 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysFormer: Facial Video-based Physiological Measurement with Temporal Difference Transformer
Nov 23, 2021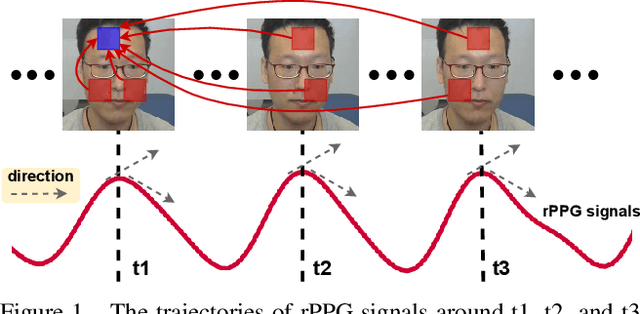
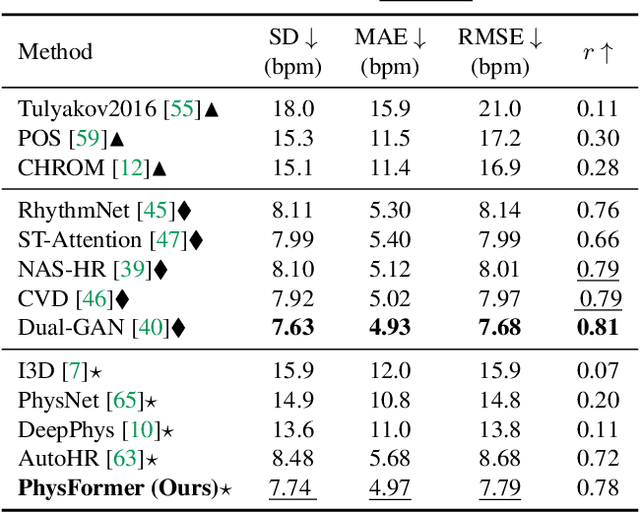
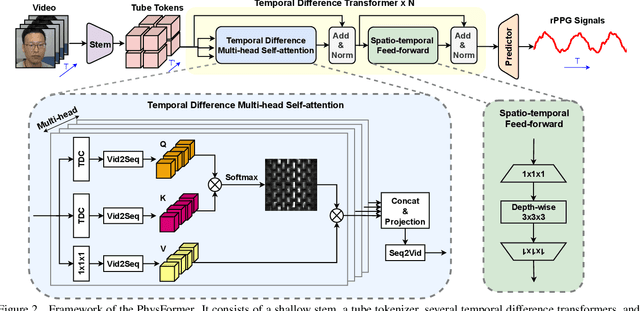
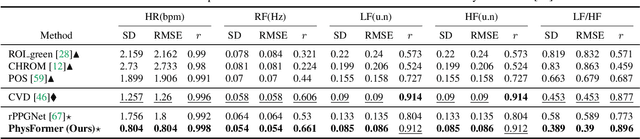
Remote photoplethysmography (rPPG), which aims at measuring heart activities and physiological signals from facial video without any contact, has great potential in many applications (e.g., remote healthcare and affective computing). Recent deep learning approaches focus on mining subtle rPPG clues using convolutional neural networks with limited spatio-temporal receptive fields, which neglect the long-range spatio-temporal perception and interaction for rPPG modeling. In this paper, we propose the PhysFormer, an end-to-end video transformer based architecture, to adaptively aggregate both local and global spatio-temporal features for rPPG representation enhancement. As key modules in PhysFormer, the temporal difference transformers first enhance the quasi-periodic rPPG features with temporal difference guided global attention, and then refine the local spatio-temporal representation against interference. Furthermore, we also propose the label distribution learning and a curriculum learning inspired dynamic constraint in frequency domain, which provide elaborate supervisions for PhysFormer and alleviate overfitting. Comprehensive experiments are performed on four benchmark datasets to show our superior performance on both intra- and cross-dataset testings. One highlight is that, unlike most transformer networks needed pretraining from large-scale datasets, the proposed PhysFormer can be easily trained from scratch on rPPG datasets, which makes it promising as a novel transformer baseline for the rPPG community. The codes will be released at https://github.com/ZitongYu/PhysFormer.
Learning Syntactic Dense Embedding with Correlation Graph for Automatic Readability Assessment
Jul 09, 2021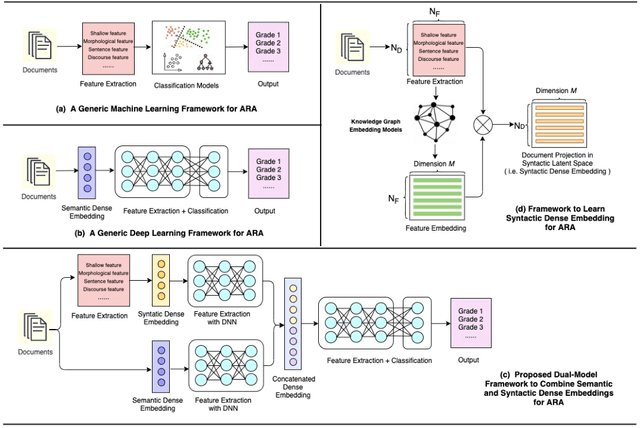



Deep learning models for automatic readability assessment generally discard linguistic features traditionally used in machine learning models for the task. We propose to incorporate linguistic features into neural network models by learning syntactic dense embeddings based on linguistic features. To cope with the relationships between the features, we form a correlation graph among features and use it to learn their embeddings so that similar features will be represented by similar embeddings. Experiments with six data sets of two proficiency levels demonstrate that our proposed methodology can complement BERT-only model to achieve significantly better performances for automatic readability assessment.
You Never Cluster Alone
Jun 03, 2021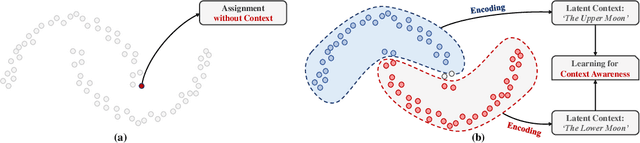
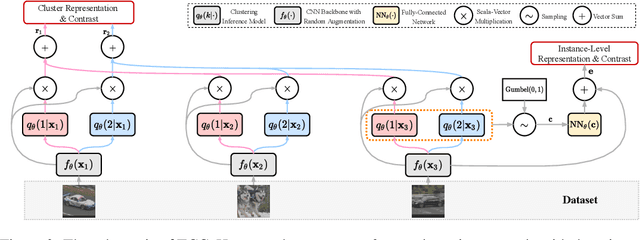
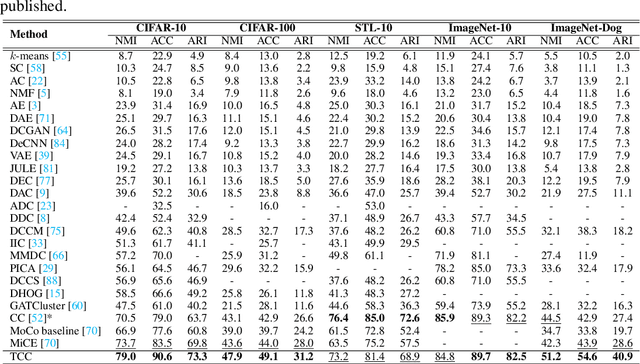
Recent advances in self-supervised learning with instance-level contrastive objectives facilitate unsupervised clustering. However, a standalone datum is not perceiving the context of the holistic cluster, and may undergo sub-optimal assignment. In this paper, we extend the mainstream contrastive learning paradigm to a cluster-level scheme, where all the data subjected to the same cluster contribute to a unified representation that encodes the context of each data group. Contrastive learning with this representation then rewards the assignment of each datum. To implement this vision, we propose twin-contrast clustering (TCC). We define a set of categorical variables as clustering assignment confidence, which links the instance-level learning track with the cluster-level one. On one hand, with the corresponding assignment variables being the weight, a weighted aggregation along the data points implements the set representation of a cluster. We further propose heuristic cluster augmentation equivalents to enable cluster-level contrastive learning. On the other hand, we derive the evidence lower-bound of the instance-level contrastive objective with the assignments. By reparametrizing the assignment variables, TCC is trained end-to-end, requiring no alternating steps. Extensive experiments show that TCC outperforms the state-of-the-art on challenging benchmarks.
