 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealClawBench: Live OpenClaw Benchmarks from Real Developer-Agent Sessions
Jun 02, 2026Agent benchmarks should reflect what users actually ask deployed agents to do, yet existing benchmarks often miss key realism properties of real developer-agent sessions. We introduce RealClawBench, a live benchmark framework built from real OpenClaw sessions to capture the distribution, diversity, and real-world difficulty of deployed agent use. Real user requests are challenging to benchmark because they often depend on local execution environments, involve implicit or underspecified intent, and require nontrivial verification. RealClawBench addresses these challenges with two core mechanisms: reconstructed execution environments and deterministic verifiable scorers, which together convert real sessions into reproducible, automatically scored tasks. The resulting release contains 281 executable tasks sampled from a much larger real-session pool while preserving the source distribution, with maximum final-vs-source Jensen-Shannon divergence of 0.0448. Evaluating 14 contemporary models shows that the best system solves only 65.8% of tasks, revealing substantial headroom on realistic developer-agent workloads. By turning real deployed sessions into controlled evaluation instances, RealClawBench provides a practical path toward benchmarks that better measure agent capability in actual use. Code is available at:https://anonymous.4open.science/r/real-claw-bench-582B.
Harness-Bench: Measuring Harness Effects across Models in Realistic Agent Workflows
May 27, 2026LLM agents are increasingly deployed as executable systems that use tools, modify workspaces, and produce concrete artifacts. In such workflows, performance depends not only on the base model, but also on the harness: the system layer that manages context, tools, state, constraints, permissions, tracing, and recovery. However, existing benchmarks typically abstract away execution, compare complete agent systems, or hold the harness fixed, making execution-layer variation difficult to study. We introduce Harness-Bench, a diagnostic benchmark for evaluating configuration-level harness effects in realistic agent workflows. Harness-Bench evaluates representative harness configurations across multiple model backends under shared task environments, budgets, and evaluation protocols, while preserving each harness's native execution behavior. The benchmark contains 106 sandboxed offline tasks constructed from practical agent-use patterns and manually reviewed for realism, solvability, oracle-checkability, and integrity. Each run records final artifacts, execution traces, usage statistics, and validator outputs, enabling analysis beyond final completion. Across 5,194 execution trajectories, we observe substantial variation in completion, process quality, efficiency, and failure behavior across model-harness pairings. These results suggest that agent capability should be reported at the model-harness configuration level rather than attributed to the base model alone. Our analysis further identifies recurring execution-alignment failures, where plausible reasoning becomes decoupled from tool feedback, workspace state, evidence, or verifiable output contracts. Harness-Bench provides a reproducible foundation for diagnosing and improving reliable, efficient, and auditable agent execution stacks.
SHM-Agents: A Generalist-Specialist Integrated Agent System for Structural Health Monitoring
May 13, 2026Artificial intelligence is increasingly used to simplify complex tasks. In engineering applications of structural health monitoring (SHM), existing specialized algorithms, while effective, often face high implementation barriers, limited interoperability and complex training procedures. To overcome these challenges, this paper proposes SHM-Agents, a generalist-specialist agent system that integrates the reasoning and planning abilities of large language models with the problem-solving strengths of specialized algorithms. SHM-Agents enables end-to-end execution of single and combined SHM tasks via natural language, supports deep learning pre-training to simplify deployment and allows flexible expansion through a modular design. Experiments on a long-span cable-stayed bridge show that SHM-Agents can accurately and efficiently perform diverse SHM tasks, including data anomaly diagnosis and recovery, signal processing, statistical analysis, modal identification, damage identification, finite element model updating, vehicle load modeling, response calculation, reliability assessment, fatigue estimation and bridge knowledge Q\&A.
FedNSAM:Consistency of Local and Global Flatness for Federated Learning
Feb 27, 2026In federated learning (FL), multi-step local updates and data heterogeneity usually lead to sharper global minima, which degrades the performance of the global model. Popular FL algorithms integrate sharpness-aware minimization (SAM) into local training to address this issue. However, in the high data heterogeneity setting, the flatness in local training does not imply the flatness of the global model. Therefore, minimizing the sharpness of the local loss surfaces on the client data does not enable the effectiveness of SAM in FL to improve the generalization ability of the global model. We define the \textbf{flatness distance} to explain this phenomenon. By rethinking the SAM in FL and theoretically analyzing the \textbf{flatness distance}, we propose a novel \textbf{FedNSAM} algorithm that accelerates the SAM algorithm by introducing global Nesterov momentum into the local update to harmonize the consistency of global and local flatness. \textbf{FedNSAM} uses the global Nesterov momentum as the direction of local estimation of client global perturbations and extrapolation. Theoretically, we prove a tighter convergence bound than FedSAM by Nesterov extrapolation. Empirically, we conduct comprehensive experiments on CNN and Transformer models to verify the superior performance and efficiency of \textbf{FedNSAM}. The code is available at https://github.com/junkangLiu0/FedNSAM.
