 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation of Sindhi Word Embedding in Semantic Analogies and Downstream Tasks
Aug 28, 2024



In this paper, we propose a new word embedding based corpus consisting of more than 61 million words crawled from multiple web resources. We design a preprocessing pipeline for the filtration of unwanted text from crawled data. Afterwards, the cleaned vocabulary is fed to state-of-the-art continuous-bag-of-words, skip-gram, and GloVe word embedding algorithms. For the evaluation of pretrained embeddings, we use popular intrinsic and extrinsic evaluation approaches. The evaluation results reveal that continuous-bag-of-words and skip-gram perform better than GloVe and existing Sindhi fastText word embedding on both intrinsic and extrinsic evaluation approaches
Building a Safer Maritime Environment Through Multi-Path Long-Term Vessel Trajectory Forecasting
Oct 29, 2023



Maritime transport is paramount to global economic growth and environmental sustainability. In this regard, the Automatic Identification System (AIS) data plays a significant role by offering real-time streaming data on vessel movement, which allows for enhanced traffic surveillance, assisting in vessel safety by avoiding vessel-to-vessel collisions and proactively preventing vessel-to-whale ones. This paper tackles an intrinsic problem to trajectory forecasting: the effective multi-path long-term vessel trajectory forecasting on engineered sequences of AIS data. We utilize an encoder-decoder model with Bidirectional Long Short-Term Memory Networks (Bi-LSTM) to predict the next 12 hours of vessel trajectories using 1 to 3 hours of AIS data. We feed the model with probabilistic features engineered from the AIS data that refer to the potential route and destination of each trajectory so that the model, leveraging convolutional layers for spatial feature learning and a position-aware attention mechanism that increases the importance of recent timesteps of a sequence during temporal feature learning, forecasts the vessel trajectory taking the potential route and destination into account. The F1 Score of these features is approximately 85% and 75%, indicating their efficiency in supplementing the neural network. We trialed our model in the Gulf of St. Lawrence, one of the North Atlantic Right Whales (NARW) habitats, achieving an R2 score exceeding 98% with varying techniques and features. Despite the high R2 score being attributed to well-defined shipping lanes, our model demonstrates superior complex decision-making during path selection. In addition, our model shows enhanced accuracy, with average and median forecasting errors of 11km and 6km, respectively. Our study confirms the potential of geographical data engineering and trajectory forecasting models for preserving marine life species.
Privacy-Preserved Blockchain-Federated-Learning for Medical Image Analysis Towards Multiple Parties
Apr 22, 2021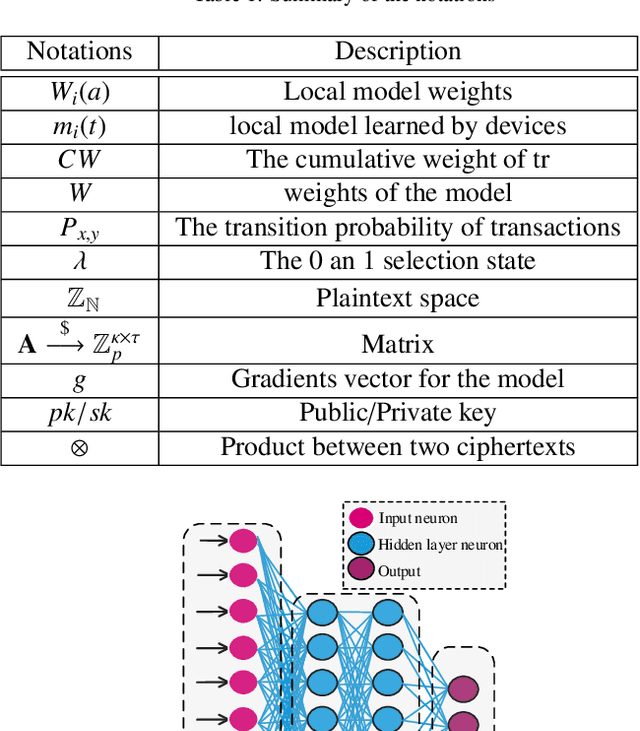
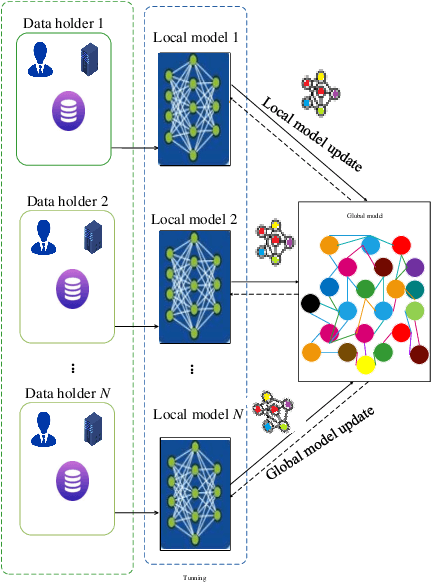
To share the patient\textquoteright s data in the blockchain network can help to learn the accurate deep learning model for the better prediction of COVID-19 patients. However, privacy (e.g., data leakage) and security (e.g., reliability or trust of data) concerns are the main challenging task for the health care centers. To solve this challenging task, this article designs a privacy-preserving framework based on federated learning and blockchain. In the first step, we train the local model by using the capsule network for the segmentation and classification of the COVID-19 images. The segmentation aims to extract nodules and classification to train the model. In the second step, we secure the local model through the homomorphic encryption scheme. The designed scheme encrypts and decrypts the gradients for federated learning. Moreover, for the decentralization of the model, we design a blockchain-based federated learning algorithm that can aggregate the gradients and update the local model. In this way, the proposed encryption scheme achieves the data provider privacy, and blockchain guarantees the reliability of the shared data. The experiment results demonstrate the performance of the proposed scheme.
A Survey on Semi-parametric Machine Learning Technique for Time Series Forecasting
Apr 02, 2021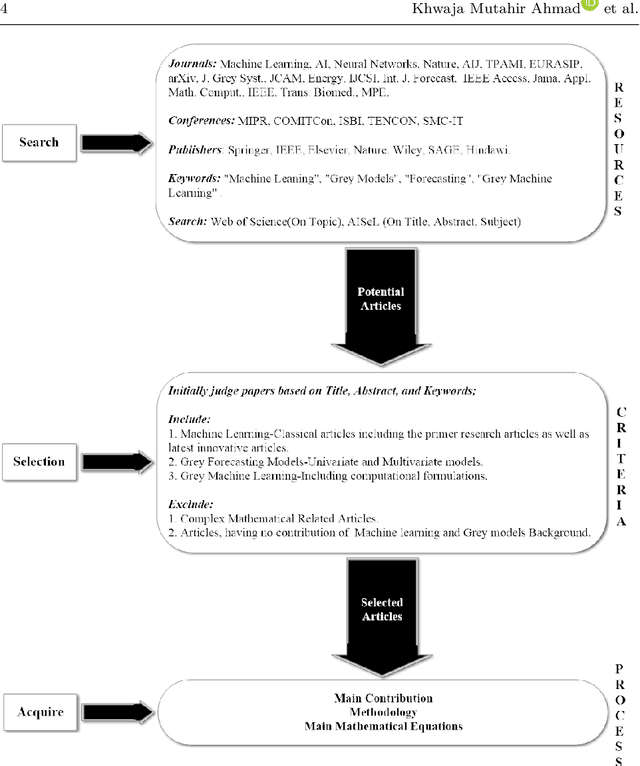

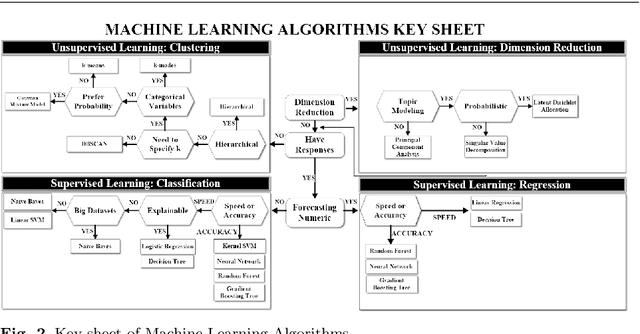

Artificial Intelligence (AI) has recently shown its capabilities for almost every field of life. Machine Learning, which is a subset of AI, is a `HOT' topic for researchers. Machine Learning outperforms other classical forecasting techniques in almost all-natural applications. It is a crucial part of modern research. As per this statement, Modern Machine Learning algorithms are hungry for big data. Due to the small datasets, the researchers may not prefer to use Machine Learning algorithms. To tackle this issue, the main purpose of this survey is to illustrate, demonstrate related studies for significance of a semi-parametric Machine Learning framework called Grey Machine Learning (GML). This kind of framework is capable of handling large datasets as well as small datasets for time series forecasting likely outcomes. This survey presents a comprehensive overview of the existing semi-parametric machine learning techniques for time series forecasting. In this paper, a primer survey on the GML framework is provided for researchers. To allow an in-depth understanding for the readers, a brief description of Machine Learning, as well as various forms of conventional grey forecasting models are discussed. Moreover, a brief description on the importance of GML framework is presented.
