 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Quality Assessment of 360$^\circ$ Images Based on Generative Scanpath Representation
Sep 07, 2023



Despite substantial efforts dedicated to the design of heuristic models for omnidirectional (i.e., 360$^\circ$) image quality assessment (OIQA), a conspicuous gap remains due to the lack of consideration for the diversity of viewing behaviors that leads to the varying perceptual quality of 360$^\circ$ images. Two critical aspects underline this oversight: the neglect of viewing conditions that significantly sway user gaze patterns and the overreliance on a single viewport sequence from the 360$^\circ$ image for quality inference. To address these issues, we introduce a unique generative scanpath representation (GSR) for effective quality inference of 360$^\circ$ images, which aggregates varied perceptual experiences of multi-hypothesis users under a predefined viewing condition. More specifically, given a viewing condition characterized by the starting point of viewing and exploration time, a set of scanpaths consisting of dynamic visual fixations can be produced using an apt scanpath generator. Following this vein, we use the scanpaths to convert the 360$^\circ$ image into the unique GSR, which provides a global overview of gazed-focused contents derived from scanpaths. As such, the quality inference of the 360$^\circ$ image is swiftly transformed to that of GSR. We then propose an efficient OIQA computational framework by learning the quality maps of GSR. Comprehensive experimental results validate that the predictions of the proposed framework are highly consistent with human perception in the spatiotemporal domain, especially in the challenging context of locally distorted 360$^\circ$ images under varied viewing conditions. The code will be released at https://github.com/xiangjieSui/GSR
Integrating Large Pre-trained Models into Multimodal Named Entity Recognition with Evidential Fusion
Jun 29, 2023Multimodal Named Entity Recognition (MNER) is a crucial task for information extraction from social media platforms such as Twitter. Most current methods rely on attention weights to extract information from both text and images but are often unreliable and lack interpretability. To address this problem, we propose incorporating uncertainty estimation into the MNER task, producing trustworthy predictions. Our proposed algorithm models the distribution of each modality as a Normal-inverse Gamma distribution, and fuses them into a unified distribution with an evidential fusion mechanism, enabling hierarchical characterization of uncertainties and promotion of prediction accuracy and trustworthiness. Additionally, we explore the potential of pre-trained large foundation models in MNER and propose an efficient fusion approach that leverages their robust feature representations. Experiments on two datasets demonstrate that our proposed method outperforms the baselines and achieves new state-of-the-art performance.
Harmonizing Base and Novel Classes: A Class-Contrastive Approach for Generalized Few-Shot Segmentation
Mar 24, 2023



Current methods for few-shot segmentation (FSSeg) have mainly focused on improving the performance of novel classes while neglecting the performance of base classes. To overcome this limitation, the task of generalized few-shot semantic segmentation (GFSSeg) has been introduced, aiming to predict segmentation masks for both base and novel classes. However, the current prototype-based methods do not explicitly consider the relationship between base and novel classes when updating prototypes, leading to a limited performance in identifying true categories. To address this challenge, we propose a class contrastive loss and a class relationship loss to regulate prototype updates and encourage a large distance between prototypes from different classes, thus distinguishing the classes from each other while maintaining the performance of the base classes. Our proposed approach achieves new state-of-the-art performance for the generalized few-shot segmentation task on PASCAL VOC and MS COCO datasets.
CFNet: Conditional Filter Learning with Dynamic Noise Estimation for Real Image Denoising
Nov 26, 2022



