 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Paradox of Outcome Optimization: A Causal Information-Theoretic Bound on Reasoning Shortcuts in LLMs
May 30, 2026Large Language Models (LLMs) aligned via outcome-based Reinforcement Learning (RL) frequently exhibit a critical failure mode: they achieve high performance on in-distribution benchmarks while demonstrating brittle reasoning capabilities on out-of-distribution (OOD) tasks. We term this phenomenon Reward-Induced Manifold Collapse. We establish a theoretical framework bridging Structural Causal Models (SCM) and the Information Bottleneck (IB) principle to explain this paradox. We define reasoning as a high-complexity causal process and shortcut learning as the exploitation of low-complexity spurious correlations. Under the implicit inductive bias of Stochastic Gradient Descent (SGD), models optimized for outcome rewards are biased toward shortcut solutions whenever the training distribution allows for a ``Markovian Screening'' of the true causal mechanism. We derive a new generalization bound based on Semantic Coverage Measure ($η$) rather than sample size, showing why data scaling on homogeneous distributions may fail to correct reasoning flaws. We also show that Process Reward Models (PRMs) function as Topological Filters, enforcing step-wise mutual information constraints that render the low-complexity shortcut manifold inadmissible. These results provide a mathematical grounding for the role of process supervision beyond simple credit assignment.
DINORANKCLIP: DINOv3 Distillation and Injection for Vision-Language Pretraining with High-Order Ranking Consistency
May 07, 2026Contrastive language-image pretraining (CLIP) suffers from two structural weaknesses: the symmetric InfoNCE loss discards the relative ordering among unmatched in-batch pairs, and global pooling collapses the visual representation into a semantic bottleneck that is poorly sensitive to fine-grained local structure. RANKCLIP partially addresses the first issue with a list-wise Plackett-Luce ranking-consistency loss, but its model is strictly first-order and inherits the second weakness untouched. We propose DINORANKCLIP, a pretraining framework that addresses both jointly. Our principal contribution is injecting a frozen DINOv3 teacher into the contrastive trunk through a dual-branch lightweight student and a multi-scale fusion module with channel-spatial attention, a self-attention refiner, and a conflict-aware gate that preserves the cross-modal alignment up to first order. Complementarily, we introduce a high-order Plackett-Luce ranking model in which the per-position utility is augmented with attention-parameterised pairwise and tuple-wise transition terms; the family contains CLIP and RANKCLIP as nested zero-order and first-order special cases, and the optimal order on every benchmark is $R^*=3$. The full empirical study -- order sweep, Fine-grained Probe on five datasets, four-node Modality-Gap analysis, six-variant Fusion ablation -- fits in 72 hours on a single eight-GPU H100 node and trains entirely on Conceptual Captions 3M. DINORANKCLIP consistently outperforms CLIP, CyCLIP, ALIP, and RANKCLIP under matched compute, with the largest relative gains on the fine-grained and out-of-distribution evaluations that most directly stress local structural reasoning.
Hallucination as a Computational Boundary: A Hierarchy of Inevitability and the Oracle Escape
Aug 10, 2025



The illusion phenomenon of large language models (LLMs) is the core obstacle to their reliable deployment. This article formalizes the large language model as a probabilistic Turing machine by constructing a "computational necessity hierarchy", and for the first time proves the illusions are inevitable on diagonalization, incomputability, and information theory boundaries supported by the new "learner pump lemma". However, we propose two "escape routes": one is to model Retrieval Enhanced Generations (RAGs) as oracle machines, proving their absolute escape through "computational jumps", providing the first formal theory for the effectiveness of RAGs; The second is to formalize continuous learning as an "internalized oracle" mechanism and implement this path through a novel neural game theory framework.Finally, this article proposes a
Multi-Agent Synergy-Driven Iterative Visual Narrative Synthesis
Jul 17, 2025Automated generation of high-quality media presentations is challenging, requiring robust content extraction, narrative planning, visual design, and overall quality optimization. Existing methods often produce presentations with logical inconsistencies and suboptimal layouts, thereby struggling to meet professional standards. To address these challenges, we introduce RCPS (Reflective Coherent Presentation Synthesis), a novel framework integrating three key components: (1) Deep Structured Narrative Planning; (2) Adaptive Layout Generation; (3) an Iterative Optimization Loop. Additionally, we propose PREVAL, a preference-based evaluation framework employing rationale-enhanced multi-dimensional models to assess presentation quality across Content, Coherence, and Design. Experimental results demonstrate that RCPS significantly outperforms baseline methods across all quality dimensions, producing presentations that closely approximate human expert standards. PREVAL shows strong correlation with human judgments, validating it as a reliable automated tool for assessing presentation quality.
