 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEN3D: Generating Domain-Free 3D Scenes from a Single Image
Nov 18, 2025Despite recent advancements in neural 3D reconstruction, the dependence on dense multi-view captures restricts their broader applicability. Additionally, 3D scene generation is vital for advancing embodied AI and world models, which depend on diverse, high-quality scenes for learning and evaluation. In this work, we propose Gen3d, a novel method for generation of high-quality, wide-scope, and generic 3D scenes from a single image. After the initial point cloud is created by lifting the RGBD image, Gen3d maintains and expands its world model. The 3D scene is finalized through optimizing a Gaussian splatting representation. Extensive experiments on diverse datasets demonstrate the strong generalization capability and superior performance of our method in generating a world model and Synthesizing high-fidelity and consistent novel views.
Test-Time Iterative Error Correction for Efficient Diffusion Models
Nov 09, 2025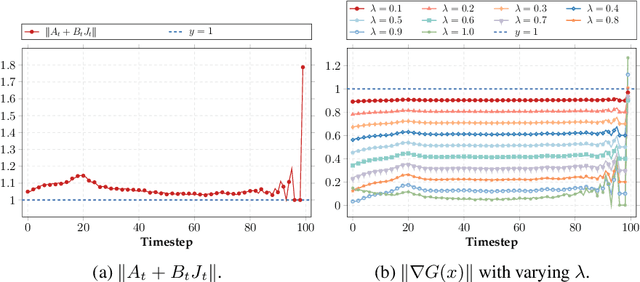

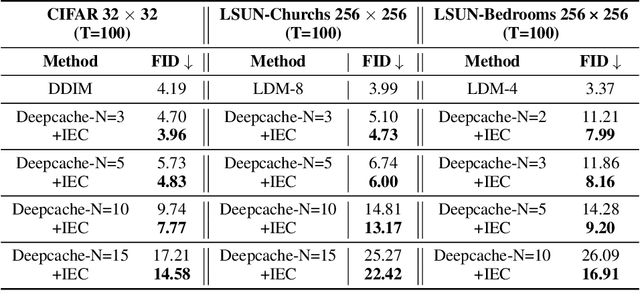

With the growing demand for high-quality image generation on resource-constrained devices, efficient diffusion models have received increasing attention. However, such models suffer from approximation errors introduced by efficiency techniques, which significantly degrade generation quality. Once deployed, these errors are difficult to correct, as modifying the model is typically infeasible in deployment environments. Through an analysis of error propagation across diffusion timesteps, we reveal that these approximation errors can accumulate exponentially, severely impairing output quality. Motivated by this insight, we propose Iterative Error Correction (IEC), a novel test-time method that mitigates inference-time errors by iteratively refining the model's output. IEC is theoretically proven to reduce error propagation from exponential to linear growth, without requiring any retraining or architectural changes. IEC can seamlessly integrate into the inference process of existing diffusion models, enabling a flexible trade-off between performance and efficiency. Extensive experiments show that IEC consistently improves generation quality across various datasets, efficiency techniques, and model architectures, establishing it as a practical and generalizable solution for test-time enhancement of efficient diffusion models.
Step-Audio-EditX Technical Report
Nov 05, 2025


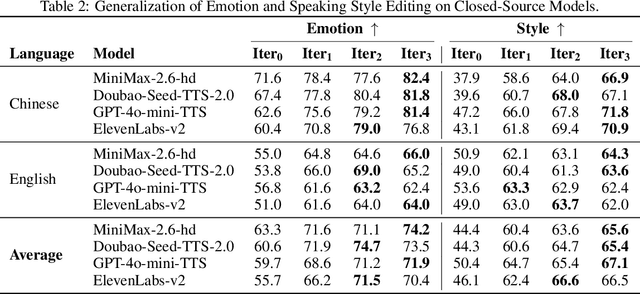
We present Step-Audio-EditX, the first open-source LLM-based audio model excelling at expressive and iterative audio editing encompassing emotion, speaking style, and paralinguistics alongside robust zero-shot text-to-speech (TTS) capabilities.Our core innovation lies in leveraging only large-margin synthetic data, which circumvents the need for embedding-based priors or auxiliary modules. This large-margin learning approach enables both iterative control and high expressivity across voices, and represents a fundamental pivot from the conventional focus on representation-level disentanglement. Evaluation results demonstrate that Step-Audio-EditX surpasses both MiniMax-2.6-hd and Doubao-Seed-TTS-2.0 in emotion editing and other fine-grained control tasks.
Spotlight Attention: Towards Efficient LLM Generation via Non-linear Hashing-based KV Cache Retrieval
Aug 27, 2025



