 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTedNet: A Pytorch Toolkit for Tensor Decomposition Networks
Apr 11, 2021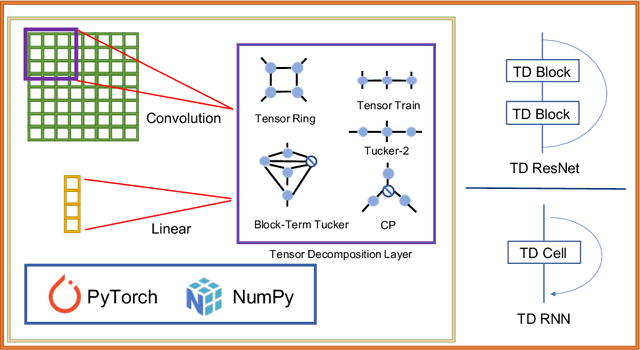

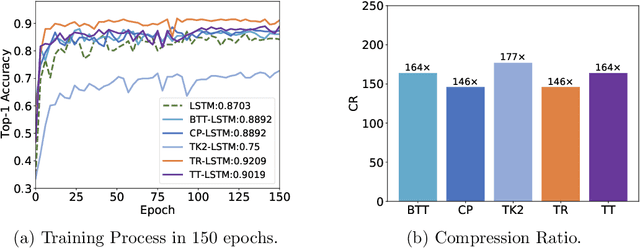
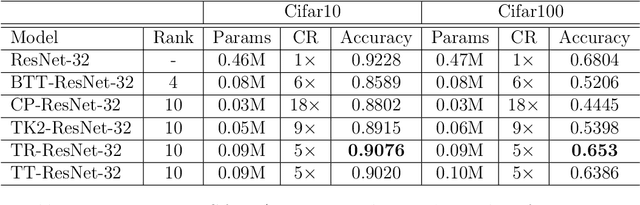
Tensor Decomposition Networks(TDNs) prevail for their inherent compact architectures. For providing convenience, we present a toolkit named TedNet that is based on the Pytorch framework, to give more researchers a flexible way to exploit TDNs. TedNet implements 5 kinds of tensor decomposition(i.e., CANDECOMP/PARAFAC(CP), Block-Term Tucker(BT), Tucker-2, Tensor Train(TT) and Tensor Ring(TR)) on traditional deep neural layers, the convolutional layer and the fully-connected layer. By utilizing these basic layers, it is simple to construct a variety of TDNs like TR-ResNet, TT-LSTM, etc. TedNet is available at https://github.com/tnbar/tednet.
Pseudo-supervised Deep Subspace Clustering
Apr 08, 2021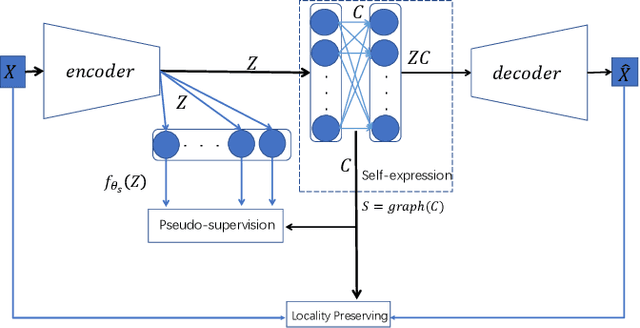
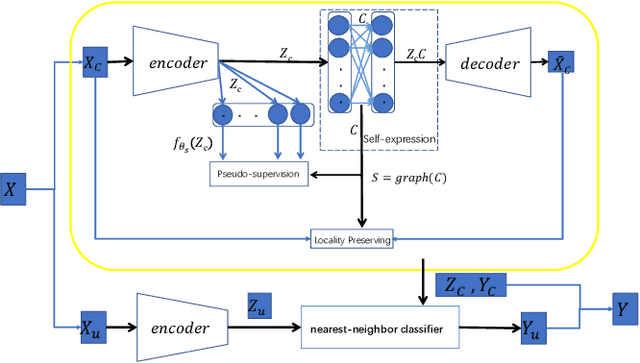
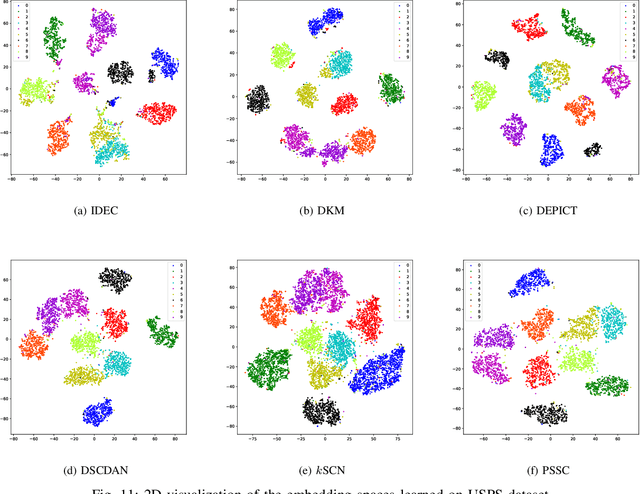
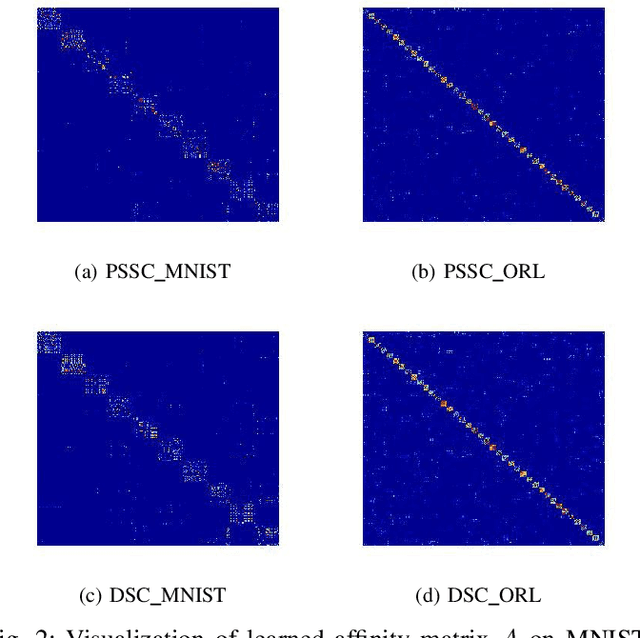
Auto-Encoder (AE)-based deep subspace clustering (DSC) methods have achieved impressive performance due to the powerful representation extracted using deep neural networks while prioritizing categorical separability. However, self-reconstruction loss of an AE ignores rich useful relation information and might lead to indiscriminative representation, which inevitably degrades the clustering performance. It is also challenging to learn high-level similarity without feeding semantic labels. Another unsolved problem facing DSC is the huge memory cost due to $n\times n$ similarity matrix, which is incurred by the self-expression layer between an encoder and decoder. To tackle these problems, we use pairwise similarity to weigh the reconstruction loss to capture local structure information, while a similarity is learned by the self-expression layer. Pseudo-graphs and pseudo-labels, which allow benefiting from uncertain knowledge acquired during network training, are further employed to supervise similarity learning. Joint learning and iterative training facilitate to obtain an overall optimal solution. Extensive experiments on benchmark datasets demonstrate the superiority of our approach. By combining with the $k$-nearest neighbors algorithm, we further show that our method can address the large-scale and out-of-sample problems.