A mainstream type of the state of the arts (SOTAs) based on convolutional neural network (CNN) for real image denoising contains two sub-problems, i.e., noise estimation and non-blind denoising. This paper considers real noise approximated by heteroscedastic Gaussian/Poisson Gaussian distributions with in-camera signal processing pipelines. The related works always exploit the estimated noise prior via channel-wise concatenation followed by a convolutional layer with spatially sharing kernels. Due to the variable modes of noise strength and frequency details of all feature positions, this design cannot adaptively tune the corresponding denoising patterns. To address this problem, we propose a novel conditional filter in which the optimal kernels for different feature positions can be adaptively inferred by local features from the image and the noise map. Also, we bring the thought that alternatively performs noise estimation and non-blind denoising into CNN structure, which continuously updates noise prior to guide the iterative feature denoising. In addition, according to the property of heteroscedastic Gaussian distribution, a novel affine transform block is designed to predict the stationary noise component and the signal-dependent noise component. Compared with SOTAs, extensive experiments are conducted on five synthetic datasets and three real datasets, which shows the improvement of the proposed CFNet.
GMF: General Multimodal Fusion Framework for Correspondence Outlier Rejection
Nov 01, 2022



Rejecting correspondence outliers enables to boost the correspondence quality, which is a critical step in achieving high point cloud registration accuracy. The current state-of-the-art correspondence outlier rejection methods only utilize the structure features of the correspondences. However, texture information is critical to reject the correspondence outliers in our human vision system. In this paper, we propose General Multimodal Fusion (GMF) to learn to reject the correspondence outliers by leveraging both the structure and texture information. Specifically, two cross-attention-based fusion layers are proposed to fuse the texture information from paired images and structure information from point correspondences. Moreover, we propose a convolutional position encoding layer to enhance the difference between Tokens and enable the encoding feature pay attention to neighbor information. Our position encoding layer will make the cross-attention operation integrate both local and global information. Experiments on multiple datasets(3DMatch, 3DLoMatch, KITTI) and recent state-of-the-art models (3DRegNet, DGR, PointDSC) prove that our GMF achieves wide generalization ability and consistently improves the point cloud registration accuracy. Furthermore, several ablation studies demonstrate the robustness of the proposed GMF on different loss functions, lighting conditions and noises.The code is available at https://github.com/XiaoshuiHuang/GMF.
A Novel Long-term Iterative Mining Scheme for Video Salient Object Detection
Jun 20, 2022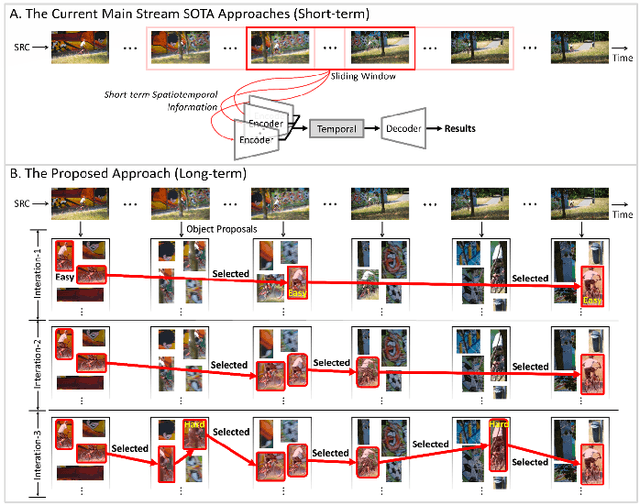
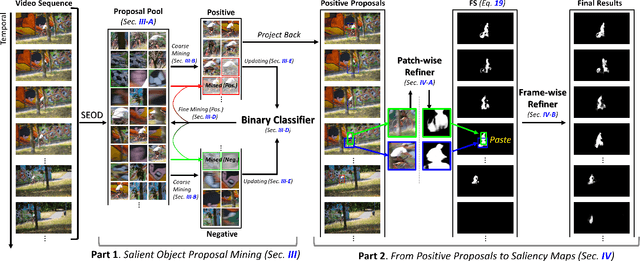