IoTMalware: Android IoT Malware Detection based on Deep Neural Network and Blockchain Technology
Feb 26, 2021
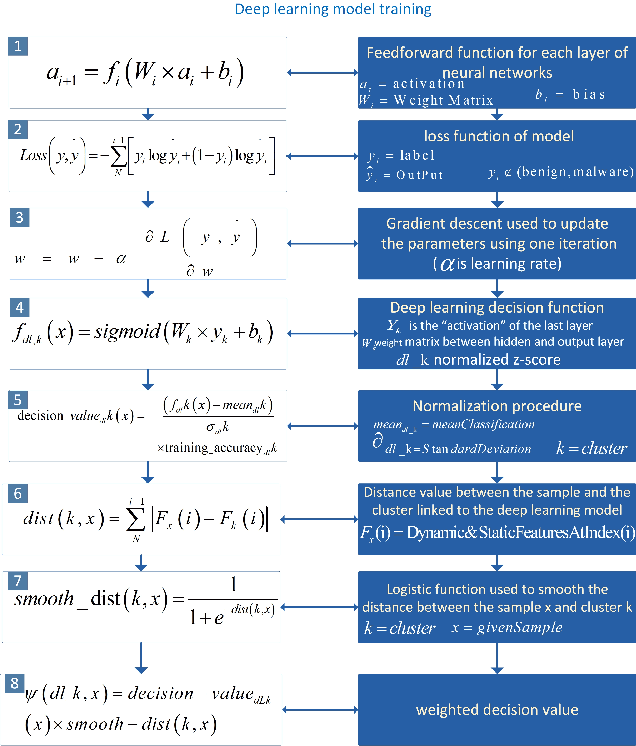
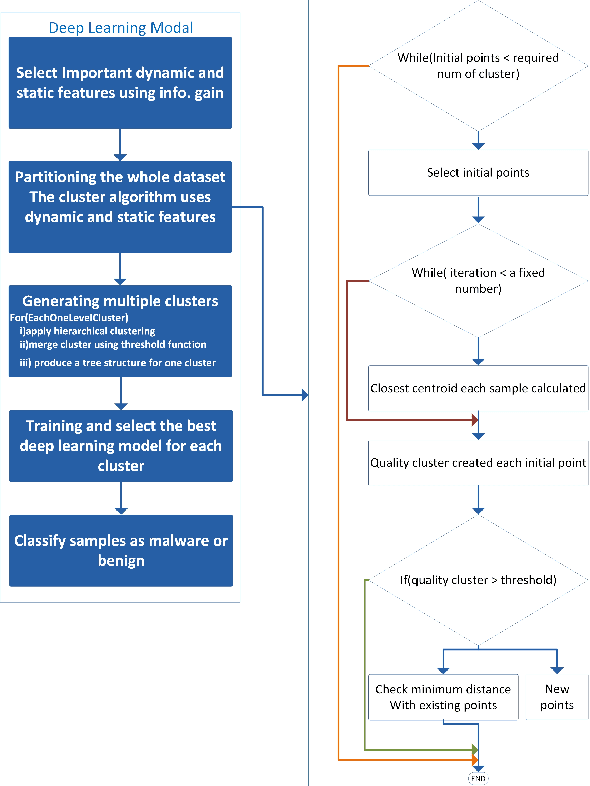
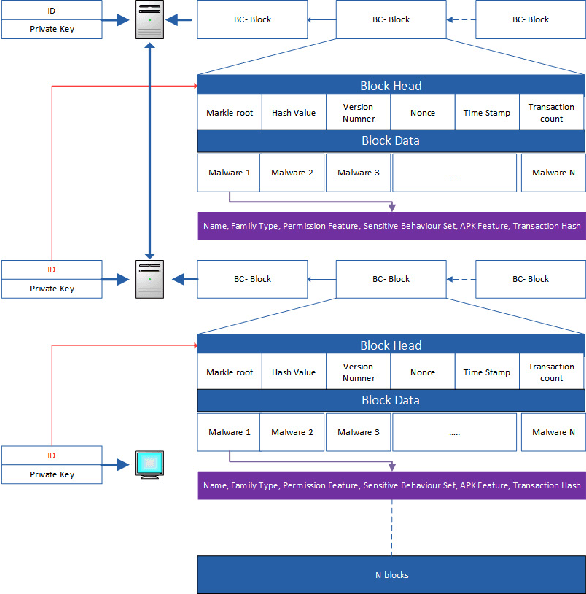
The Internet of Things (IoT) has been revolutionizing this world by introducing exciting applications almost in all walks of daily life, such as healthcare, smart cities, smart environments, safety, remote sensing, and many more. This paper proposes a new framework based on the blockchain and deep learning model to provide more security for Android IoT devices. Moreover, our framework is capable to find the malware activities in a real-time environment. The proposed deep learning model analyzes various static and dynamic features extracted from thousands of feature of malware and benign apps that are already stored in blockchain distributed ledger. The multi-layer deep learning model makes decisions by analyzing the previous data and follow some steps. Firstly, it divides the malware feature into multiple level clusters. Secondly, it chooses a unique deep learning model for each malware feature set or cluster. Finally, it produces the decision by combining the results generated from all cluster levels. Furthermore, the decisions and multiple-level clustering data are stored in a blockchain that can be further used to train every specialized cluster for unique data distribution. Also, a customized smart contract is designed to detect deceptive applications through the blockchain framework. The smart contract verifies the malicious