Reducing the key-value (KV) cache burden in Large Language Models (LLMs) significantly accelerates inference. Dynamically selecting critical KV caches during decoding helps maintain performance. Existing methods use random linear hashing to identify important tokens, but this approach is inefficient due to the orthogonal distribution of queries and keys within two narrow cones in LLMs. We introduce Spotlight Attention, a novel method that employs non-linear hashing functions to optimize the embedding distribution of queries and keys, enhancing coding efficiency and robustness. We also developed a lightweight, stable training framework using a Bradley-Terry ranking-based loss, enabling optimization of the non-linear hashing module on GPUs with 16GB memory in 8 hours. Experimental results show that Spotlight Attention drastically improves retrieval precision while shortening the length of the hash code at least 5$\times$ compared to traditional linear hashing. Finally, we exploit the computational advantages of bitwise operations by implementing specialized CUDA kernels, achieving hashing retrieval for 512K tokens in under 100$\mu$s on a single A100 GPU, with end-to-end throughput up to 3$\times$ higher than vanilla decoding.
Pandora: Leveraging Code-driven Knowledge Transfer for Unified Structured Knowledge Reasoning
Aug 25, 2025Unified Structured Knowledge Reasoning (USKR) aims to answer natural language questions by using structured sources such as tables, databases, and knowledge graphs in a unified way. Existing USKR methods rely on task-specific strategies or bespoke representations, which hinder their ability to dismantle barriers between different SKR tasks, thereby constraining their overall performance in cross-task scenarios. In this paper, we introduce \textsc{Pandora}, a novel USKR framework that addresses the limitations of existing methods by leveraging two key innovations. First, we propose a code-based unified knowledge representation using \textsc{Python}'s \textsc{Pandas} API, which aligns seamlessly with the pre-training of LLMs. This representation facilitates a cohesive approach to handling different structured knowledge sources. Building on this foundation, we employ knowledge transfer to bolster the unified reasoning process of LLMs by automatically building cross-task memory. By adaptively correcting reasoning using feedback from code execution, \textsc{Pandora} showcases impressive unified reasoning capabilities. Extensive experiments on six widely used benchmarks across three SKR tasks demonstrate that \textsc{Pandora} outperforms existing unified reasoning frameworks and competes effectively with task-specific methods.
Levarging Learning Bias for Noisy Anomaly Detection
Aug 10, 2025This paper addresses the challenge of fully unsupervised image anomaly detection (FUIAD), where training data may contain unlabeled anomalies. Conventional methods assume anomaly-free training data, but real-world contamination leads models to absorb anomalies as normal, degrading detection performance. To mitigate this, we propose a two-stage framework that systematically exploits inherent learning bias in models. The learning bias stems from: (1) the statistical dominance of normal samples, driving models to prioritize learning stable normal patterns over sparse anomalies, and (2) feature-space divergence, where normal data exhibit high intra-class consistency while anomalies display high diversity, leading to unstable model responses. Leveraging the learning bias, stage 1 partitions the training set into subsets, trains sub-models, and aggregates cross-model anomaly scores to filter a purified dataset. Stage 2 trains the final detector on this dataset. Experiments on the Real-IAD benchmark demonstrate superior anomaly detection and localization performance under different noise conditions. Ablation studies further validate the framework's contamination resilience, emphasizing the critical role of learning bias exploitation. The model-agnostic design ensures compatibility with diverse unsupervised backbones, offering a practical solution for real-world scenarios with imperfect training data. Code is available at https://github.com/hustzhangyuxin/LLBNAD.
DS$^2$Net: Detail-Semantic Deep Supervision Network for Medical Image Segmentation
Aug 06, 2025



