 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock-Recurrent Transformers
Mar 11, 2022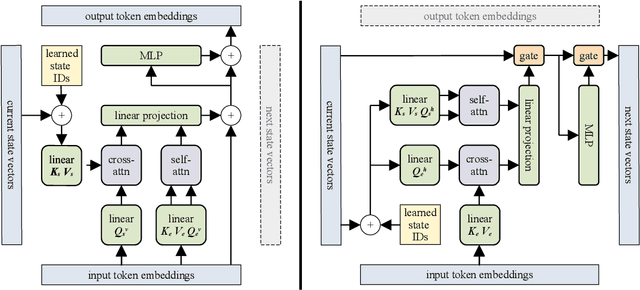
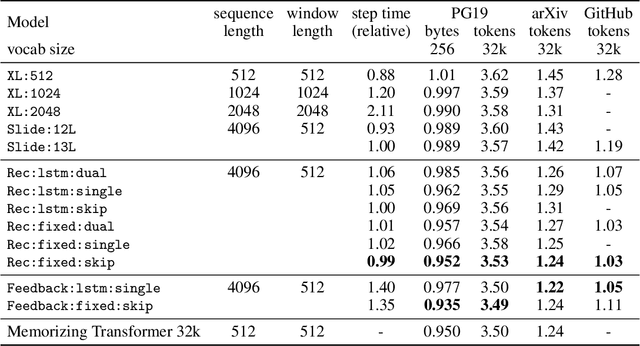
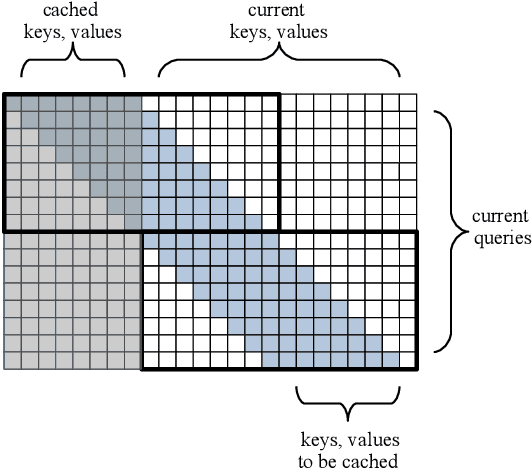
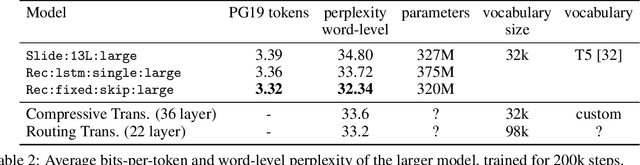
We introduce the Block-Recurrent Transformer, which applies a transformer layer in a recurrent fashion along a sequence, and has linear complexity with respect to sequence length. Our recurrent cell operates on blocks of tokens rather than single tokens, and leverages parallel computation within a block in order to make efficient use of accelerator hardware. The cell itself is strikingly simple. It is merely a transformer layer: it uses self-attention and cross-attention to efficiently compute a recurrent function over a large set of state vectors and tokens. Our design was inspired in part by LSTM cells, and it uses LSTM-style gates, but it scales the typical LSTM cell up by several orders of magnitude. Our implementation of recurrence has the same cost in both computation time and parameter count as a conventional transformer layer, but offers dramatically improved perplexity in language modeling tasks over very long sequences. Our model out-performs a long-range Transformer XL baseline by a wide margin, while running twice as fast. We demonstrate its effectiveness on PG19 (books), arXiv papers, and GitHub source code.
Hierarchical Transformers Are More Efficient Language Models
Oct 26, 2021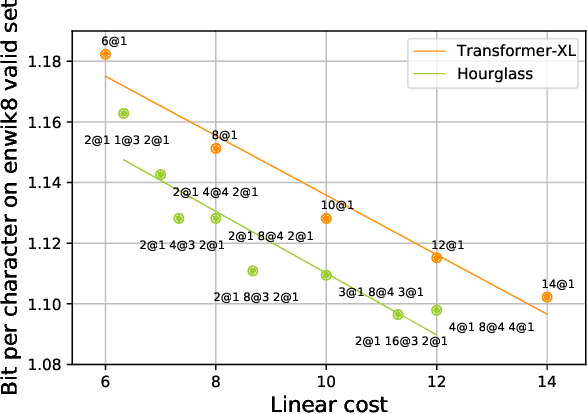

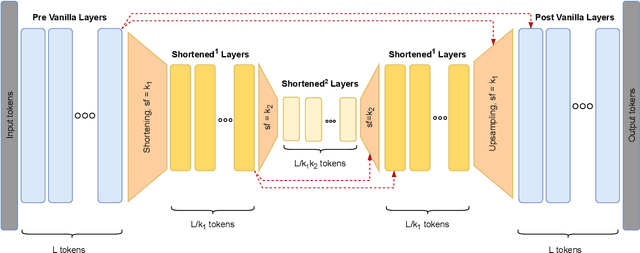
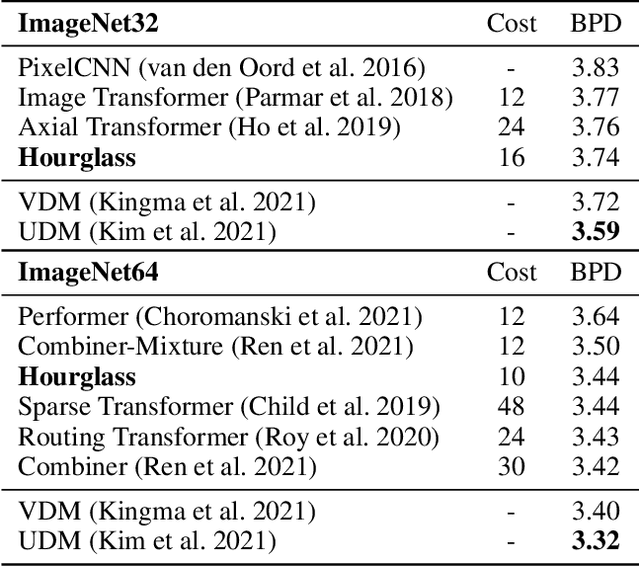
Transformer models yield impressive results on many NLP and sequence modeling tasks. