 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Reward Was in Your Data All Along: Correcting Flow Matching with Discriminator-Guided RL
Jun 17, 2026Score- and flow-matching models often rely on preference-based reinforcement learning for two purposes: aligning with subjective preferences and, surprisingly, recovering properties such as visual realism and coherent object structure that matching-based training is intended to learn from the data itself. We argue that this reflects a structural mismatch. Matching losses measure $\ell_2$ regression error on the velocity or score field under training-time marginals, a proxy poorly aligned with the visual and semantic properties that determine sample quality at inference. Given a reward aligned with these properties, RL sidesteps the mismatch by evaluating the model on its own samples and following the reward landscape directly. The challenge is to obtain such a reward without relying on human preferences, which are expensive and conflate data realism with annotator inclinations. We propose Discriminator-Guided RL (DRL). DRL trains a discriminator to separate data from base-model samples in a pretrained representation space and uses its logit as the reward in KL-regularized RL. The pretrained space restricts the discriminator to perceptually meaningful directions, and the logit estimates the log-likelihood ratio between data and model, which is the optimal reward for targeting the data distribution. Across SiT, JiT, REPA, and RAE, DRL reduces guidance-free FID (e.g., $9.38 \to 2.62$ on SiT) and semantic-space FD (e.g., $88.2 \to 19.3$ on DINOv3 for SiT), with consistent gains across all backbones, and improves human-preference rewards without training on them. It also yields a better Pareto frontier between preference reward and image fidelity under subsequent preference-based post-training, increasing alignment while reducing low-level artifacts such as oversaturation and excessive brightness.
Real-Time Video Super-Resolution on Smartphones with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

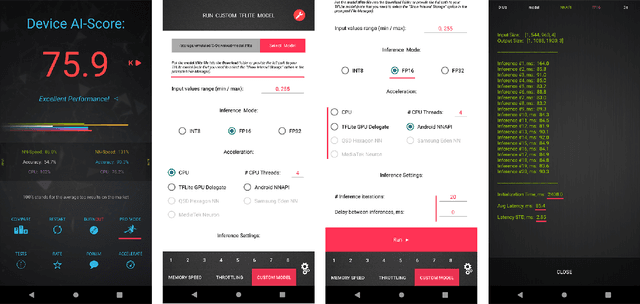
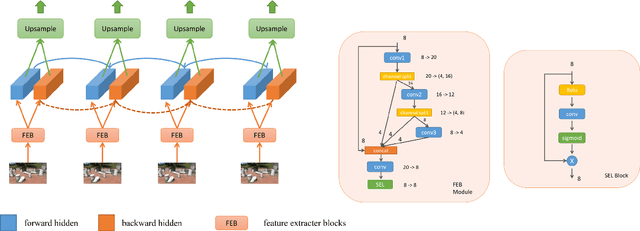
Video super-resolution has recently become one of the most important mobile-related problems due to the rise of video communication and streaming services. While many solutions have been proposed for this task, the majority of them are too computationally expensive to run on portable devices with limited hardware resources. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based video super-resolution solutions that can achieve a real-time performance on mobile GPUs. The participants were provided with the REDS dataset and trained their models to do an efficient 4X video upscaling. The runtime of all models was evaluated on the OPPO Find X2 smartphone with the Snapdragon 865 SoC capable of accelerating floating-point networks on its Adreno GPU. The proposed solutions are fully compatible with any mobile GPU and can upscale videos to HD resolution at up to 80 FPS while demonstrating high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.