 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Evaluation for Explainable AI
Sep 05, 2021
While recent years have witnessed the emergence of various explainable methods in machine learning, to what degree the explanations really represent the reasoning process behind the model prediction -- namely, the faithfulness of explanation -- is still an open problem. One commonly used way to measure faithfulness is \textit{erasure-based} criteria. Though conceptually simple, erasure-based criterion could inevitably introduce biases and artifacts. We propose a new methodology to evaluate the faithfulness of explanations from the \textit{counterfactual reasoning} perspective: the model should produce substantially different outputs for the original input and its corresponding counterfactual edited on a faithful feature. Specially, we introduce two algorithms to find the proper counterfactuals in both discrete and continuous scenarios and then use the acquired counterfactuals to measure faithfulness. Empirical results on several datasets show that compared with existing metrics, our proposed counterfactual evaluation method can achieve top correlation with the ground truth under diffe
Counterfactual Explainable Recommendation
Aug 24, 2021
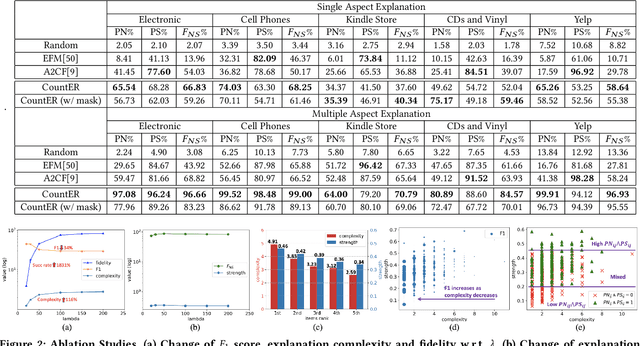
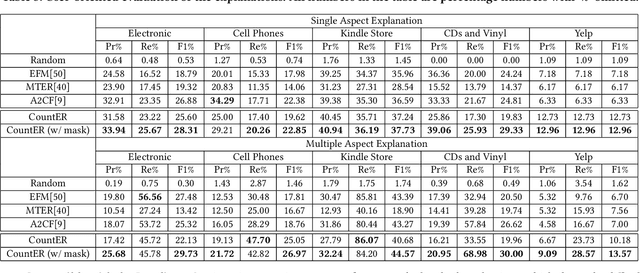
By providing explanations for users and system designers to facilitate better understanding and decision making, explainable recommendation has been an important research problem. In this paper, we propose Counterfactual Explainable Recommendation (CountER), which takes the insights of counterfactual reasoning from causal inference for explainable recommendation. CountER is able to formulate the complexity and the strength of explanations, and it adopts a counterfactual learning framework to seek simple (low complexity) and effective (high strength) explanations for the model decision. Technically, for each item recommended to each user, CountER formulates a joint optimization problem to generate minimal changes on the item aspects so as to create a counterfactual item, such that the recommendation decision on the counterfactual item is reversed. These altered aspects constitute the explanation of why the original item is recommended. The counterfactual explanation helps both the users for better understanding and the system designers for better model debugging. Another contribution of the work is the evaluation of explainable recommendation, which has been a challenging task. Fortunately, counterfactual explanations are very suitable for standard quantitative evaluation. To measure the explanation quality, we design two types of evaluation metrics, one from user's perspective (i.e. why the user likes the item), and the other from model's perspective (i.e. why the item is recommended by the model). We apply our counterfactual learning algorithm on a black-box recommender system and evaluate the generated explanations on five real-world datasets. Results show that our model generates more accurate and effective explanations than state-of-the-art explainable recommendation models.
Towards Personalized Fairness based on Causal Notion
May 20, 2021

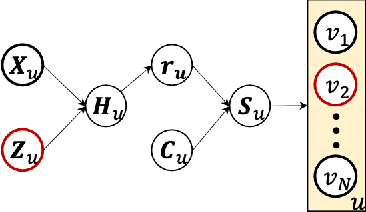
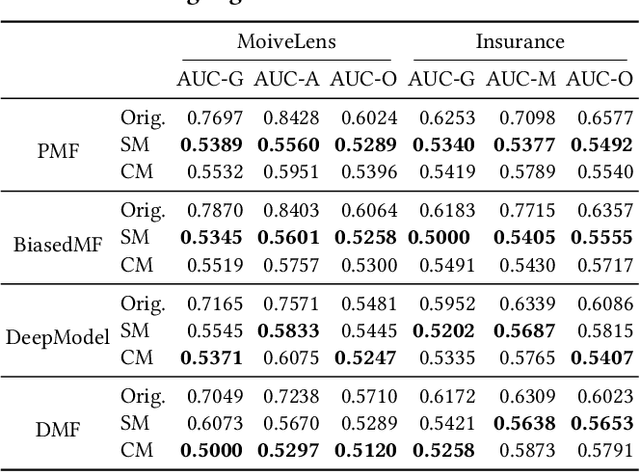
Recommender systems are gaining increasing and critical impacts on human and society since a growing number of users use them for information seeking and decision making. Therefore, it is crucial to address the potential unfairness problems in recommendations. Just like users have personalized preferences on items, users' demands for fairness are also personalized in many scenarios. Therefore, it is important to provide personalized fair recommendations for users to satisfy their personalized fairness demands. Besides, previous works on fair recommendation mainly focus on association-based fairness. However, it is important to advance from associative fairness notions to causal fairness notions for assessing fairness more properly in recommender systems. Based on the above considerations, this paper focuses on achieving personalized counterfactual fairness for users in recommender systems. To this end, we introduce a framework for achieving counterfactually fair recommendations through adversary learning by generating feature-independent user embeddings for recommendation. The framework allows recommender systems to achieve personalized fairness for users while also covering non-personalized situations. Experiments on two real-world datasets with shallow and deep recommendation algorithms show that our method can generate fairer recommendations for users with a desirable recommendation performance.
User-oriented Fairness in Recommendation
Apr 21, 2021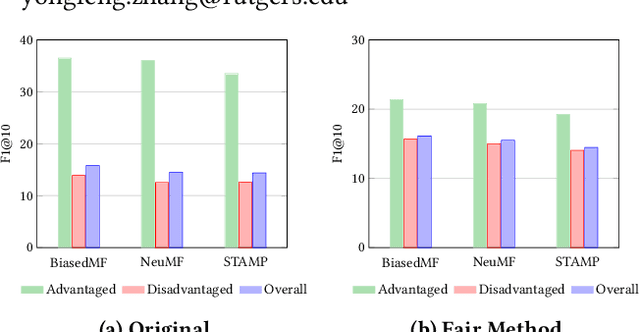
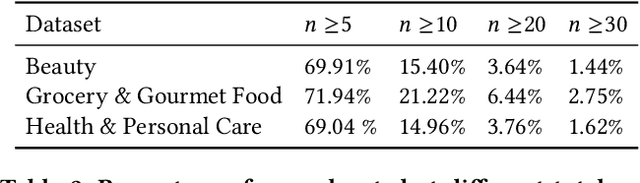
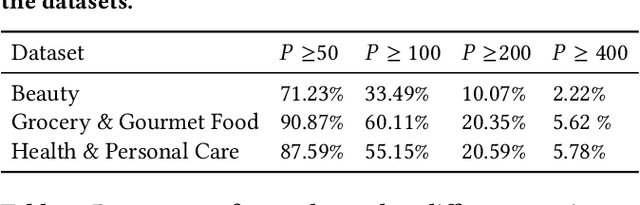
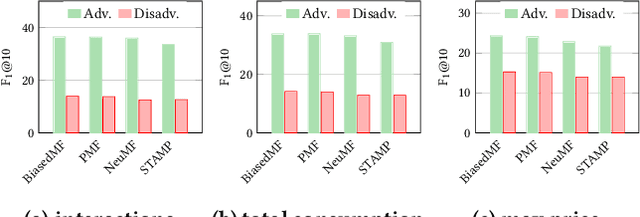
As a highly data-driven application, recommender systems could be affected by data bias, resulting in unfair results for different data groups, which could be a reason that affects the system performance. Therefore, it is important to identify and solve the unfairness issues in recommendation scenarios. In this paper, we address the unfairness problem in recommender systems from the user perspective. We group users into advantaged and disadvantaged groups according to their level of activity, and conduct experiments to show that current recommender systems will behave unfairly between two groups of users. Specifically, the advantaged users (active) who only account for a small proportion in data enjoy much higher recommendation quality than those disadvantaged users (inactive). Such bias can also affect the overall performance since the disadvantaged users are the majority. To solve this problem, we provide a re-ranking approach to mitigate this unfairness problem by adding constraints over evaluation metrics. The experiments we conducted on several real-world datasets with various recommendation algorithms show that our approach can not only improve group fairness of users in recommender systems, but also achieve better overall recommendation performance.
Causal Collaborative Filtering
Feb 10, 2021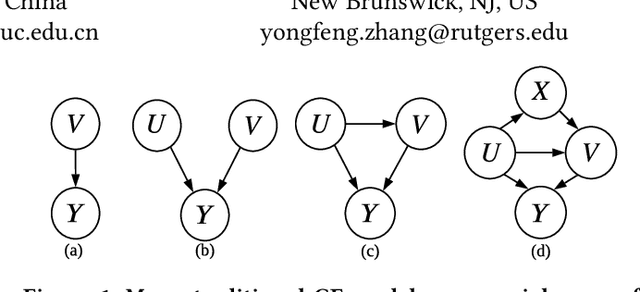

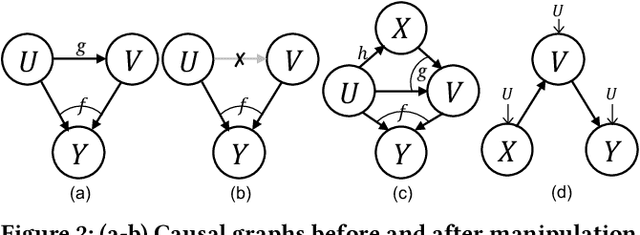
Recommender systems are important and valuable tools for many personalized services. Collaborative Filtering (CF) algorithms -- among others -- are fundamental algorithms driving the underlying mechanism of personalized recommendation. Many of the traditional CF algorithms are designed based on the fundamental idea of mining or learning correlative patterns from data for matching, including memory-based methods such as user/item-based CF as well as learning-based methods such as matrix factorization and deep learning models. However, advancing from correlative learning to causal learning is an important problem, because causal/counterfactual modeling can help us to think outside of the observational data for user modeling and personalization. In this paper, we propose Causal Collaborative Filtering (CCF) -- a general framework for modeling causality in collaborative filtering and recommendation. We first provide a unified causal view of CF and mathematically show that many of the traditional CF algorithms are actually special cases of CCF under simplified causal graphs. We then propose a conditional intervention approach for $do$-calculus so that we can estimate the causal relations based on observational data. Finally, we further propose a general counterfactual constrained learning framework for estimating the user-item preferences. Experiments are conducted on two types of real-world datasets -- traditional and randomized trial data -- and results show that our framework can improve the recommendation performance of many CF algorithms.
Discrete Knowledge Graph Embedding based on Discrete Optimization
Jan 13, 2021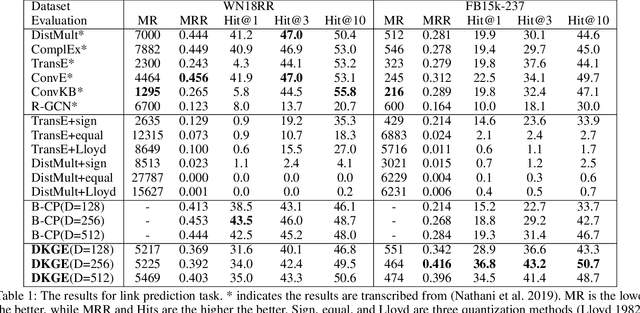
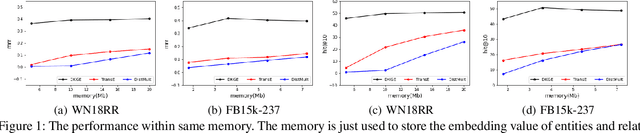
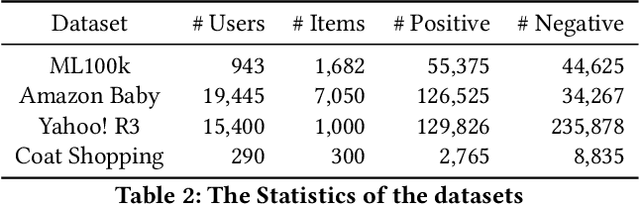
This paper proposes a discrete knowledge graph (KG) embedding (DKGE) method, which projects KG entities and relations into the Hamming space based on a computationally tractable discrete optimization algorithm, to solve the formidable storage and computation cost challenges in traditional continuous graph embedding methods. The convergence of DKGE can be guaranteed theoretically. Extensive experiments demonstrate that DKGE achieves superior accuracy than classical hashing functions that map the effective continuous embeddings into discrete codes. Besides, DKGE reaches comparable accuracy with much lower computational complexity and storage compared to many continuous graph embedding methods.