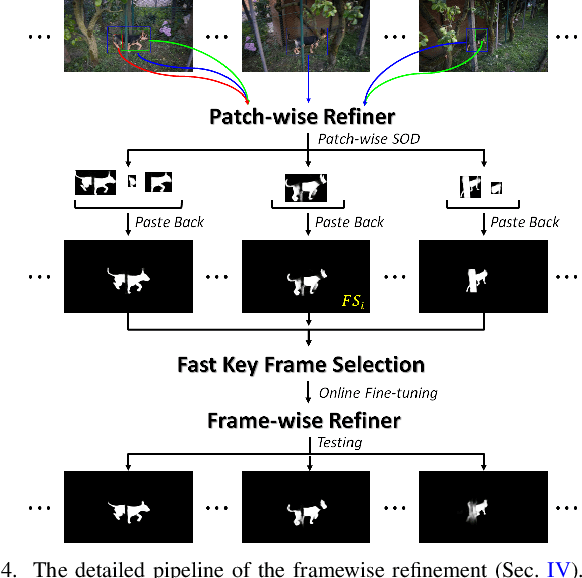
The existing state-of-the-art (SOTA) video salient object detection (VSOD) models have widely followed short-term methodology, which dynamically determines the balance between spatial and temporal saliency fusion by solely considering the current consecutive limited frames. However, the short-term methodology has one critical limitation, which conflicts with the real mechanism of our visual system -- a typical long-term methodology. As a result, failure cases keep showing up in the results of the current SOTA models, and the short-term methodology becomes the major technical bottleneck. To solve this problem, this paper proposes a novel VSOD approach, which performs VSOD in a complete long-term way. Our approach converts the sequential VSOD, a sequential task, to a data mining problem, i.e., decomposing the input video sequence to object proposals in advance and then mining salient object proposals as much as possible in an easy-to-hard way. Since all object proposals are simultaneously available, the proposed approach is a complete long-term approach, which can alleviate some difficulties rooted in conventional short-term approaches. In addition, we devised an online updating scheme that can grasp the most representative and trustworthy pattern profile of the salient objects, outputting framewise saliency maps with rich details and smoothing both spatially and temporally. The proposed approach outperforms almost all SOTA models on five widely used benchmark datasets.
Perceptual Optimization of a Biologically-Inspired Tone Mapping Operator
Jun 18, 2022

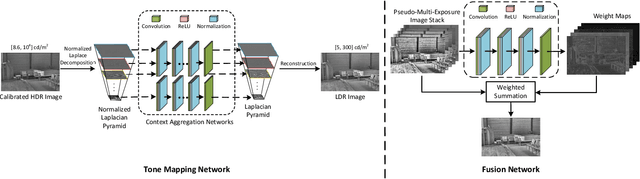
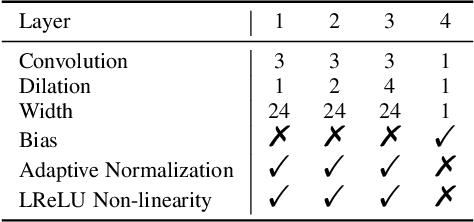
With the increasing popularity and accessibility of high dynamic range (HDR) photography, tone mapping operators (TMOs) for dynamic range compression and medium presentation are practically demanding. In this paper, we develop a two-stage neural network-based HDR image TMO that is biologically-inspired, computationally efficient, and perceptually optimized. In Stage one, motivated by the physiology of the early stages of the human visual system (HVS), we first decompose an HDR image into a normalized Laplacian pyramid. We then use two lightweight deep neural networks (DNNs) that take this normalized representation as input and estimate the Laplacian pyramid of the corresponding LDR image. We optimize the tone mapping network by minimizing the normalized Laplacian pyramid distance (NLPD), a perceptual metric calibrated against human judgments of tone-mapped image quality. In Stage two, we generate a pseudo-multi-exposure image stack with different color saturation and detail visibility by inputting an HDR image ``calibrated'' with different maximum luminances to the learned tone mapping network. We then train another lightweight DNN to fuse the LDR image stack into a desired LDR image by maximizing a variant of MEF-SSIM, another perceptually calibrated metric for image fusion. By doing so, the proposed TMO is fully automatic to tone map uncalibrated HDR images. Across an independent set of HDR images, we find that our method produces images with consistently better visual quality, and is among the fastest local TMOs.
A Database for Perceived Quality Assessment of User-Generated VR Videos
Jun 13, 2022