application both during the uploading and downloading process of Android apps on the network. Consequently, the proposed framework provides flexibility to features for run-time security regarding malware detection on heterogeneous IoT devices. Finally, the smart contract helps to approve or deny to uploading and downloading harmful Android applications.
Trends in Vehicle Re-identification Past, Present, and Future: A Comprehensive Review
Feb 19, 2021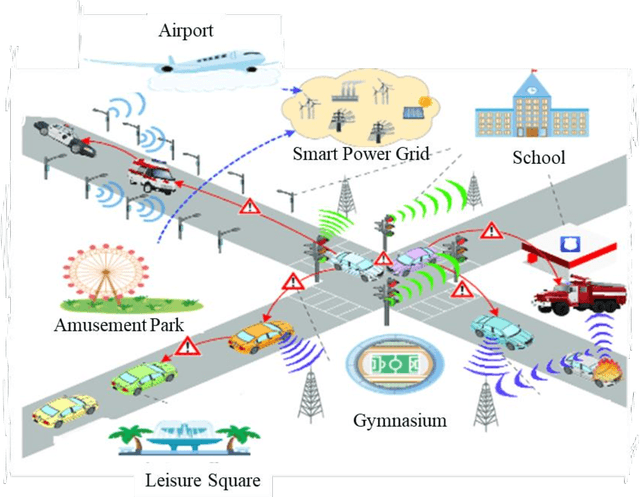
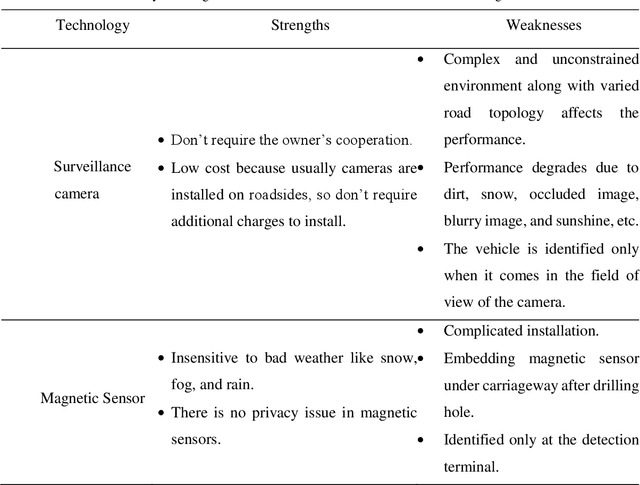

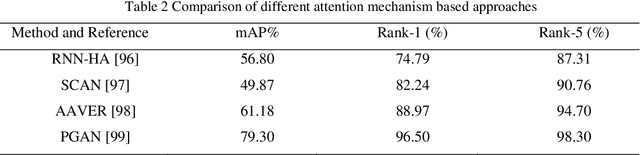
Vehicle Re-identification (re-id) over surveillance camera network with non-overlapping field of view is an exciting and challenging task in intelligent transportation systems (ITS). Due to its versatile applicability in metropolitan cities, it gained significant attention. Vehicle re-id matches targeted vehicle over non-overlapping views in multiple camera network. However, it becomes more difficult due to inter-class similarity, intra-class variability, viewpoint changes, and spatio-temporal uncertainty. In order to draw a detailed picture of vehicle re-id research, this paper gives a comprehensive description of the various vehicle re-id technologies, applicability, datasets, and a brief comparison of different methodologies. Our paper specifically focuses on vision-based vehicle re-id approaches, including vehicle appearance, license plate, and spatio-temporal characteristics. In addition, we explore the main challenges as well as a variety of applications in different domains. Lastly, a