Towards Long-term Fairness in Recommendation
Jan 10, 2021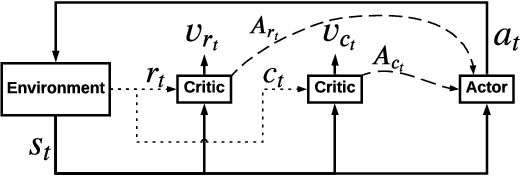
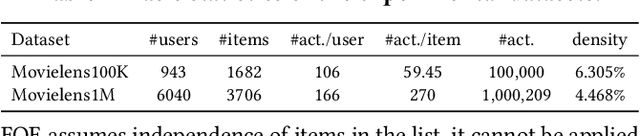
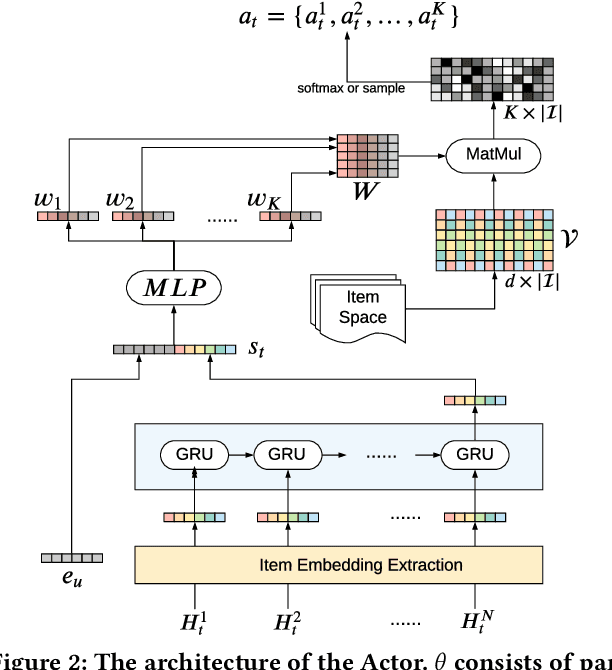
As Recommender Systems (RS) influence more and more people in their daily life, the issue of fairness in recommendation is becoming more and more important. Most of the prior approaches to fairness-aware recommendation have been situated in a static or one-shot setting, where the protected groups of items are fixed, and the model provides a one-time fairness solution based on fairness-constrained optimization. This fails to consider the dynamic nature of the recommender systems, where attributes such as item popularity may change over time due to the recommendation policy and user engagement. For example, products that were once popular may become no longer popular, and vice versa. As a result, the system that aims to maintain long-term fairness on the item exposure in different popularity groups must accommodate this change in a timely fashion. Novel to this work, we explore the problem of long-term fairness in recommendation and accomplish the problem through dynamic fairness learning. We focus on the fairness of exposure of items in different groups, while the division of the groups is based on item popularity, which dynamically changes over time in the recommendation process. We tackle this problem by proposing a fairness-constrained reinforcement learning algorithm for recommendation, which models the recommendation problem as a Constrained Markov Decision Process (CMDP), so that the model can dynamically adjust its recommendation policy to make sure the fairness requirement is always satisfied when the environment changes. Experiments on several real-world datasets verify our framework's superiority in terms of recommendation performance, short-term fairness, and long-term fairness.
Learning Post-Hoc Causal Explanations for Recommendation
Jun 30, 2020
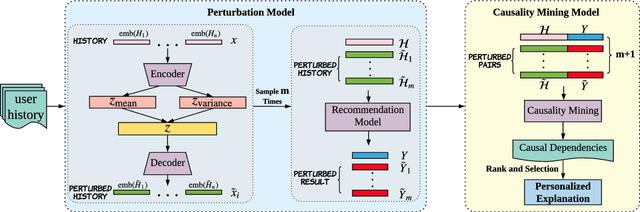
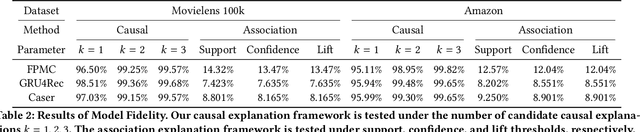
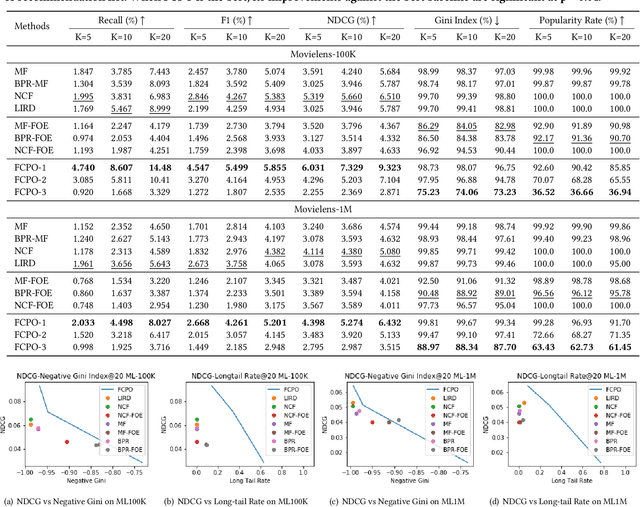
State-of-the-art recommender systems have the ability to generate high-quality recommendations, but usually cannot provide intuitive explanations to humans due to the usage of black-box prediction models. The lack of transparency has highlighted the critical importance of improving the explainability of recommender systems. In this paper, we propose to extract causal rules from the user interaction history as post-hoc explanations for the black-box sequential recommendation mechanisms, whilst maintain the predictive accuracy of the recommendation model. Our approach firstly achieves counterfactual examples with the aid of a perturbation model, and then extracts personalized causal relationships for the recommendation model through a causal rule mining algorithm. Experiments are conducted on several state-of-the-art sequential recommendation models and real-world datasets to verify the performance of our model on generating causal explanations. Meanwhile, We evaluate the discovered causal explanations in terms of quality and fidelity, which show that compared with conventional association rules, causal rules can provide personalized and more effective explanations for the behavior of black-box recommendation models.