Invertible Zero-Shot Recognition Flows
Jul 09, 2020
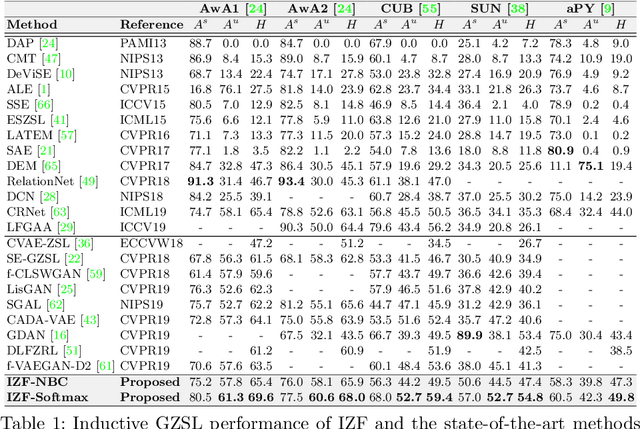
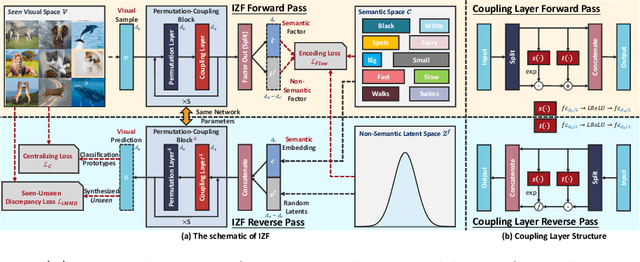
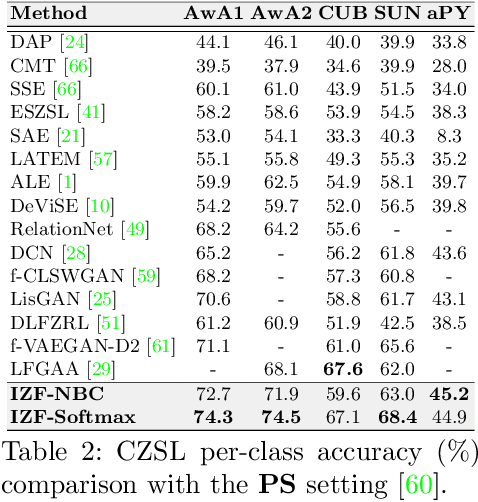
Deep generative models have been successfully applied to Zero-Shot Learning (ZSL) recently. However, the underlying drawbacks of GANs and VAEs (e.g., the hardness of training with ZSL-oriented regularizers and the limited generation quality) hinder the existing generative ZSL models from fully bypassing the seen-unseen bias. To tackle the above limitations, for the first time, this work incorporates a new family of generative models (i.e., flow-based models) into ZSL. The proposed Invertible Zero-shot Flow (IZF) learns factorized data embeddings (i.e., the semantic factors and the non-semantic ones) with the forward pass of an invertible flow network, while the reverse pass generates data samples. This procedure theoretically extends conventional generative flows to a factorized conditional scheme. To explicitly solve the bias problem, our model enlarges the seen-unseen distributional discrepancy based on negative sample-based distance measurement. Notably, IZF works flexibly with either a naive Bayesian classifier or a held-out trainable one for zero-shot recognition. Experiments on widely-adopted ZSL benchmarks demonstrate the significant performance gain of IZF over existing methods, in both classic and generalized settings.
Auto-Encoding Twin-Bottleneck Hashing
Mar 16, 2020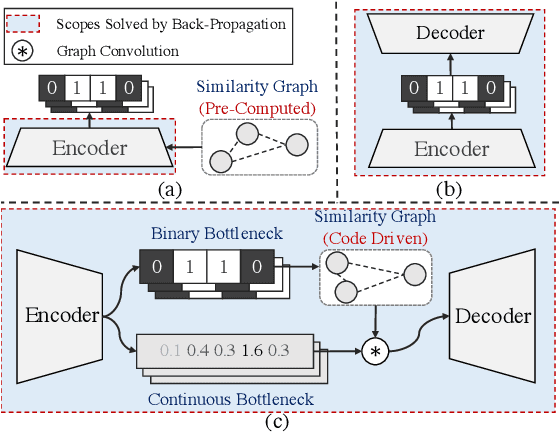
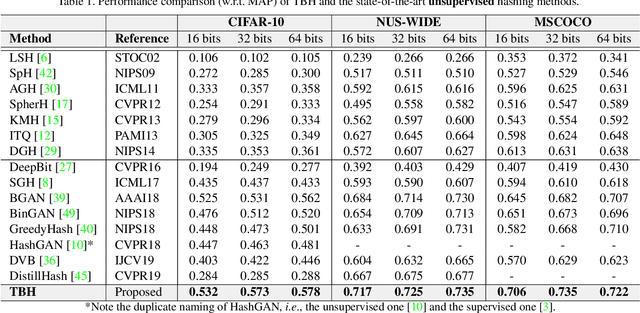
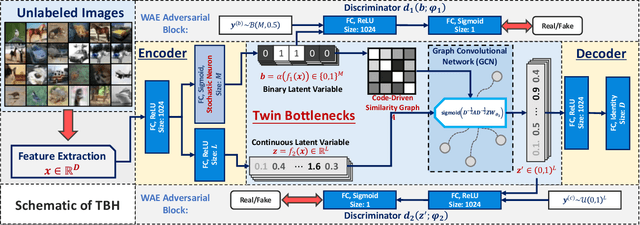
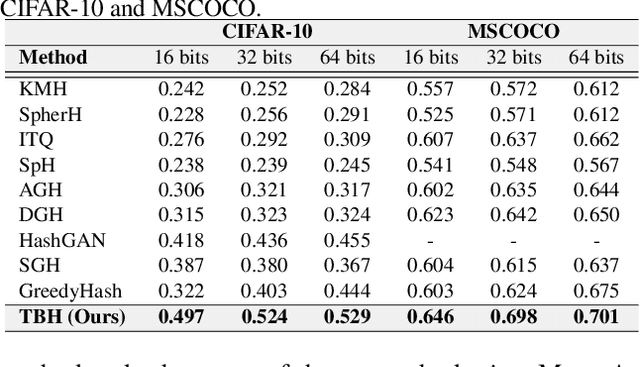
Conventional unsupervised hashing methods usually take advantage of similarity graphs, which are either pre-computed in the high-dimensional space or obtained from random anchor points. On the one hand, existing methods uncouple the procedures of hash function learning and graph construction. On the other hand, graphs empirically built upon original data could introduce biased prior knowledge of data relevance, leading to sub-optimal retrieval performance. In this paper, we tackle the above problems by proposing an efficient and adaptive code-driven graph, which is updated by decoding in the context