detailed comparison of current state-of-the-art methods performances over VeRi-776 and VehicleID datasets is summarized with future directions. We aim to facilitate future research by reviewing the work being done on vehicle re-id till to date.
A Subword Guided Neural Word Segmentation Model for Sindhi
Dec 30, 2020
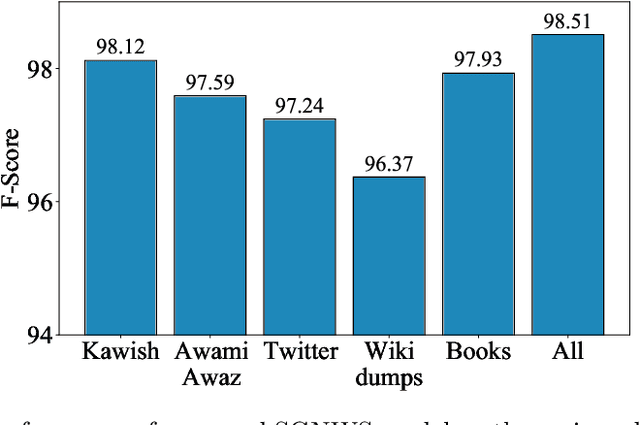

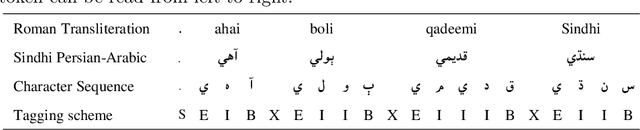
Deep neural networks employ multiple processing layers for learning text representations to alleviate the burden of manual feature engineering in Natural Language Processing (NLP). Such text representations are widely used to extract features from unlabeled data. The word segmentation is a fundamental and inevitable prerequisite for many languages. Sindhi is an under-resourced language, whose segmentation is challenging as it exhibits space omission, space insertion issues, and lacks the labeled corpus for segmentation. In this paper, we investigate supervised Sindhi Word Segmentation (SWS) using unlabeled data with a Subword Guided Neural Word Segmenter (SGNWS) for Sindhi. In order to learn text representations, we incorporate subword representations to recurrent neural architecture to capture word information at morphemic-level, which takes advantage of Bidirectional Long-Short Term Memory (BiLSTM), self-attention mechanism, and Conditional Random Field (CRF). Our proposed SGNWS model achieves an F1 value of 98.51% without relying on feature engineering. The empirical results demonstrate the benefits of the proposed model over the existing Sindhi word segmenters.
