 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Synergy-Driven Iterative Visual Narrative Synthesis
Jul 17, 2025Automated generation of high-quality media presentations is challenging, requiring robust content extraction, narrative planning, visual design, and overall quality optimization. Existing methods often produce presentations with logical inconsistencies and suboptimal layouts, thereby struggling to meet professional standards. To address these challenges, we introduce RCPS (Reflective Coherent Presentation Synthesis), a novel framework integrating three key components: (1) Deep Structured Narrative Planning; (2) Adaptive Layout Generation; (3) an Iterative Optimization Loop. Additionally, we propose PREVAL, a preference-based evaluation framework employing rationale-enhanced multi-dimensional models to assess presentation quality across Content, Coherence, and Design. Experimental results demonstrate that RCPS significantly outperforms baseline methods across all quality dimensions, producing presentations that closely approximate human expert standards. PREVAL shows strong correlation with human judgments, validating it as a reliable automated tool for assessing presentation quality.
TargetUM: Targeted High-Utility Itemset Querying
Oct 30, 2021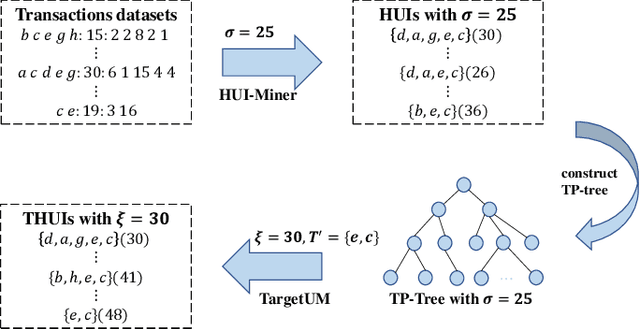
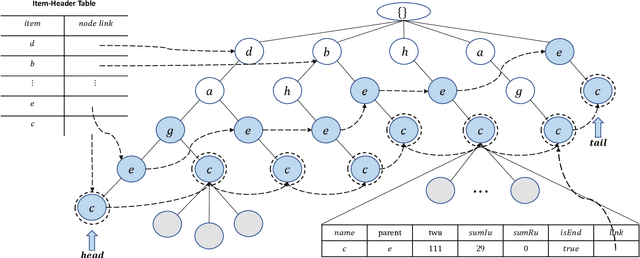
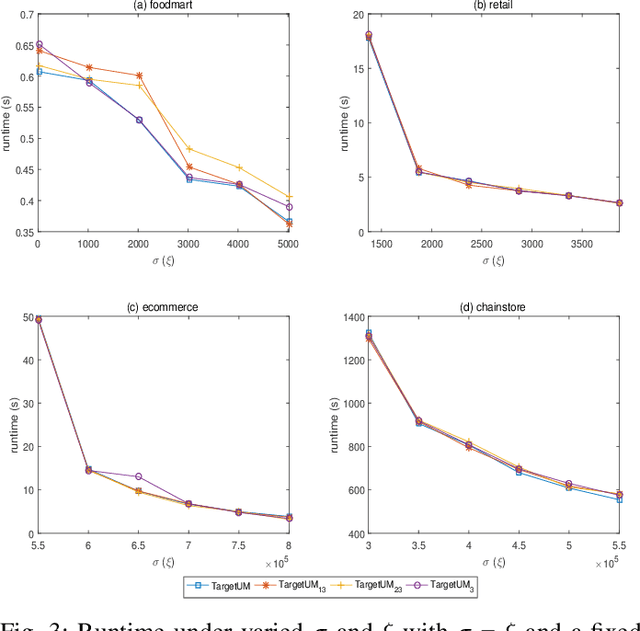
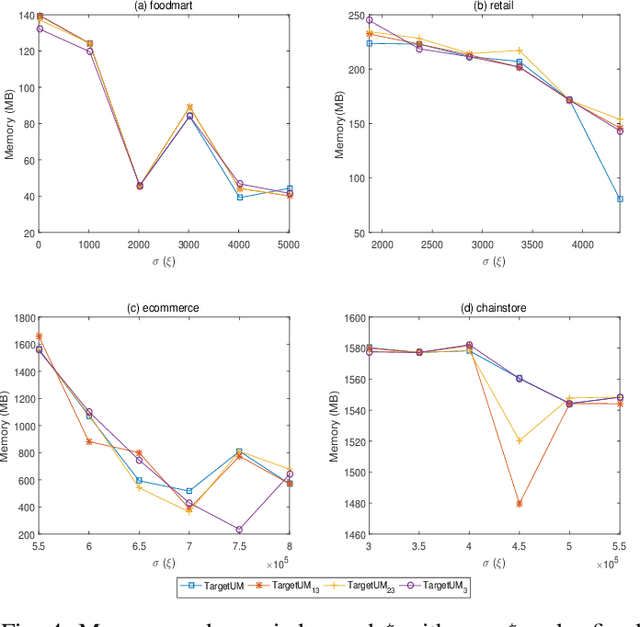
Traditional high-utility itemset mining (HUIM) aims to determine all high-utility itemsets (HUIs) that satisfy the minimum utility threshold (\textit{minUtil}) in transaction databases. However, in most applications, not all HUIs are interesting because only specific parts are required. Thus, targeted mining based on user preferences is more important than traditional mining tasks. This paper is the first to propose a target-based HUIM problem and to provide a clear formulation of the targeted utility mining task in a quantitative transaction database. A tree-based algorithm known as Target-based high-Utility iteMset querying using (TargetUM) is proposed. The algorithm uses a lexicographic querying tree and three effective pruning strategies to improve the mining efficiency. We implemented experimental validation on several real and synthetic databases, and the results demonstrate that the performance of \textbf{TargetUM} is satisfactory, complete, and correct. Finally, owing to the lexicographic querying tree, the database no longer needs to be scanned repeatedly for multiple queries.