Partial Differential Equations is All You Need for Generating Neural Architectures -- A Theory for Physical Artificial Intelligence Systems
Mar 10, 2021
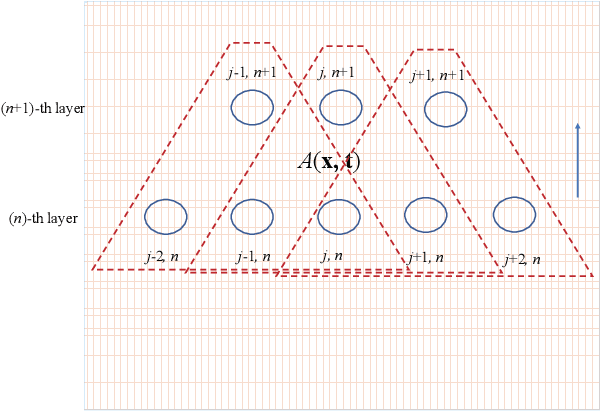
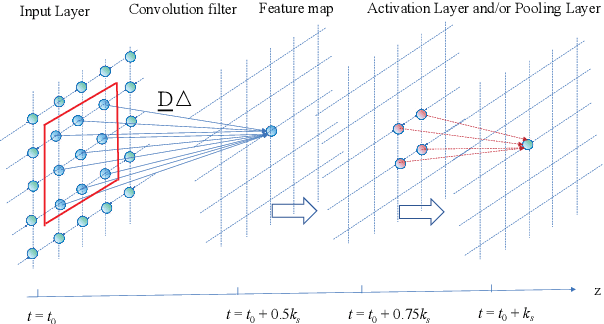
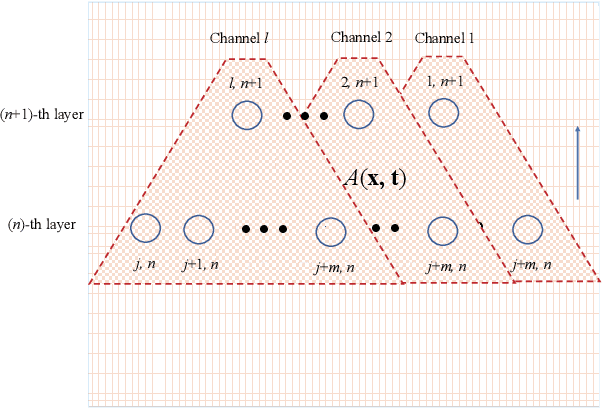
In this work, we generalize the reaction-diffusion equation in statistical physics, Schr\"odinger equation in quantum mechanics, Helmholtz equation in paraxial optics into the neural partial differential equations (NPDE), which can be considered as the fundamental equations in the field of artificial intelligence research. We take finite difference method to discretize NPDE for finding numerical solution, and the basic building blocks of deep neural network architecture, including multi-layer perceptron, convolutional neural network and recurrent neural networks, are generated. The learning strategies, such as Adaptive moment estimation, L-BFGS, pseudoinverse learning algorithms and partial differential equation constrained optimization, are also presented. We believe it is of significance that presented clear physical image of interpretable deep neural networks, which makes it be possible for applying to analog computing device design, and pave the road to physical artificial intelligence.
Contrastive Disentanglement in Generative Adversarial Networks
Mar 05, 2021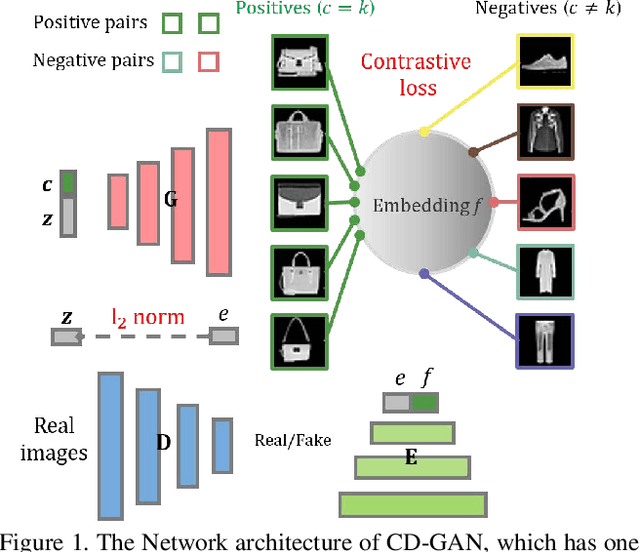
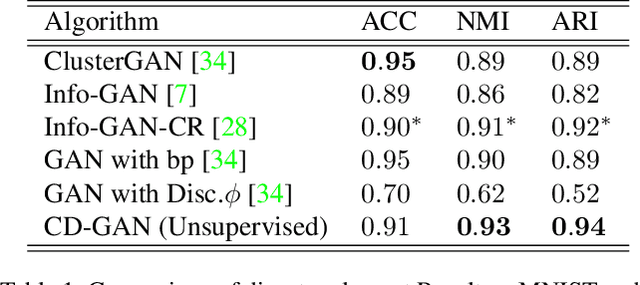

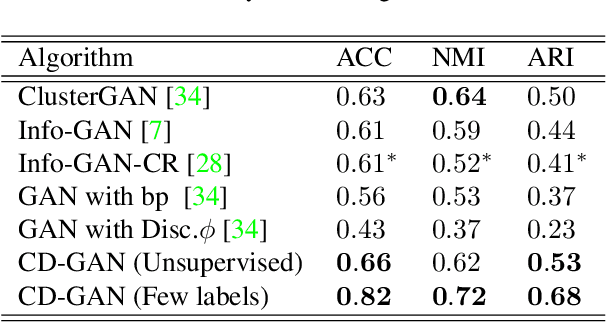
Disentanglement is defined as the problem of learninga representation that can separate the distinct, informativefactors of variations of data. Learning such a representa-tion may be critical for developing explainable and human-controllable Deep Generative Models (DGMs) in artificialintelligence. However, disentanglement