of an auto-encoder. Specifically, we introduce into our framework twin bottlenecks (i.e., latent variables) that exchange crucial information collaboratively. One bottleneck (i.e., binary codes) conveys the high-level intrinsic data structure captured by the code-driven graph to the other (i.e., continuous variables for low-level detail information), which in turn propagates the updated network feedback for the encoder to learn more discriminative binary codes. The auto-encoding learning objective literally rewards the code-driven graph to learn an optimal encoder. Moreover, the proposed model can be simply optimized by gradient descent without violating the binary constraints. Experiments on benchmarked datasets clearly show the superiority of our framework over the state-of-the-art hashing methods. Our source code can be found at https://github.com/ymcidence/TBH.
Embarrassingly Simple Binary Representation Learning
Aug 26, 2019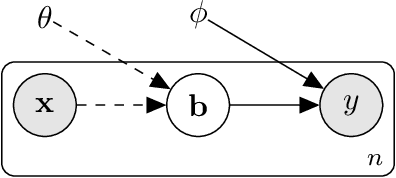

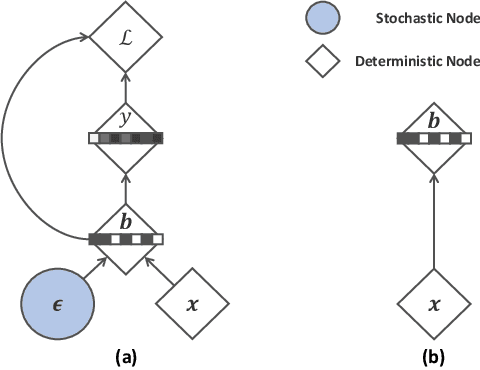
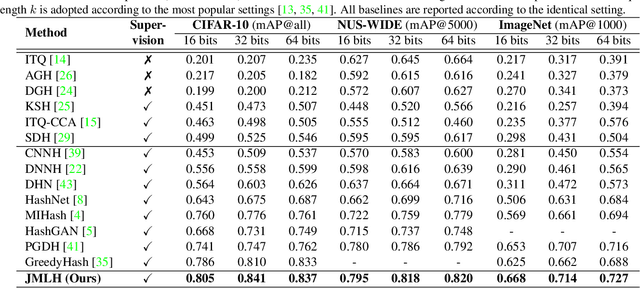
Recent binary representation learning models usually require sophisticated binary optimization, similarity measure or even generative models as auxiliaries. However, one may wonder whether these non-trivial components are needed to formulate practical and effective hashing models. In this paper, we answer the above question by proposing an embarrassingly simple approach to binary representation learning. With a simple classification objective, our model only incorporates two additional fully-connected layers onto the top of an arbitrary backbone network, whilst complying with the binary constraints during training. The proposed model lower-bounds the Information Bottleneck (IB) between data samples and their semantics, and can be related to many recent `learning to hash' paradigms. We show that, when properly designed, even such a simple network can generate effective binary codes, by fully exploring data semantics without any held-out alternating updating steps or auxiliary models. Experiments are conducted on conventional large-scale benchmarks, i.e., CIFAR-10, NUS-WIDE, and ImageNet, where the proposed simple model outperforms the state-of-the-art methods.
