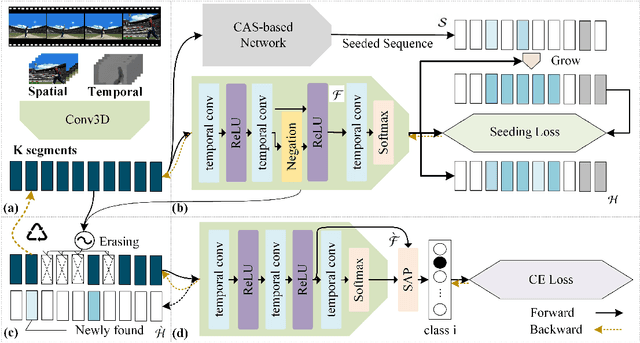
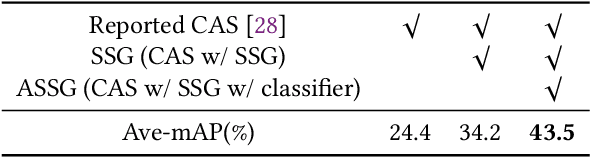
Temporal action localization is an important yet challenging research topic due to its various applications. Since the frame-level or segment-level annotations of untrimmed videos require amounts of labor expenditure, studies on the weakly-supervised action detection have been springing up. However, most of existing frameworks rely on Class Activation Sequence (CAS) to localize actions by minimizing the video-level classification loss, which exploits the most discriminative parts of actions but ignores the minor regions. In this paper, we propose a novel weakly-supervised framework by adversarial learning of two modules for eliminating such demerits. Specifically, the first module is designed as a well-designed Seeded Sequence Growing (SSG) Network for progressively extending seed regions (namely the highly reliable regions initialized by a CAS-based framework) to their expected boundaries. The second module is a specific classifier for mining trivial or incomplete action regions, which is trained on the shared features after erasing the seeded regions activated by SSG. In this way, a whole network composed of these two modules can be trained in an adversarial manner. The goal of the adversary is to mine features that are difficult for the action classifier. That is, erasion from SSG will force the classifier to discover minor or even new action regions on the input feature sequence, and the classifier will drive the seeds to grow, alternately. At last, we could obtain the action locations and categories from the well-trained SSG and the classifier. Extensive experiments on two public benchmarks THUMOS'14 and ActivityNet1.3 demonstrate the impressive performance of our proposed method compared with the state-of-the-arts.
REAPS: Towards Better Recognition of Fine-grained Images by Region Attending and Part Sequencing
Aug 06, 2019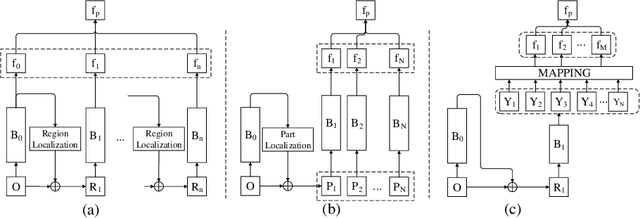
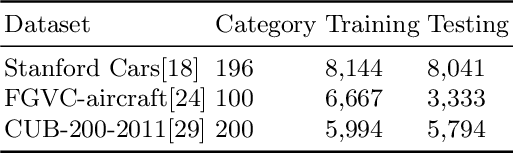

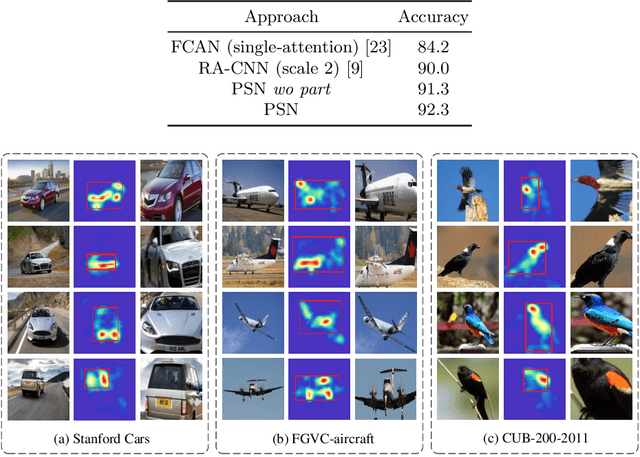
Fine-grained image recognition has been a hot research topic in computer vision due to its various applications. The-state-of-the-art is the part/region-based approaches that first localize discriminative parts/regions, and then learn their fine-grained features. However, these approaches have some inherent drawbacks: 1) the discriminative feature representation of an object is prone to be disturbed by complicated background; 2) it is unreasonable and inflexible to fix the number of salient parts, because the intended parts may be unavailable under certain circumstances due to occlusion or incompleteness, and 3) the spatial correlation among different salient parts has not been thoroughly exploited (if not completely neglected). To overcome these drawbacks, in this paper we propose a new, simple yet robust method by building part sequence model on the attended object region. Concretely, we first try to alleviate the background effect by using a region attention mechanism to generate the attended region from the original image. Then, instead of localizing different salient parts and extracting their features separately, we learn the part representation implicitly by applying a mapping function on the serialized features of the object. Finally, we combine the region attending network and the part sequence learning network into a unified framework that can be trained end-to-end with only image-level labels. Our extensive experiments on three fine-grained benchmarks show that the proposed method achieves the state of the art performance.
Efficient Video Scene Text Spotting: Unifying Detection, Tracking, and Recognition
Mar 08, 2019


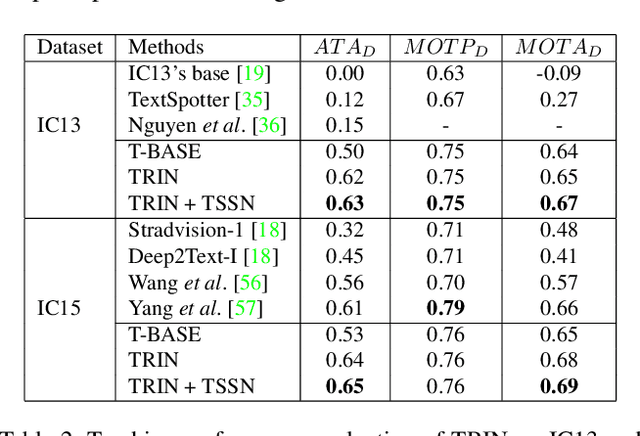
This paper proposes an unified framework for efficiently spotting scene text in videos. The method localizes and tracks text in each frame, and recognizes each tracked text stream one-time. Specifically, we first train a spatial-temporal text detector for localizing text regions in the sequential frames. Secondly, a well-designed text tracker is trained for grouping the localized text regions into corresponding cropped text streams. To efficiently spot video text, we recognize each tracked text stream one-time with a text region quality scoring mechanism instead of identifying the cropped text regions one-by-one. Experiments on two public benchmarks demonstrate that our method achieves impressive performance.
Segregated Temporal Assembly Recurrent Networks for Weakly Supervised Multiple Action Detection
Nov 19, 2018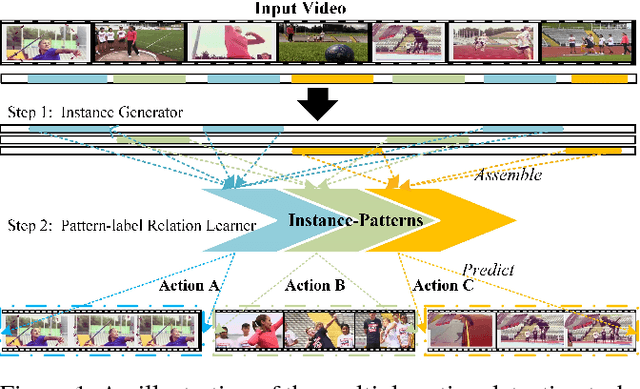

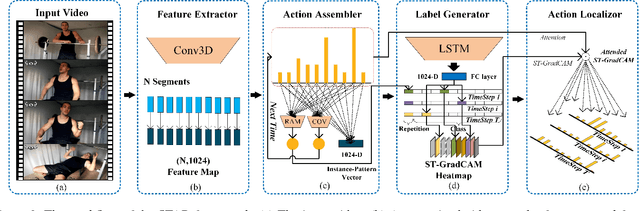
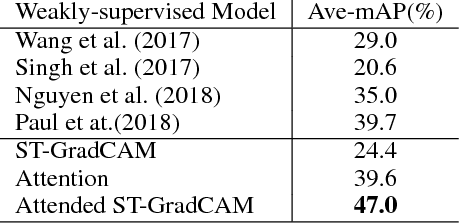
This paper proposes a segregated temporal assembly recurrent (STAR) network for weakly-supervised multiple action detection. The model learns from untrimmed videos with only supervision of video-level labels and makes prediction of intervals of multiple actions. Specifically, we first assemble video clips according to class labels by an attention mechanism that learns class-variable attention weights and thus helps the noise relieving from background or other actions. Secondly, we build temporal relationship between actions by feeding the assembled features into an enhanced recurrent neural network. Finally, we transform the output of recurrent neural network into the corresponding action distribution. In order to generate more precise temporal proposals, we design a score term called segregated temporal gradient-weighted class activation mapping (ST-GradCAM) fused with attention weights. Experiments on THUMOS'14 and ActivityNet1.3 datasets show that our approach outperforms the state-of-the-art weakly-supervised method, and performs at par with the fully-supervised counterparts.
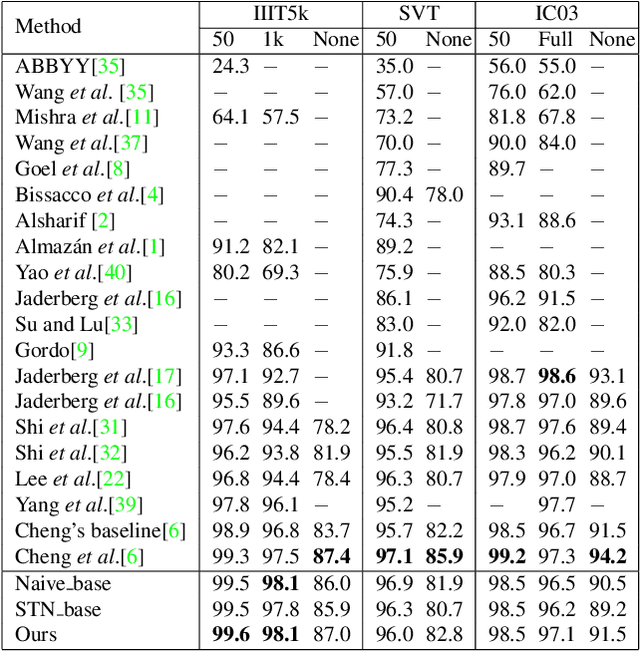
Edit Probability for Scene Text Recognition
May 09, 2018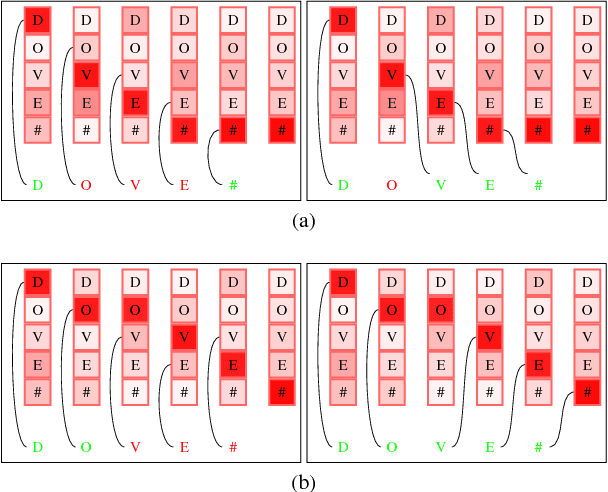
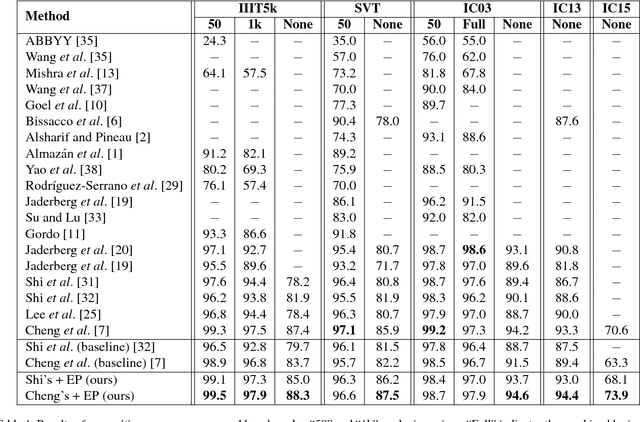
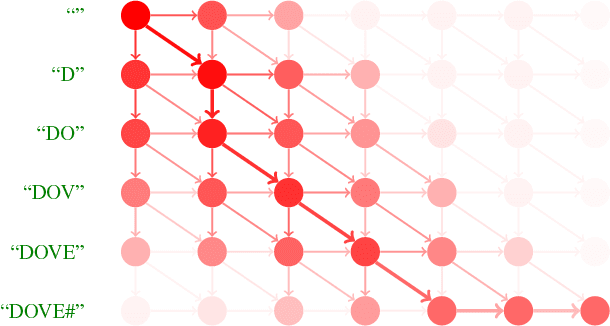
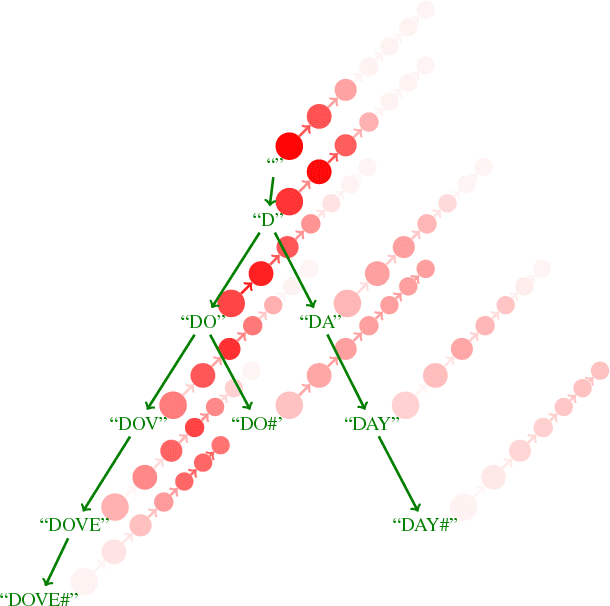
We consider the scene text recognition problem under the attention-based encoder-decoder framework, which is the state of the art. The existing methods usually employ a frame-wise maximal likelihood loss to optimize the models. When we train the model, the misalignment between the ground truth strings and the attention's output sequences of probability distribution, which is caused by missing or superfluous characters, will confuse and mislead the training process, and consequently make the training costly and degrade the recognition accuracy. To handle this problem, we propose a novel method called edit probability (EP) for scene text recognition. EP tries to effectively estimate the probability of generating a string from the output sequence of probability distribution conditioned on the input image, while considering the possible occurrences of missing/superfluous characters. The advantage lies in that the training process can focus on the missing, superfluous and unrecognized characters, and thus the impact of the misalignment problem can be alleviated or even overcome. We conduct extensive experiments on standard benchmarks, including the IIIT-5K, Street View Text and ICDAR datasets. Experimental results show that the EP can substantially boost scene text recognition performance.
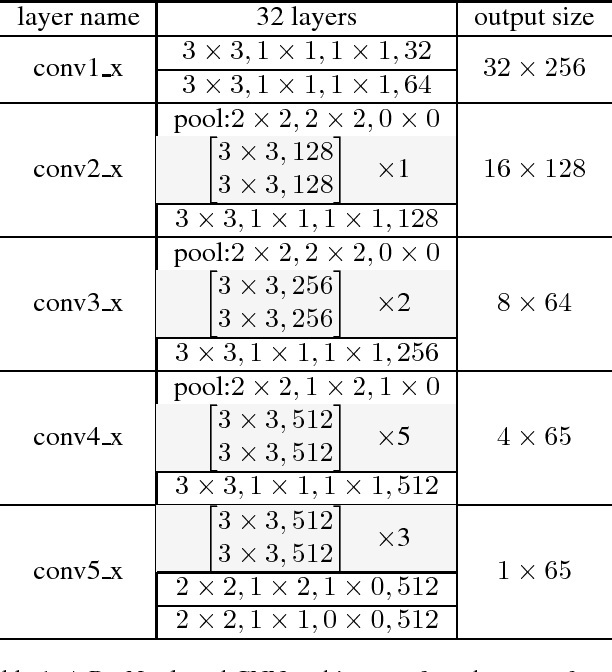
AON: Towards Arbitrarily-Oriented Text Recognition
Mar 22, 2018
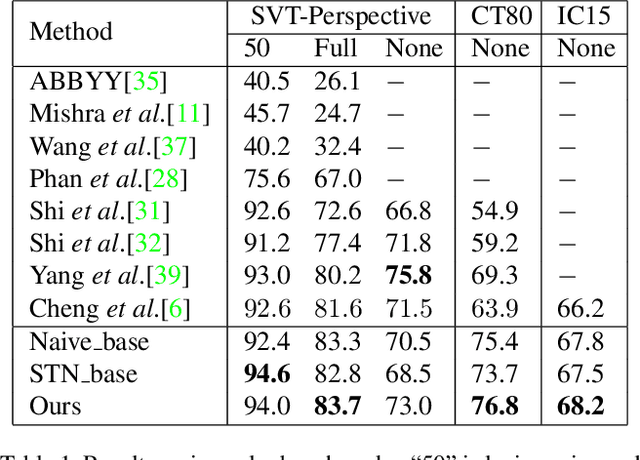
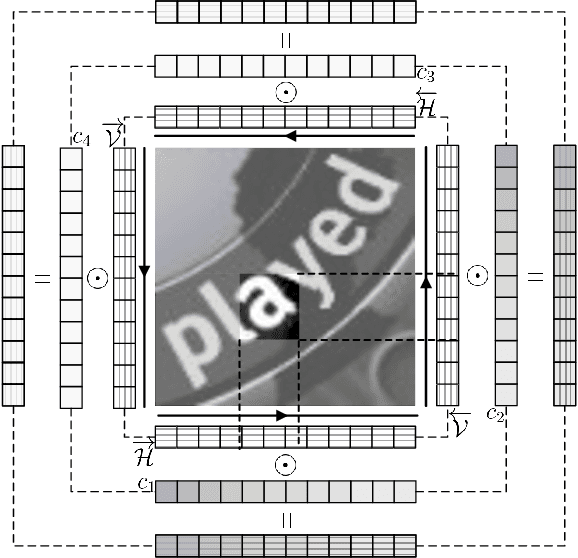
Recognizing text from natural images is a hot research topic in computer vision due to its various applications. Despite the enduring research of several decades on optical character recognition (OCR), recognizing texts from natural images is still a challenging task. This is because scene texts are often in irregular (e.g. curved, arbitrarily-oriented or seriously distorted) arrangements, which have not yet been well addressed in the literature. Existing methods on text recognition mainly work with regular (horizontal and frontal) texts and cannot be trivially generalized to handle irregular texts. In this paper, we develop the arbitrary orientation network (AON) to directly capture the deep features of irregular texts, which are combined into an attention-based decoder to generate character sequence. The whole network can be trained end-to-end by using only images and word-level annotations. Extensive experiments on various benchmarks, including the CUTE80, SVT-Perspective, IIIT5k, SVT and ICDAR datasets, show that the proposed AON-based method achieves the-state-of-the-art performance in irregular datasets, and is comparable to major existing methods in regular datasets.
Focusing Attention: Towards Accurate Text Recognition in Natural Images
Oct 17, 2017
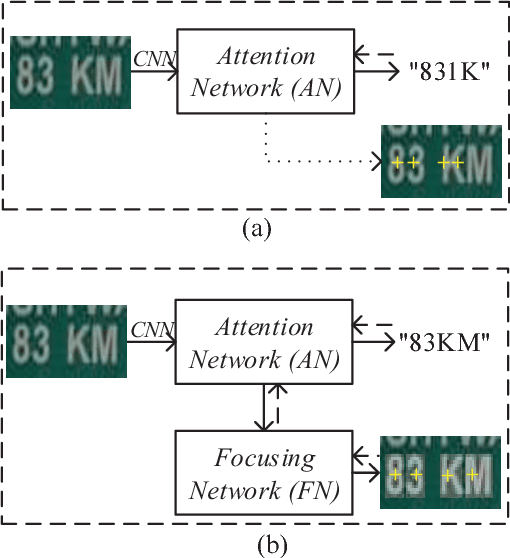
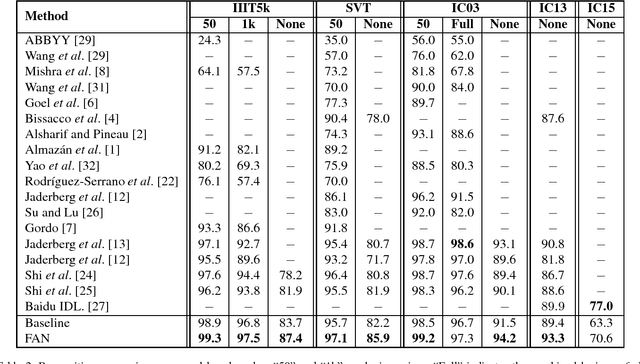
Scene text recognition has been a hot research topic in computer vision due to its various applications. The state of the art is the attention-based encoder-decoder framework that learns the mapping between input images and output sequences in a purely data-driven way. However, we observe that existing attention-based methods perform poorly on complicated and/or low-quality images. One major reason is that existing methods cannot get accurate alignments between feature areas and targets for such images. We call this phenomenon "attention drift". To tackle this problem, in this paper we propose the FAN (the abbreviation of Focusing Attention Network) method that employs a focusing attention mechanism to automatically draw back the drifted attention. FAN consists of two major components: an attention network (AN) that is responsible for recognizing character targets as in the existing methods, and a focusing network (FN) that is responsible for adjusting attention by evaluating whether AN pays attention properly on the target areas in the images. Furthermore, different from the existing methods, we adopt a ResNet-based network to enrich deep representations of scene text images. Extensive experiments on various benchmarks, including the IIIT5k, SVT and ICDAR datasets, show that the FAN method substantially outperforms the existing methods.