in GANs is not a triv-ial task, as the absence of sample likelihood and posteriorinference for latent variables seems to prohibit the forwardstep. Inspired by contrastive learning (CL), this paper, froma new perspective, proposes contrastive disentanglement ingenerative adversarial networks (CD-GAN). It aims at dis-entangling the factors of inter-class variation of visual datathrough contrasting image features, since the same factorvalues produce images in the same class. More importantly,we probe a novel way to make use of limited amount ofsupervision to the largest extent, to promote inter-class dis-entanglement performance. Extensive experimental resultson many well-known datasets demonstrate the efficacy ofCD-GAN for disentangling inter-class variation.
A Survey on Deep Semi-supervised Learning
Feb 28, 2021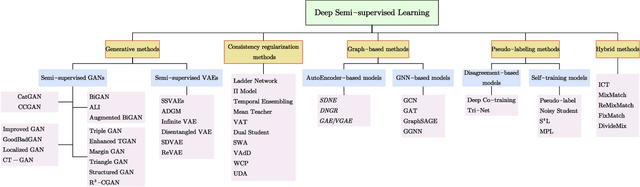

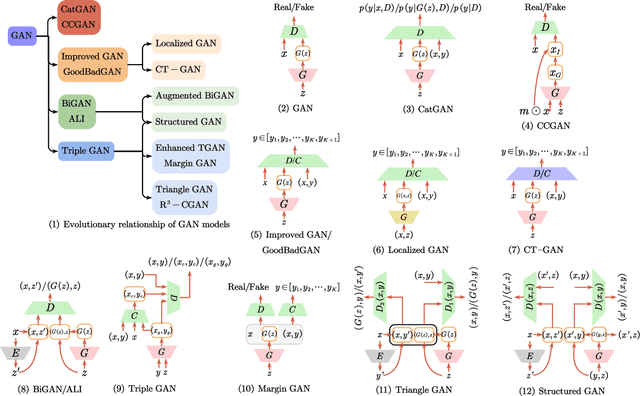
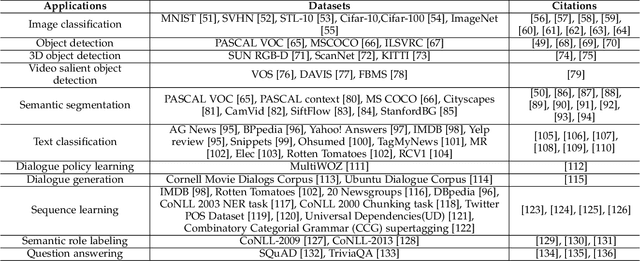
Deep semi-supervised learning is a fast-growing field with a range of practical applications. This paper provides a comprehensive survey on both fundamentals and recent advances in deep semi-supervised learning methods from model design perspectives and unsupervised loss functions. We first present a taxonomy for deep semi-supervised learning that categorizes existing methods, including deep generative methods, consistency regularization methods, graph-based methods, pseudo-labeling methods, and hybrid methods. Then we offer a detailed comparison of these methods in terms of the type of losses, contributions, and architecture differences. In addition to the past few years' progress, we further discuss some shortcomings of existing methods and provide some tentative heuristic solutions for solving these open problems.
Graph-based Semi-supervised Learning: A Comprehensive Review
Feb 26, 2021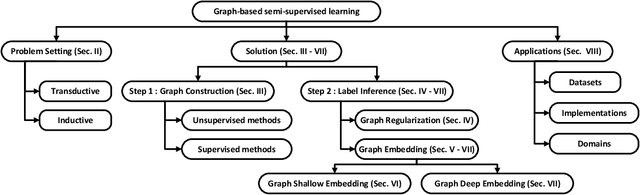
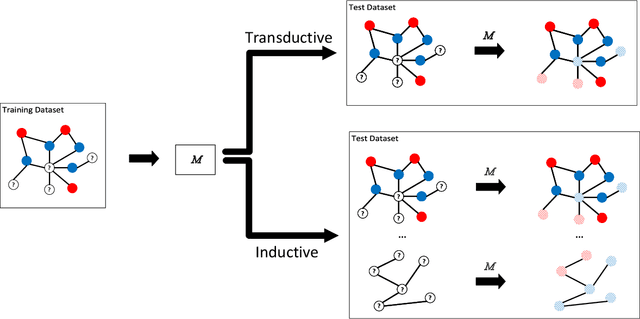
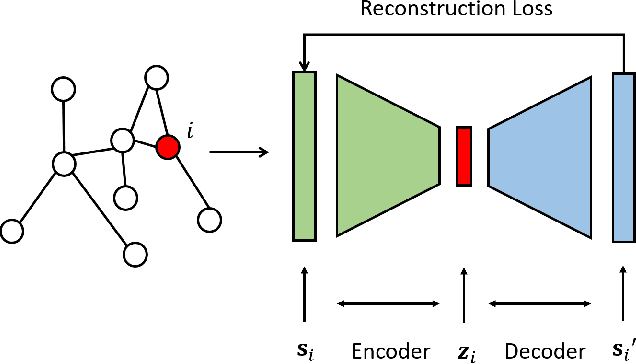
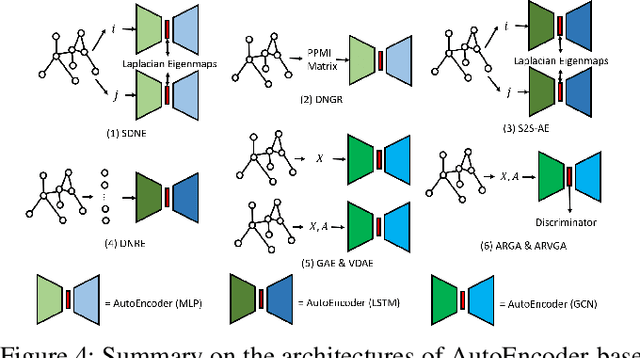
Semi-supervised learning (SSL) has tremendous value in practice due to its ability to utilize both labeled data and unlabelled data. An important class of SSL methods is to naturally represent data as graphs such that the label information of unlabelled samples can be inferred from the graphs, which corresponds to graph-based semi-supervised learning (GSSL) methods. GSSL methods have demonstrated their advantages in various domains due to their uniqueness of structure, the universality of applications, and their scalability to large scale data. Focusing on this class of methods, this work aims to provide both researchers and practitioners with a solid and systematic understanding of relevant advances as well as the underlying connections among them. This makes our paper distinct from recent surveys that cover an overall picture of SSL methods while neglecting fundamental understanding of GSSL methods. In particular, a major contribution of this paper lies in a new generalized taxonomy for GSSL, including graph regularization and graph embedding methods, with the most up-to-date references and useful resources such as codes, datasets, and applications. Furthermore, we present several potential research directions as future work with insights into this rapidly growing field.