Zero-Shot Sketch-Image Hashing
Mar 06, 2018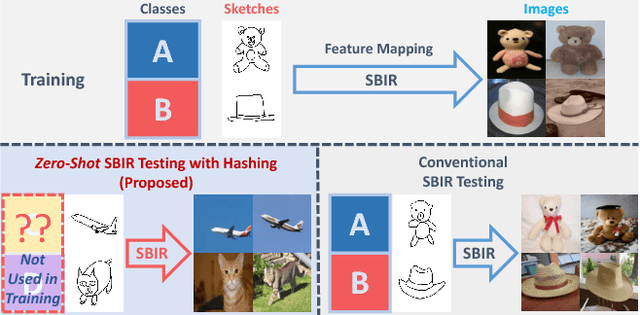
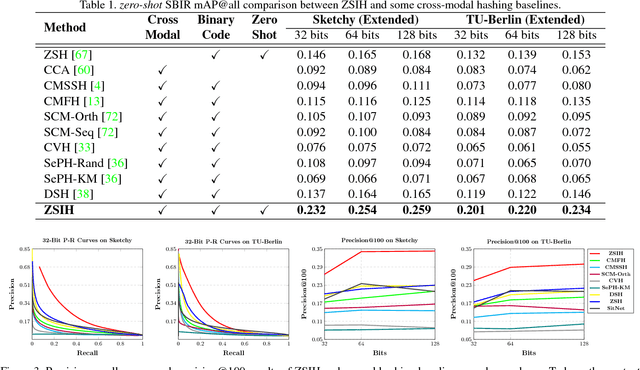
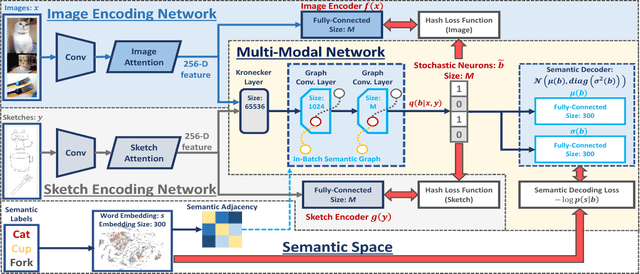
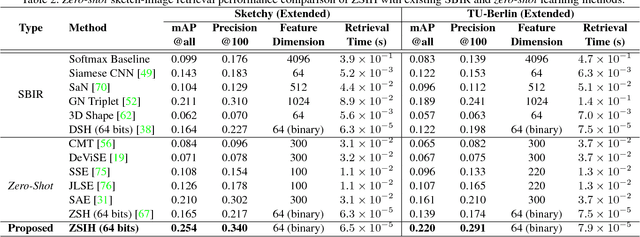
Recent studies show that large-scale sketch-based image retrieval (SBIR) can be efficiently tackled by cross-modal binary representation learning methods, where Hamming distance matching significantly speeds up the process of similarity search. Providing training and test data subjected to a fixed set of pre-defined categories, the cutting-edge SBIR and cross-modal hashing works obtain acceptable retrieval performance. However, most of the existing methods fail when the categories of query sketches have never been seen during training. In this paper, the above problem is briefed as a novel but realistic zero-shot SBIR hashing task. We elaborate the challenges of this special task and accordingly propose a zero-shot sketch-image hashing (ZSIH) model. An end-to-end three-network architecture is built, two of which are treated as the binary encoders. The third network mitigates the sketch-image heterogeneity and enhances the semantic relations among data by utilizing the Kronecker fusion layer and graph convolution, respectively. As an important part of ZSIH, we formulate a generative hashing scheme in reconstructing semantic knowledge representations for zero-shot retrieval. To the best of our knowledge, ZSIH is the first zero-shot hashing work suitable for SBIR and cross-modal search. Comprehensive experiments are conducted on two extended datasets, i.e., Sketchy and TU-Berlin with a novel zero-shot train-test split. The proposed model remarkably outperforms related works.