FRAME: Feedback-Refined Agent Methodology for Enhancing Medical Research Insights
May 06, 2025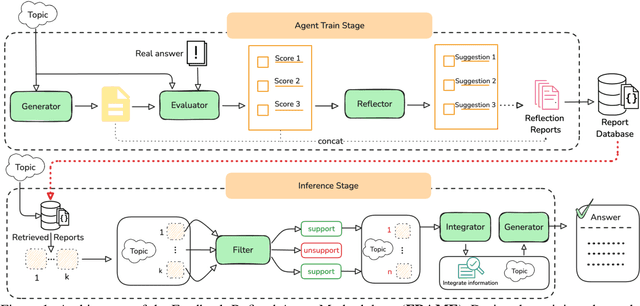
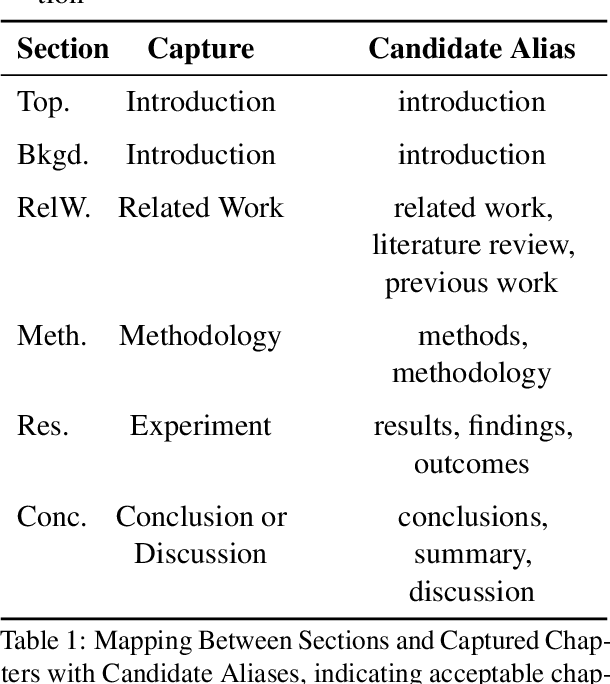
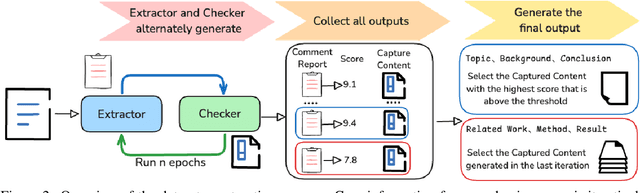

The automation of scientific research through large language models (LLMs) presents significant opportunities but faces critical challenges in knowledge synthesis and quality assurance. We introduce Feedback-Refined Agent Methodology (FRAME), a novel framework that enhances medical paper generation through iterative refinement and structured feedback. Our approach comprises three key innovations: (1) A structured dataset construction method that decomposes 4,287 medical papers into essential research components through iterative refinement; (2) A tripartite architecture integrating Generator, Evaluator, and Reflector agents that progressively improve content quality through metric-driven feedback; and (3) A comprehensive evaluation framework that combines statistical metrics with human-grounded benchmarks. Experimental results demonstrate FRAME's effectiveness, achieving significant improvements over conventional approaches across multiple models (9.91% average gain with DeepSeek V3, comparable improvements with GPT-4o Mini) and evaluation dimensions. Human evaluation confirms that FRAME-generated papers achieve quality comparable to human-authored works, with particular strength in synthesizing future research directions. The results demonstrated our work could efficiently assist medical research by building a robust foundation for automated medical research paper generation while maintaining rigorous academic standards.
IIMedGPT: Promoting Large Language Model Capabilities of Medical Tasks by Efficient Human Preference Alignment
Jan 06, 2025Recent researches of large language models(LLM), which is pre-trained on massive general-purpose corpora, have achieved breakthroughs in responding human queries. However, these methods face challenges including limited data insufficiency to support extensive pre-training and can not align responses with users' instructions. To address these issues, we introduce a medical instruction dataset, CMedINS, containing six medical instructions derived from actual medical tasks, which effectively fine-tunes LLM in conjunction with other data. Subsequently, We launch our medical model, IIMedGPT, employing an efficient preference alignment method, Direct preference Optimization(DPO). The results show that our final model outperforms existing medical models in medical dialogue.Datsets, Code and model checkpoints will be released upon acceptance.
Beyond Training: Dynamic Token Merging for Zero-Shot Video Understanding
Nov 21, 2024Recent advancements in multimodal large language models (MLLMs) have opened new avenues for video understanding. However, achieving high fidelity in zero-shot video tasks remains challenging. Traditional video processing methods rely heavily on fine-tuning to capture nuanced spatial-temporal details, which incurs significant data and computation costs. In contrast, training-free approaches, though efficient, often lack robustness in preserving context-rich features across complex video content. To this end, we propose DYTO, a novel dynamic token merging framework for zero-shot video understanding that adaptively optimizes token efficiency while preserving crucial scene details. DYTO integrates a hierarchical frame selection and a bipartite token merging strategy to dynamically cluster key frames and selectively compress token sequences, striking a balance between computational efficiency with semantic richness. Extensive experiments across multiple benchmarks demonstrate the effectiveness of DYTO, achieving superior performance compared to both fine-tuned and training-free methods and setting a new state-of-the-art for zero-shot video understanding.
RankCLIP: Ranking-Consistent Language-Image Pretraining
Apr 15, 2024Among the ever-evolving development of vision-language models, contrastive language-image pretraining (CLIP) has set new benchmarks in many downstream tasks such as zero-shot classifications by leveraging self-supervised contrastive learning on large amounts of text-image pairs. However, its dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RankCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By leveraging both in-modal and cross-modal ranking consistency, RankCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the enhanced capability of RankCLIP to effectively improve performance across various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the potential of RankCLIP in further advancing vision-language pretraining.