Neural Collaborative Reasoning
Jun 11, 2020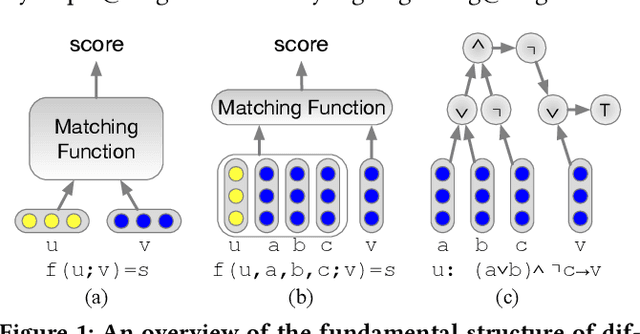
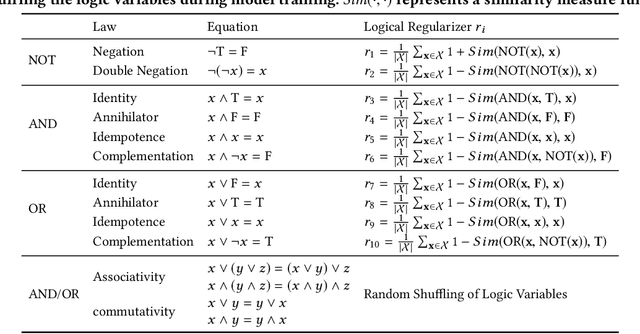
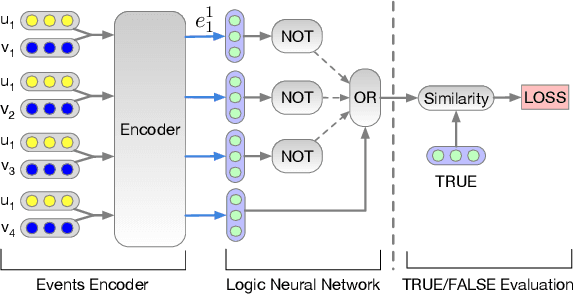
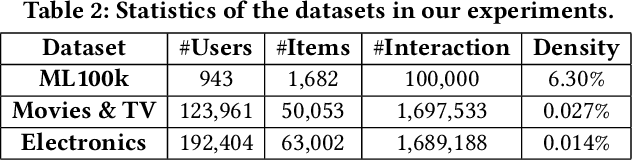
Collaborative Filtering (CF) has been an important approach to recommender systems. However, existing CF methods are mostly designed based on the idea of matching, i.e., by learning user and item embeddings from data using shallow or deep models, they try to capture the relevance patterns in data, so that a user embedding can be matched with appropriate item embeddings using designed or learned similarity functions. We argue that as a cognition rather than a perception intelligent task, recommendation requires not only the ability of pattern recognition and matching from data, but also the ability of logical reasoning in the data. Inspired by recent progress on neural-symbolic machine learning, we propose a neural collaborative reasoning framework to integrate the power of embedding learning and logical reasoning, where the embeddings capture similarity patterns in data from perceptual perspectives, and the logic facilitates cognitive reasoning for informed decision making. An important challenge, however, is to bridge differentiable neural networks and symbolic reasoning in a shared architecture for optimization and inference. To solve the problem, we propose a Modularized Logical Neural Network architecture, which learns basic logical operations such as AND, OR, and NOT as neural modules based on logical regularizer, and learns logic variables as vector embeddings. In this way, each logic expression can be equivalently organized as a neural network, so that logical reasoning and prediction can be conducted in a continuous space. Experiments on several real-world datasets verified the advantages of our framework compared with both traditional shallow and deep models.