 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Scenes to Elements: Multi-Granularity Evidence Retrieval for Verifiable Multimodal RAG
May 14, 2026Multimodal Retrieval-Augmented Generation (RAG) systems retrieve evidence at coarse granularities (entire images or scenes), creating a mismatch with fine-grained user queries and making failures unverifiable. We introduce GranuVistaVQA, a multimodal benchmark featuring real-world landmarks with element-level annotations across multiple viewpoints, capturing the partial observation challenge where individual images contain only subsets of entities. We further propose GranuRAG, a multi-granularity framework that treats visual elements as first-class retrieval units through three stages: element-level detection and classification, multi-granularity cross-modal alignment for evidence retrieval, and attribution-constrained generation. By grounding retrieval at the element level rather than relying on implicit attention, our approach enables transparent error diagnosis. Experiments demonstrate that GranuRAG achieves up to 29.2% improvement over six strong baselines for this task.
Chain-of-Procedure: Hierarchical Visual-Language Reasoning for Procedural QA
May 14, 2026Recent advances in vision-language models (VLMs) have achieved impressive results on standard image-text tasks, yet their potential for visual procedure question answering (VP-QA) remains largely unexplored. VP-QA presents unique challenges where users query next-step actions by uploading images for intermediate states of complex procedures. To systematically evaluate VLMs on this practical task, we propose ProcedureVQA, a novel multimodal benchmark specifically designed for visual procedural reasoning. Through comprehensive analysis, we identify two critical limitations in current VLMs: inadequate cross-modal retrieval of structured procedures given visual states, and misalignment between image sequence granularity and textual step decomposition. To address these issues, we present Chain-of-Procedure (CoP), a hierarchical reasoning framework that first retrieves relevant instructions using visual cues, then performs step refinement through semantic decomposition, and finally generates the next step. Experiments across six VLMs demonstrate CoP's effectiveness, achieving up to 13% absolute improvement over standard baselines.
Not All LoRA Parameters Are Essential: Insights on Inference Necessity
Mar 30, 2025



Current research on LoRA primarily focuses on minimizing the number of fine-tuned parameters or optimizing its architecture. However, the necessity of all fine-tuned LoRA layers during inference remains underexplored. In this paper, we investigate the contribution of each LoRA layer to the model's ability to predict the ground truth and hypothesize that lower-layer LoRA modules play a more critical role in model reasoning and understanding. To address this, we propose a simple yet effective method to enhance the performance of large language models (LLMs) fine-tuned with LoRA. Specifically, we identify a ``boundary layer'' that distinguishes essential LoRA layers by analyzing a small set of validation samples. During inference, we drop all LoRA layers beyond this boundary. We evaluate our approach on three strong baselines across four widely-used text generation datasets. Our results demonstrate consistent and significant improvements, underscoring the effectiveness of selectively retaining critical LoRA layers during inference.
PMMT: Preference Alignment in Multilingual Machine Translation via LLM Distillation
Oct 15, 2024Translation is important for cross-language communication, and many efforts have been made to improve its accuracy. However, less investment is conducted in aligning translations with human preferences, such as translation tones or styles. In this paper, a new method is proposed to effectively generate large-scale multilingual parallel corpora with specific translation preferences using Large Language Models (LLMs). Meanwhile, an automatic pipeline is designed to distill human preferences into smaller Machine Translation (MT) models for efficiently and economically supporting large-scale calls in online services. Experiments indicate that the proposed method takes the lead in translation tasks with aligned human preferences by a large margin. Meanwhile, on popular public benchmarks like WMT and Flores, on which our models were not trained, the proposed method also shows a competitive performance compared to SOTA works.