MultiFace: A Generic Training Mechanism for Boosting Face Recognition Performance
Jan 31, 2021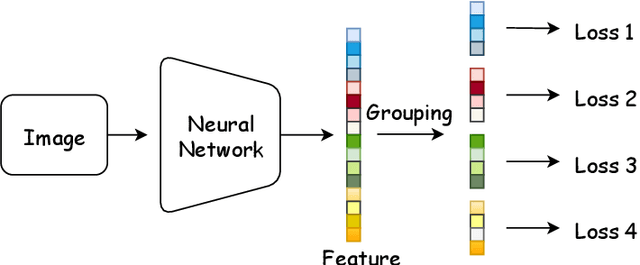
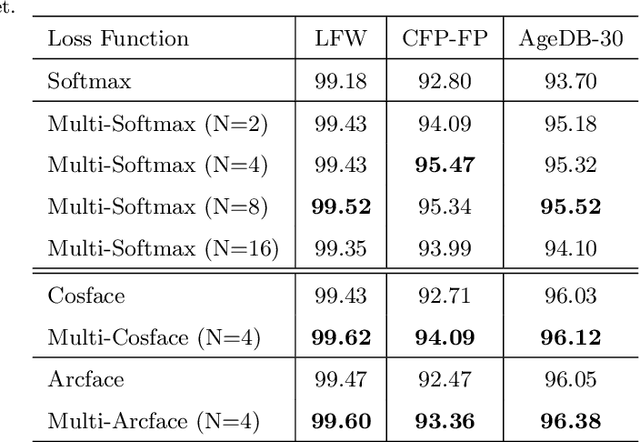
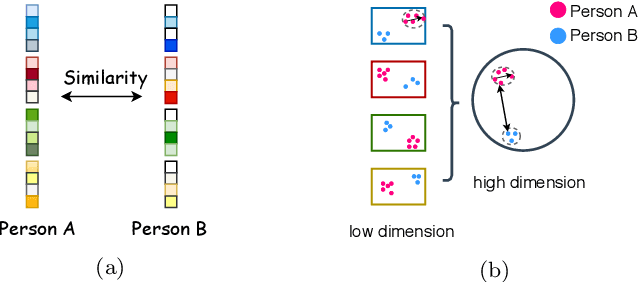
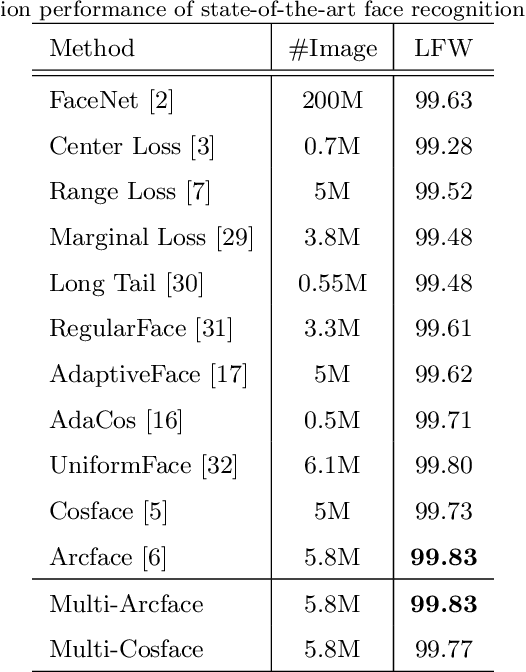
Deep Convolutional Neural Networks (DCNNs) and their variants have been widely used in large scale face recognition(FR) recently. Existing methods have achieved good performance on many FR benchmarks. However, most of them suffer from two major problems. First, these methods converge quite slowly since they optimize the loss functions in a high-dimensional and sparse Gaussian Sphere. Second, the high dimensionality of features, despite the powerful descriptive ability, brings difficulty to the optimization, which may lead to a sub-optimal local optimum. To address these problems, we propose a simple yet efficient training mechanism called MultiFace, where we approximate the original high-dimensional features by the ensemble of low-dimensional features. The proposed mechanism is also generic and can be easily applied to many advanced FR models. Moreover, it brings the benefits of good interpretability to FR models via the clustering effect. In detail, the ensemble of these low-dimensional features can capture complementary yet discriminative information, which can increase the intra-class compactness and inter-class separability. Experimental results show that the proposed mechanism can accelerate 2-3 times with the softmax loss and 1.2-1.5 times with Arcface or Cosface, while achieving state-of-the-art performances in several benchmark datasets. Especially, the significant improvements on large-scale datasets(e.g., IJB and MageFace) demonstrate the flexibility of our new training mechanism.