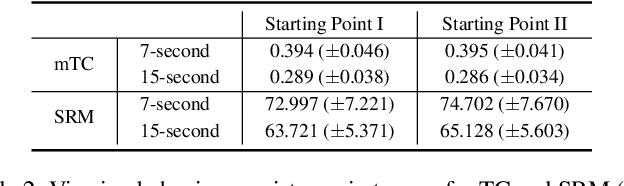
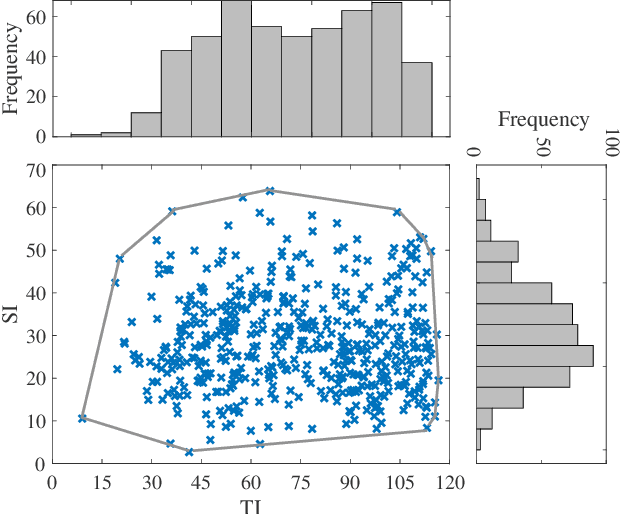
Virtual reality (VR) videos (typically in the form of 360$^\circ$ videos) have gained increasing attention due to the fast development of VR technologies and the remarkable popularization of consumer-grade 360$^\circ$ cameras and displays. Thus it is pivotal to understand how people perceive user-generated VR videos, which may suffer from commingled authentic distortions, often localized in space and time. In this paper, we establish one of the largest 360$^\circ$ video databases, containing 502 user-generated videos with rich content and distortion diversities. We capture viewing behaviors (i.e., scanpaths) of 139 users, and collect their opinion scores of perceived quality under four different viewing conditions (two starting points $\times$ two exploration times). We provide a thorough statistical analysis of recorded data, resulting in several interesting observations, such as the significant impact of viewing conditions on viewing behaviors and perceived quality. Besides, we explore other usage of our data and analysis, including evaluation of computational models for quality assessment and saliency detection of 360$^\circ$ videos. We have made the dataset and code available at https://github.com/Yao-Yiru/VR-Video-Database.
Distilling Knowledge from Object Classification to Aesthetics Assessment
Jun 02, 2022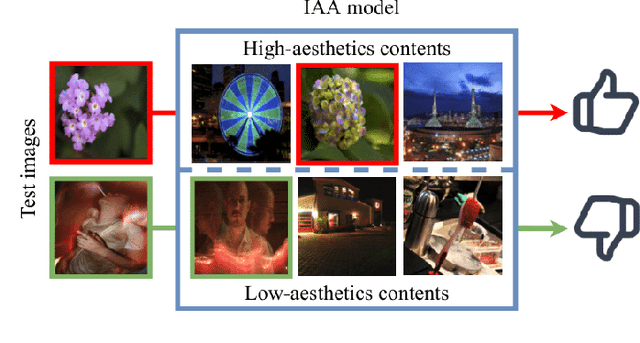
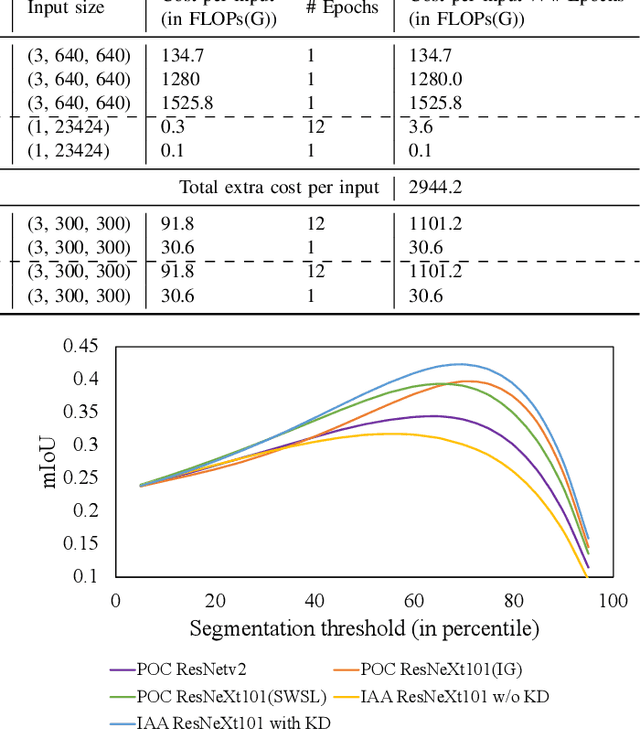