A Two-Stage Prediction-Aware Contrastive Learning Framework for Multi-Intent NLU
May 05, 2024Multi-intent natural language understanding (NLU) presents a formidable challenge due to the model confusion arising from multiple intents within a single utterance. While previous works train the model contrastively to increase the margin between different multi-intent labels, they are less suited to the nuances of multi-intent NLU. They ignore the rich information between the shared intents, which is beneficial to constructing a better embedding space, especially in low-data scenarios. We introduce a two-stage Prediction-Aware Contrastive Learning (PACL) framework for multi-intent NLU to harness this valuable knowledge. Our approach capitalizes on shared intent information by integrating word-level pre-training and prediction-aware contrastive fine-tuning. We construct a pre-training dataset using a word-level data augmentation strategy. Subsequently, our framework dynamically assigns roles to instances during contrastive fine-tuning while introducing a prediction-aware contrastive loss to maximize the impact of contrastive learning. We present experimental results and empirical analysis conducted on three widely used datasets, demonstrating that our method surpasses the performance of three prominent baselines on both low-data and full-data scenarios.
DFGC 2021: A DeepFake Game Competition
Jun 02, 2021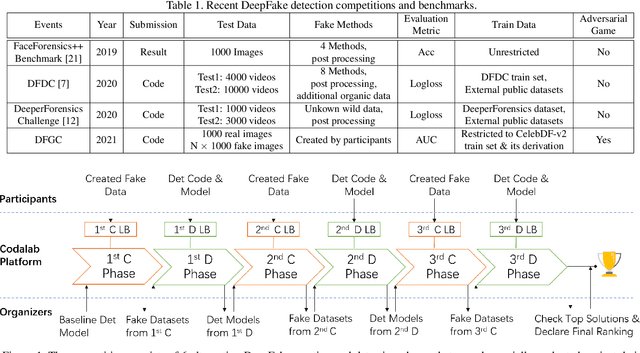
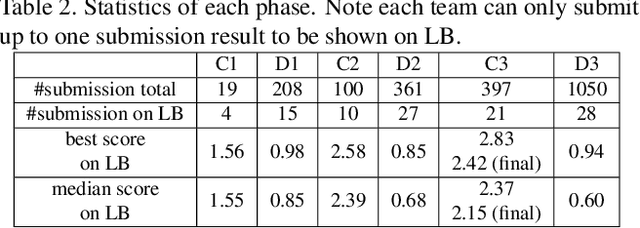
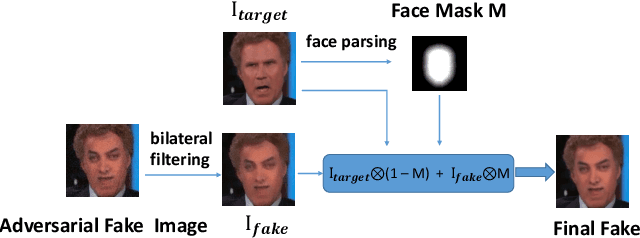
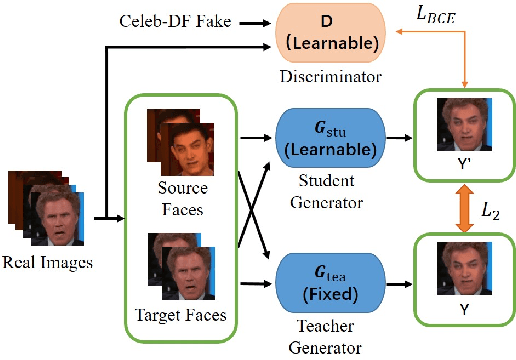
This paper presents a summary of the DFGC 2021 competition. DeepFake technology is developing fast, and realistic face-swaps are increasingly deceiving and hard to detect. At the same time, DeepFake detection methods are also improving. There is a two-party game between DeepFake creators and detectors. This competition provides a common platform for benchmarking the adversarial game between current state-of-the-art DeepFake creation and detection methods. In this paper, we present the organization, results and top solutions of this competition and also share our insights obtained during this event. We also release the DFGC-21 testing dataset collected from our participants to further benefit the research community.