RegNet: Self-Regulated Network for Image Classification
Jan 03, 2021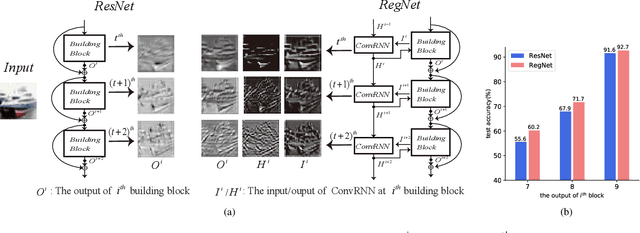
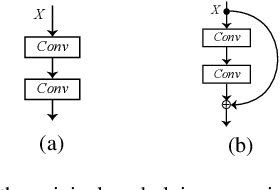
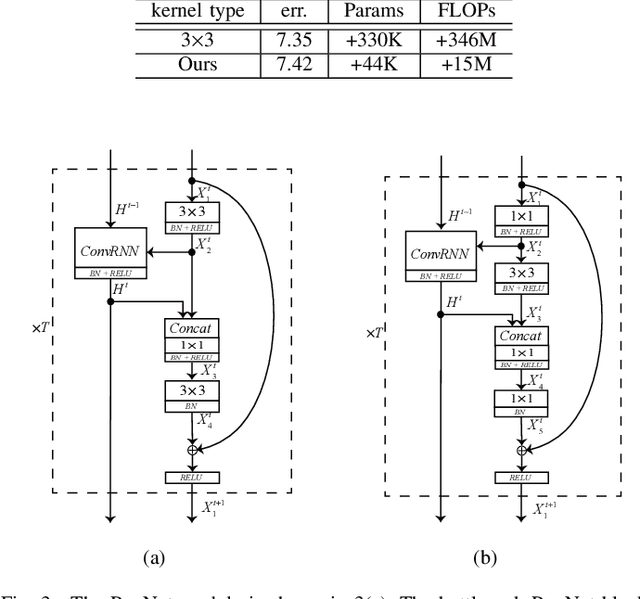
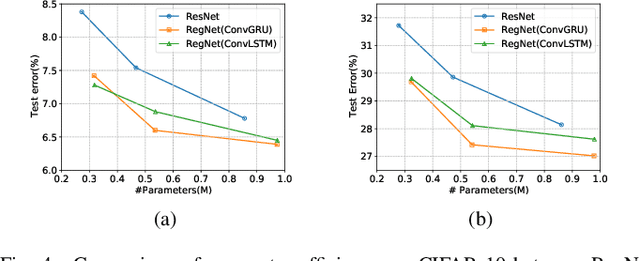
The ResNet and its variants have achieved remarkable successes in various computer vision tasks. Despite its success in making gradient flow through building blocks, the simple shortcut connection mechanism limits the ability of re-exploring new potentially complementary features due to the additive function. To address this issue, in this paper, we propose to introduce a regulator module as a memory mechanism to extract complementary features, which are further fed to the ResNet. In particular, the regulator module is composed of convolutional RNNs (e.g., Convolutional LSTMs or Convolutional GRUs), which are shown to be good at extracting Spatio-temporal information. We named the new regulated networks as RegNet. The regulator module can be easily implemented and appended to any ResNet architecture. We also apply the regulator module for improving the Squeeze-and-Excitation ResNet to show the generalization ability of our method. Experimental results on three image classification datasets have demonstrated the promising performance of the proposed architecture compared with the standard ResNet, SE-ResNet, and other state-of-the-art architectures.