Beyond Parameter Arithmetic: Sparse Complementary Fusion for Distribution-Aware Model Merging
Feb 12, 2026Model merging has emerged as a promising paradigm for composing the capabilities of large language models by directly operating in weight space, enabling the integration of specialized models without costly retraining. However, existing merging methods largely rely on parameter-space heuristics, which often introduce severe interference, leading to degraded generalization and unstable generation behaviors such as repetition and incoherent outputs. In this work, we propose Sparse Complementary Fusion with reverse KL (SCF-RKL), a novel model merging framework that explicitly controls functional interference through sparse, distribution-aware updates. Instead of assuming linear additivity in parameter space, SCF-RKL measures the functional divergence between models using reverse Kullback-Leibler divergence and selectively incorporates complementary parameters. This mode-seeking, sparsity-inducing design effectively preserves stable representations while integrating new capabilities. We evaluate SCF-RKL across a wide range of model scales and architectures, covering both reasoning-focused and instruction-tuned models. Extensive experiments on 24 benchmarks spanning advanced reasoning, general reasoning and knowledge, instruction following, and safety demonstrate, vision classification that SCF-RKL consistently outperforms existing model merging methods while maintaining strong generalization and generation stability.
Scaling Up AI-Generated Image Detection via Generator-Aware Prototypes
Dec 15, 2025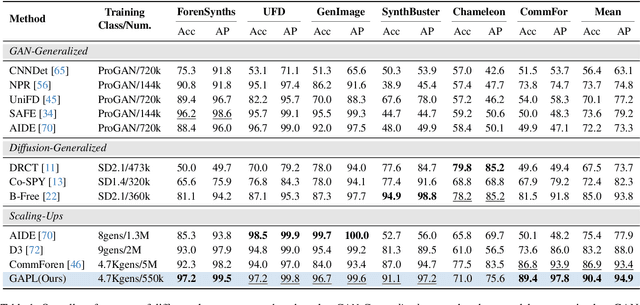
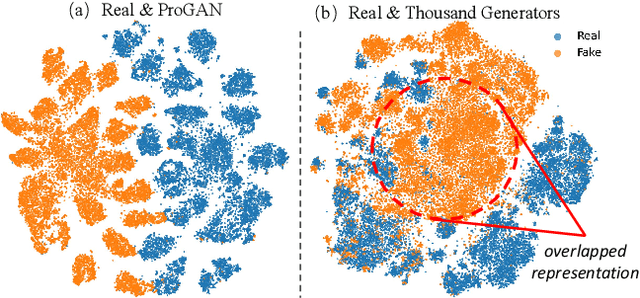
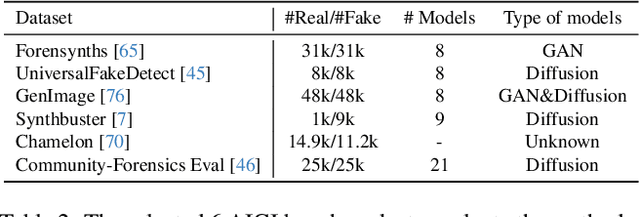
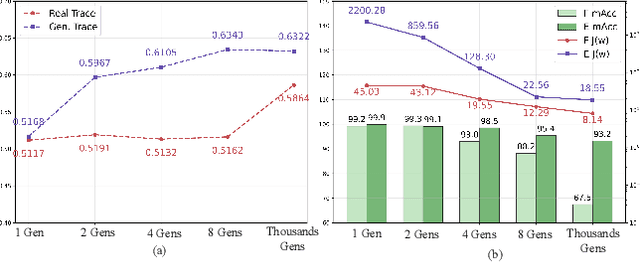
The pursuit of a universal AI-generated image (AIGI) detector often relies on aggregating data from numerous generators to improve generalization. However, this paper identifies a paradoxical phenomenon we term the Benefit then Conflict dilemma, where detector performance stagnates and eventually degrades as source diversity expands. Our systematic analysis, diagnoses this failure by identifying two core issues: severe data-level heterogeneity, which causes the feature distributions of real and synthetic images to increasingly overlap, and a critical model-level bottleneck from fixed, pretrained encoders that cannot adapt to the rising complexity. To address these challenges, we propose Generator-Aware Prototype Learning (GAPL), a framework that constrain representation with a structured learning paradigm. GAPL learns a compact set of canonical forgery prototypes to create a unified, low-variance feature space, effectively countering data heterogeneity.To resolve the model bottleneck, it employs a two-stage training scheme with Low-Rank Adaptation, enhancing its discriminative power while preserving valuable pretrained knowledge. This approach establishes a more robust and generalizable decision boundary. Through extensive experiments, we demonstrate that GAPL achieves state-of-the-art performance, showing superior detection accuracy across a wide variety of GAN and diffusion-based generators. Code is available at https://github.com/UltraCapture/GAPL
DP-FedPGN: Finding Global Flat Minima for Differentially Private Federated Learning via Penalizing Gradient Norm
Oct 31, 2025To prevent inference attacks in Federated Learning (FL) and reduce the leakage of sensitive information, Client-level Differentially Private Federated Learning (CL-DPFL) is widely used. However, current CL-DPFL methods usually result in sharper loss landscapes, which leads to a decrease in model generalization after differential privacy protection. By using Sharpness Aware Minimization (SAM), the current popular federated learning methods are to find a local flat minimum value to alleviate this problem. However, the local flatness may not reflect the global flatness in CL-DPFL. Therefore, to address this issue and seek global flat minima of models, we propose a new CL-DPFL algorithm, DP-FedPGN, in which we introduce a global gradient norm penalty to the local loss to find the global flat minimum. Moreover, by using our global gradient norm penalty, we not only find a flatter global minimum but also reduce the locally updated norm, which means that we further reduce the error of gradient clipping. From a theoretical perspective, we analyze how DP-FedPGN mitigates the performance degradation caused by DP. Meanwhile, the proposed DP-FedPGN algorithm eliminates the impact of data heterogeneity and achieves fast convergence. We also use R\'enyi DP to provide strict privacy guarantees and provide sensitivity analysis for local updates. Finally, we conduct effectiveness tests on both ResNet and Transformer models, and achieve significant improvements in six visual and natural language processing tasks compared to existing state-of-the-art algorithms. The code is available at https://github.com/junkangLiu0/DP-FedPGN
KeepKV: Eliminating Output Perturbation in KV Cache Compression for Efficient LLMs Inference
Apr 14, 2025



Efficient inference of large language models (LLMs) is hindered by an ever-growing key-value (KV) cache, making KV cache compression a critical research direction. Traditional methods selectively evict less important KV cache entries based on attention scores or position heuristics, which leads to information loss and hallucinations. Recently, merging-based strategies have been explored to retain more information by merging KV pairs that would be discarded; however, these existing approaches inevitably introduce inconsistencies in attention distributions before and after merging, causing output perturbation and degraded generation quality. To overcome this challenge, we propose KeepKV, a novel adaptive KV cache merging method designed to eliminate output perturbation while preserving performance under strict memory constraints. KeepKV introduces the Electoral Votes mechanism that records merging history and adaptively adjusts attention scores. Moreover, it further leverages a novel Zero Inference-Perturbation Merging methods, keeping attention consistency and compensating for attention loss resulting from cache merging. KeepKV successfully retains essential context information within a significantly compressed cache. Extensive experiments on various benchmarks and LLM architectures demonstrate that KeepKV substantially reduces memory usage, enhances inference throughput by more than 2x and keeps superior generation quality even with 10% KV cache budgets.
FairKV: Balancing Per-Head KV Cache for Fast Multi-GPU Inference
Feb 19, 2025



KV cache techniques in Transformer models aim to reduce redundant computations at the expense of substantially increased memory usage, making KV cache compression an important and popular research topic. Recently, state-of-the-art KV cache compression methods implement imbalanced, per-head allocation algorithms that dynamically adjust the KV cache budget for each attention head, achieving excellent performance in single-GPU scenarios. However, we observe that such imbalanced compression leads to significant load imbalance when deploying multi-GPU inference, as some GPUs become overburdened while others remain underutilized. In this paper, we propose FairKV, a method designed to ensure fair memory usage among attention heads in systems employing imbalanced KV cache compression. The core technique of FairKV is Fair-Copying, which replicates a small subset of memory-intensive attention heads across GPUs using data parallelism to mitigate load imbalance. Our experiments on popular models, including LLaMA 70b and Mistral 24b model, demonstrate that FairKV increases throughput by 1.66x compared to standard tensor parallelism inference. Our code will be released as open source upon acceptance.
Prediction Is All MoE Needs: Expert Load Distribution Goes from Fluctuating to Stabilizing
Apr 25, 2024



MoE facilitates the development of large models by making the computational complexity of the model no longer scale linearly with increasing parameters. The learning sparse gating network selects a set of experts for each token to be processed; however, this may lead to differences in the number of tokens processed by each expert over several successive iterations, i.e., the expert load fluctuations, which reduces computational parallelization and resource utilization. To this end, we traced and analyzed loads of each expert in the training iterations for several large language models in this work, and defined the transient state with "obvious load fluctuation" and the stable state with "temporal locality". Moreover, given the characteristics of these two states and the computational overhead, we deployed three classical prediction algorithms that achieve accurate expert load prediction results. For the GPT3 350M model, the average error rates for predicting the expert load proportion over the next 1,000 and 2,000 steps are approximately 1.3% and 1.8%, respectively. This work can provide valuable guidance for expert placement or resource allocation for MoE model training. Based on this work, we will propose an expert placement scheme for transient and stable states in our coming work.