Deep Binaries: Encoding Semantic-Rich Cues for Efficient Textual-Visual Cross Retrieval
Aug 08, 2017



Cross-modal hashing is usually regarded as an effective technique for large-scale textual-visual cross retrieval, where data from different modalities are mapped into a shared Hamming space for matching. Most of the traditional textual-visual binary encoding methods only consider holistic image representations and fail to model descriptive sentences. This renders existing methods inappropriate to handle the rich semantics of informative cross-modal data for quality textual-visual search tasks. To address the problem of hashing cross-modal data with semantic-rich cues, in this paper, a novel integrated deep architecture is developed to effectively encode the detailed semantics of informative images and long descriptive sentences, named as Textual-Visual Deep Binaries (TVDB). In particular, region-based convolutional networks with long short-term memory units are introduced to fully explore image regional details while semantic cues of sentences are modeled by a text convolutional network. Additionally, we propose a stochastic batch-wise training routine, where high-quality binary codes and deep encoding functions are efficiently optimized in an alternating manner. Experiments are conducted on three multimedia datasets, i.e. Microsoft COCO, IAPR TC-12, and INRIA Web Queries, where the proposed TVDB model significantly outperforms state-of-the-art binary coding methods in the task of cross-modal retrieval.
Deep Sketch Hashing: Fast Free-hand Sketch-Based Image Retrieval
Mar 16, 2017
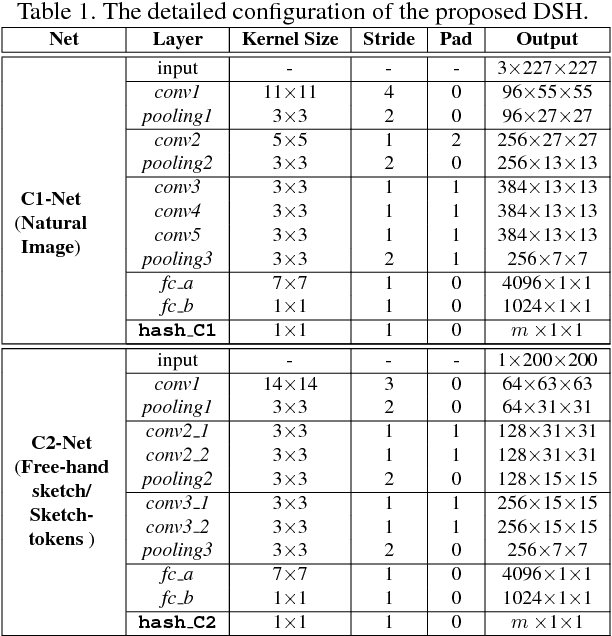

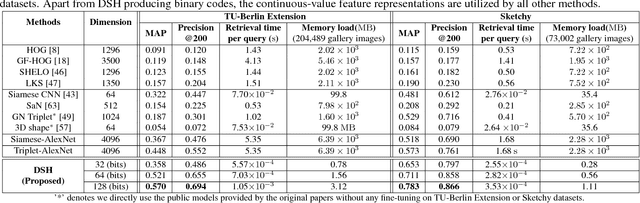
Free-hand sketch-based image retrieval (SBIR) is a specific cross-view retrieval task, in which queries are abstract and ambiguous sketches while the retrieval database is formed with natural images. Work in this area mainly focuses on extracting representative and shared features for sketches and natural images. However, these can neither cope well with the geometric distortion between sketches and images nor be feasible for large-scale SBIR due to the heavy continuous-valued distance computation. In this paper, we speed up SBIR by introducing a novel binary coding method, named \textbf{Deep Sketch Hashing} (DSH), where a semi-heterogeneous deep architecture is proposed and incorporated into an end-to-end binary coding framework. Specifically, three convolutional neural networks are utilized to encode free-hand sketches, natural images and, especially, the auxiliary sketch-tokens which are adopted as bridges to mitigate the sketch-image geometric distortion. The learned DSH codes can effectively capture the cross-view similarities as well as the intrinsic semantic correlations between different categories. To the best of our knowledge, DSH is the first hashing work specifically designed for category-level SBIR with an end-to-end deep architecture. The proposed DSH is comprehensively evaluated on two large-scale datasets of TU-Berlin Extension and Sketchy, and the experiments consistently show DSH's superior SBIR accuracies over several state-of-the-art methods, while achieving significantly reduced retrieval time and memory footprint.