A Subword Guided Neural Word Segmentation Model for Sindhi
Dec 30, 2020
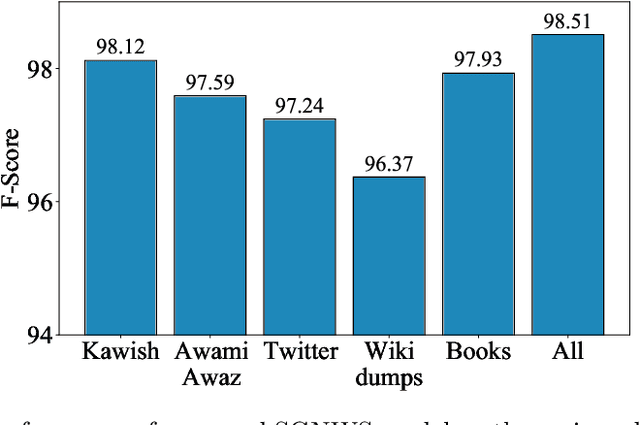

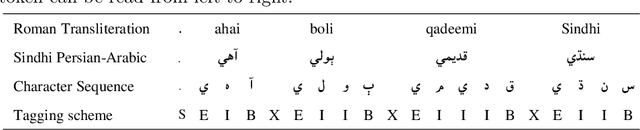
Deep neural networks employ multiple processing layers for learning text representations to alleviate the burden of manual feature engineering in Natural Language Processing (NLP). Such text representations are widely used to extract features from unlabeled data. The word segmentation is a fundamental and inevitable prerequisite for many languages. Sindhi is an under-resourced language, whose segmentation is challenging as it exhibits space omission, space insertion issues, and lacks the labeled corpus for segmentation. In this paper, we investigate supervised Sindhi Word Segmentation (SWS) using unlabeled data with a Subword Guided Neural Word Segmenter (SGNWS) for Sindhi. In order to learn text representations, we incorporate subword representations to recurrent neural architecture to capture word information at morphemic-level, which takes advantage of Bidirectional Long-Short Term Memory (BiLSTM), self-attention mechanism, and Conditional Random Field (CRF). Our proposed SGNWS model achieves an F1 value of 98.51% without relying on feature engineering. The empirical results demonstrate the benefits of the proposed model over the existing Sindhi word segmenters.
Block-term Tensor Neural Networks
Oct 10, 2020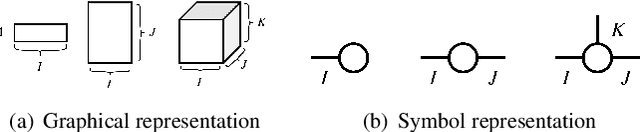

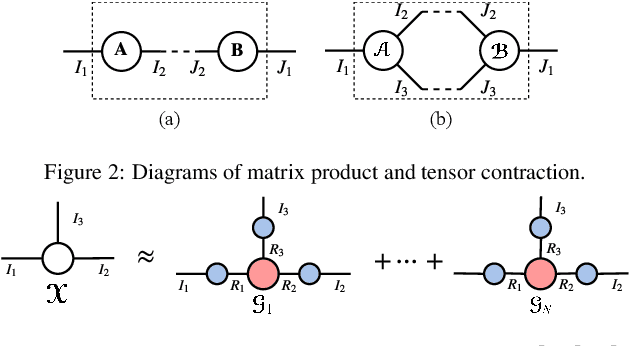
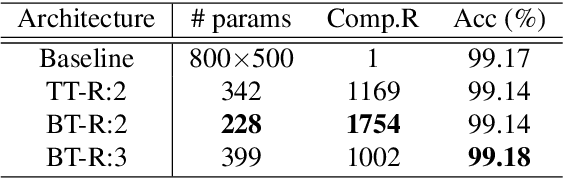
Deep neural networks (DNNs) have achieved outstanding performance in a wide range of applications, e.g., image classification, natural language processing, etc. Despite the good performance, the huge number of parameters in DNNs brings challenges to efficient training of DNNs and also their deployment in low-end devices with limited computing resources. In this paper, we explore the correlations in the weight matrices, and approximate the weight matrices with the low-rank block-term tensors. We name the new corresponding structure as block-term tensor layers (BT-layers), which can be easily adapted to neural network models, such as CNNs and RNNs. In particular, the inputs and the outputs in BT-layers are reshaped into low-dimensional high-order tensors with a similar or improved representation power. Sufficient experiments have demonstrated that BT-layers in CNNs and RNNs can achieve a very large compression ratio on the number of parameters while preserving or improving the representation power of the original DNNs.
* 12 pages, 15 figures