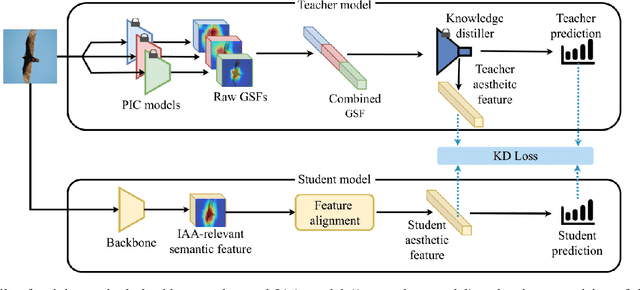
In this work, we point out that the major dilemma of image aesthetics assessment (IAA) comes from the abstract nature of aesthetic labels. That is, a vast variety of distinct contents can correspond to the same aesthetic label. On the one hand, during inference, the IAA model is required to relate various distinct contents to the same aesthetic label. On the other hand, when training, it would be hard for the IAA model to learn to distinguish different contents merely with the supervision from aesthetic labels, since aesthetic labels are not directly related to any specific content. To deal with this dilemma, we propose to distill knowledge on semantic patterns for a vast variety of image contents from multiple pre-trained object classification (POC) models to an IAA model. Expecting the combination of multiple POC models can provide sufficient knowledge on various image contents, the IAA model can easier learn to relate various distinct contents to a limited number of aesthetic labels. By supervising an end-to-end single-backbone IAA model with the distilled knowledge, the performance of the IAA model is significantly improved by 4.8% in SRCC compared to the version trained only with ground-truth aesthetic labels. On specific categories of images, the SRCC improvement brought by the proposed method can achieve up to 7.2%. Peer comparison also shows that our method outperforms 10 previous IAA methods.
Measuring Perceptual Color Differences of Smartphone Photography
May 26, 2022

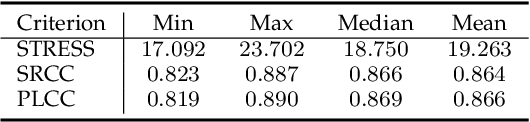

Measuring perceptual color differences (CDs) is of great importance in modern smartphone photography. Despite the long history, most CD measures have been constrained by psychophysical data of homogeneous color patches or a limited number of simplistic natural images. It is thus questionable whether existing CD measures generalize in the age of smartphone photography characterized by greater content complexities and learning-based image signal processors. In this paper, we put together so far the largest image dataset for perceptual CD assessment, in which the natural images are 1) captured by six flagship smartphones, 2) altered by Photoshop, 3) post-processed by built-in filters of the smartphones, and 4) reproduced with incorrect color profiles. We then conduct a large-scale psychophysical experiment to gather perceptual CDs of 30,000 image pairs in a carefully controlled laboratory environment. Based on the newly established dataset, we make one of the first attempts to construct an end-to-end learnable CD formula based on a lightweight neural network, as a generalization of several previous metrics. Extensive experiments demonstrate that the optimized formula outperforms 28 existing CD measures by a large margin, offers reasonable local CD maps without the use of dense supervision, generalizes well to color patch data, and empirically behaves as a proper metric in the mathematical sense.