Deep Supervision Networks exhibit significant efficacy for the medical imaging community. Nevertheless, existing work merely supervises either the coarse-grained semantic features or fine-grained detailed features in isolation, which compromises the fact that these two types of features hold vital relationships in medical image analysis. We advocate the powers of complementary feature supervision for medical image segmentation, by proposing a Detail-Semantic Deep Supervision Network (DS$^2$Net). DS$^2$Net navigates both low-level detailed and high-level semantic feature supervision through Detail Enhance Module (DEM) and Semantic Enhance Module (SEM). DEM and SEM respectively harness low-level and high-level feature maps to create detail and semantic masks for enhancing feature supervision. This is a novel shift from single-view deep supervision to multi-view deep supervision. DS$^2$Net is also equipped with a novel uncertainty-based supervision loss that adaptively assigns the supervision strength of features within distinct scales based on their uncertainty, thus circumventing the sub-optimal heuristic design that typifies previous works. Through extensive experiments on six benchmarks captured under either colonoscopy, ultrasound and microscope, we demonstrate that DS$^2$Net consistently outperforms state-of-the-art methods for medical image analysis.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
TELEVAL: A Dynamic Benchmark Designed for Spoken Language Models in Chinese Interactive Scenarios
Jul 24, 2025Spoken language models (SLMs) have seen rapid progress in recent years, along with the development of numerous benchmarks for evaluating their performance. However, most existing benchmarks primarily focus on evaluating whether SLMs can perform complex tasks comparable to those tackled by large language models (LLMs), often failing to align with how users naturally interact in real-world conversational scenarios. In this paper, we propose TELEVAL, a dynamic benchmark specifically designed to evaluate SLMs' effectiveness as conversational agents in realistic Chinese interactive settings. TELEVAL defines three evaluation dimensions: Explicit Semantics, Paralinguistic and Implicit Semantics, and System Abilities. It adopts a dialogue format consistent with real-world usage and evaluates text and audio outputs separately. TELEVAL particularly focuses on the model's ability to extract implicit cues from user speech and respond appropriately without additional instructions. Our experiments demonstrate that despite recent progress, existing SLMs still have considerable room for improvement in natural conversational tasks. We hope that TELEVAL can serve as a user-centered evaluation framework that directly reflects the user experience and contributes to the development of more capable dialogue-oriented SLMs.
GS-Bias: Global-Spatial Bias Learner for Single-Image Test-Time Adaptation of Vision-Language Models
Jul 16, 2025Recent advances in test-time adaptation (TTA) for Vision-Language Models (VLMs) have garnered increasing attention, particularly through the use of multiple augmented views of a single image to boost zero-shot generalization. Unfortunately, existing methods fail to strike a satisfactory balance between performance and efficiency, either due to excessive overhead of tuning text prompts or unstable benefits from handcrafted, training-free visual feature enhancement. In this paper, we present Global-Spatial Bias Learner (GS-Bias), an efficient and effective TTA paradigm that incorporates two learnable biases during TTA, unfolded as the global bias and spatial bias. Particularly, the global bias captures the global semantic features of a test image by learning consistency across augmented views, while spatial bias learns the semantic coherence between regions in the image's spatial visual representation. It is worth highlighting that these two sets of biases are directly added to the logits outputed by the pretrained VLMs, which circumvent the full backpropagation through VLM that hinders the efficiency of existing TTA methods. This endows GS-Bias with extremely high efficiency while achieving state-of-the-art performance on 15 benchmark datasets. For example, it achieves a 2.23% improvement over TPT in cross-dataset generalization and a 2.72% improvement in domain generalization, while requiring only 6.5% of TPT's memory usage on ImageNet.