Blockchain-Federated-Learning and Deep Learning Models for COVID-19 detection using CT Imaging
Jul 10, 2020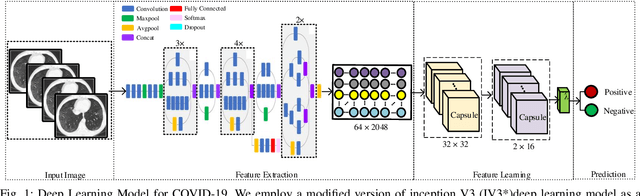
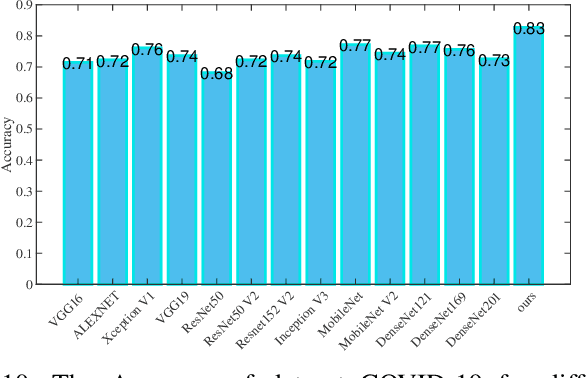
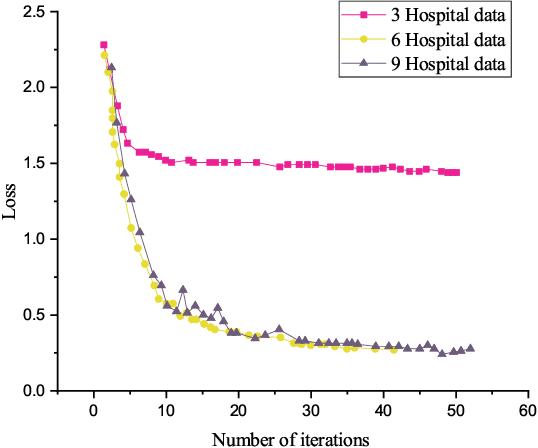

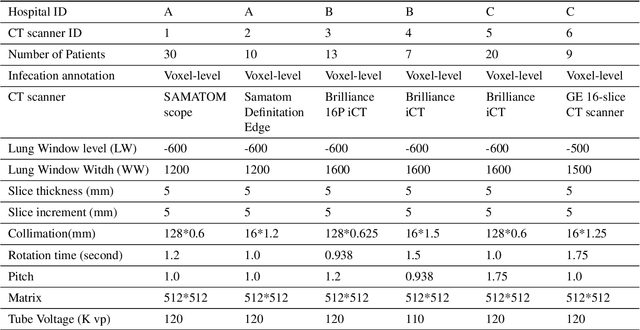
With the increase of COVID-19 cases worldwide, an effective way is required to diagnose COVID-19 patients. The primary problem in diagnosing COVID-19 patients is the shortage of testing kits, due to the quick spread of the virus, medical practitioners are facing difficulty identifying the positive cases. The second real-world problem is to share the data among the hospitals globally while keeping in view the privacy concern of the organizations. To address the problem of building a collaborative network model without leakage privacy of data are major concerns for training the deep learning model, this paper proposes a framework that collects a huge amount of data from different sources (various hospitals) and to train the deep learning model over a decentralized network for the newest information about COVID-19 patients. The main goal of this paper is to improve the recognition of a global deep learning model using, novel and up-to-date data, and learn itself from such data to improve recognition of COVID-19 patients based on computed tomography (CT) slices. Moreover, the integration of blockchain and federated-learning technology collects the data from different hospitals without leakage the privacy of the data. Firstly, we collect real-life COVID-19 patients data open to the research community. Secondly, we use various deep learning models (VGG, DenseNet, AlexNet, MobileNet, ResNet, and Capsule Network) to recognize the patterns via COVID-19 patients' lung screening. Thirdly, securely share the data among various hospitals with the integration of federated learning and blockchain. Finally, our results demonstrate a better performance to detect COVID-19 patients.
