 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Medical Triage under Uncertainty: A Multi-Agent Dynamic Matching Approach
Jul 30, 2025



The post-pandemic surge in healthcare demand, coupled with critical nursing shortages, has placed unprecedented pressure on emergency department triage systems, necessitating innovative AI-driven solutions. We present a multi-agent interactive intelligent system for medical triage that addresses three fundamental challenges in current AI-based triage systems: insufficient medical specialization leading to hallucination-induced misclassifications, heterogeneous department structures across healthcare institutions, and inefficient detail-oriented questioning that impedes rapid triage decisions. Our system employs three specialized agents - RecipientAgent, InquirerAgent, and DepartmentAgent - that collaborate through structured inquiry mechanisms and department-specific guidance rules to transform unstructured patient symptoms into accurate department recommendations. To ensure robust evaluation, we constructed a comprehensive Chinese medical triage dataset from a medical website, comprising 3,360 real-world cases spanning 9 primary departments and 62 secondary departments. Through systematic data imputation using large language models, we address the prevalent issue of incomplete medical records in real-world data. Experimental results demonstrate that our multi-agent system achieves 89.2% accuracy in primary department classification and 73.9% accuracy in secondary department classification after four rounds of patient interaction. The system's pattern-matching-based guidance mechanisms enable efficient adaptation to diverse hospital configurations while maintaining high triage accuracy. Our work provides a scalable framework for deploying AI-assisted triage systems that can accommodate the organizational heterogeneity of healthcare institutions while ensuring clinically sound decision-making.
FRAME: Feedback-Refined Agent Methodology for Enhancing Medical Research Insights
May 06, 2025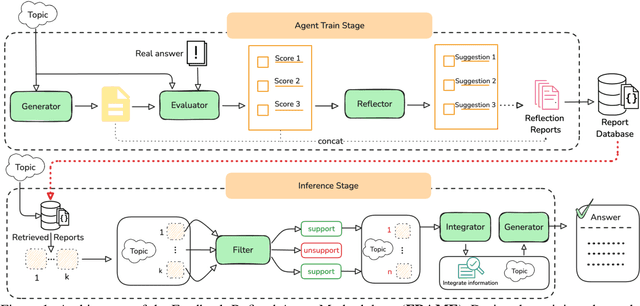
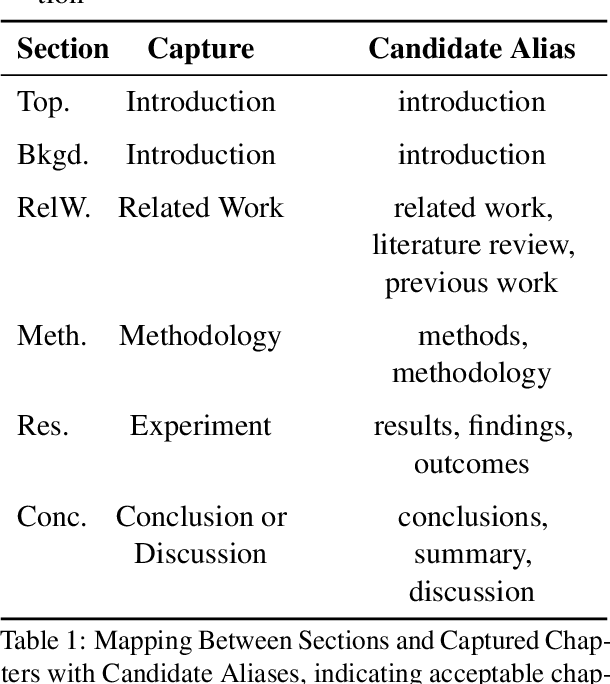
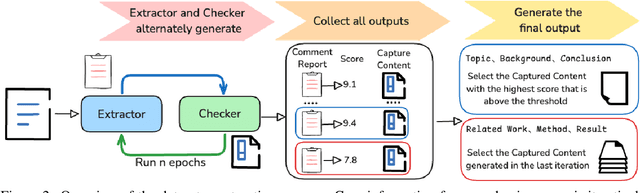

The automation of scientific research through large language models (LLMs) presents significant opportunities but faces critical challenges in knowledge synthesis and quality assurance. We introduce Feedback-Refined Agent Methodology (FRAME), a novel framework that enhances medical paper generation through iterative refinement and structured feedback. Our approach comprises three key innovations: (1) A structured dataset construction method that decomposes 4,287 medical papers into essential research components through iterative refinement; (2) A tripartite architecture integrating Generator, Evaluator, and Reflector agents that progressively improve content quality through metric-driven feedback; and (3) A comprehensive evaluation framework that combines statistical metrics with human-grounded benchmarks. Experimental results demonstrate FRAME's effectiveness, achieving significant improvements over conventional approaches across multiple models (9.91% average gain with DeepSeek V3, comparable improvements with GPT-4o Mini) and evaluation dimensions. Human evaluation confirms that FRAME-generated papers achieve quality comparable to human-authored works, with particular strength in synthesizing future research directions. The results demonstrated our work could efficiently assist medical research by building a robust foundation for automated medical research paper generation while maintaining rigorous academic standards.
A Self-supervised Pressure Map human keypoint Detection Approch: Optimizing Generalization and Computational Efficiency Across Datasets
Feb 22, 2024



In environments where RGB images are inadequate, pressure maps is a viable alternative, garnering scholarly attention. This study introduces a novel self-supervised pressure map keypoint detection (SPMKD) method, addressing the current gap in specialized designs for human keypoint extraction from pressure maps. Central to our contribution is the Encoder-Fuser-Decoder (EFD) model, which is a robust framework that integrates a lightweight encoder for precise human keypoint detection, a fuser for efficient gradient propagation, and a decoder that transforms human keypoints into reconstructed pressure maps. This structure is further enhanced by the Classification-to-Regression Weight Transfer (CRWT) method, which fine-tunes accuracy through initial classification task training. This innovation not only enhances human keypoint generalization without manual annotations but also showcases remarkable efficiency and generalization, evidenced by a reduction to only $5.96\%$ in FLOPs and $1.11\%$ in parameter count compared to the baseline methods.