A New Corpus for Low-Resourced Sindhi Language with Word Embeddings
Dec 02, 2019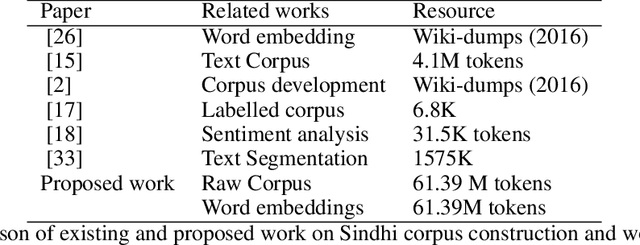
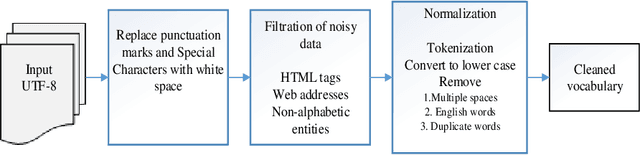
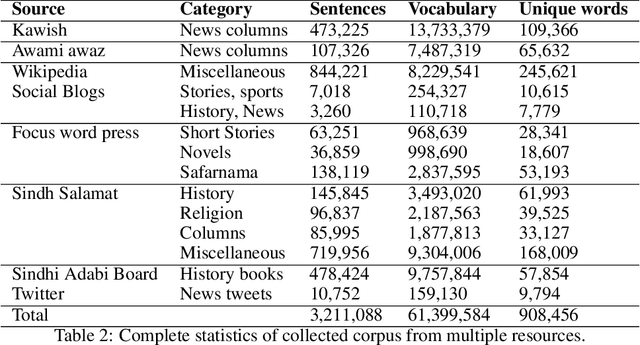
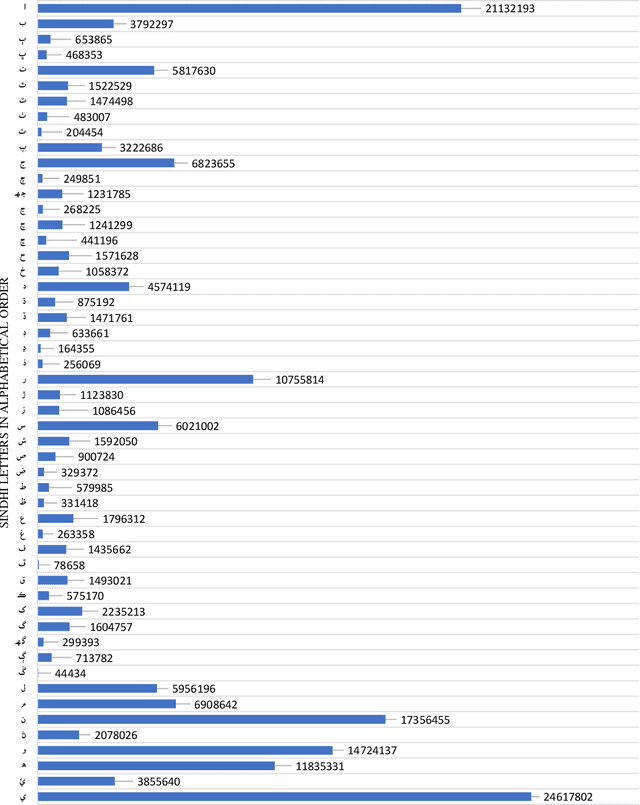
Representing words and phrases into dense vectors of real numbers which encode semantic and syntactic properties is a vital constituent in natural language processing (NLP). The success of neural network (NN) models in NLP largely rely on such dense word representations learned on the large unlabeled corpus. Sindhi is one of the rich morphological language, spoken by large population in Pakistan and India lacks corpora which plays an essential role of a test-bed for generating word embeddings and developing language independent NLP systems. In this paper, a large corpus of more than 61 million words is developed for low-resourced Sindhi language for training neural word embeddings. The corpus is acquired from multiple web-resources using web-scrappy. Due to the unavailability of open source preprocessing tools for Sindhi, the prepossessing of such large corpus becomes a challenging problem specially cleaning of noisy data extracted from web resources. Therefore, a preprocessing pipeline is employed for the filtration of noisy text. Afterwards, the cleaned vocabulary is utilized for training Sindhi word embeddings with state-of-the-art GloVe, Skip-Gram (SG), and Continuous Bag of Words (CBoW) word2vec algorithms. The intrinsic evaluation approach of cosine similarity matrix and WordSim-353 are employed for the evaluation of generated Sindhi word embeddings. Moreover, we compare the proposed word embeddings with recently revealed Sindhi fastText (SdfastText) word representations. Our intrinsic evaluation results demonstrate the high quality of our generated Sindhi word embeddings using SG, CBoW, and GloVe as compare to SdfastText word representations.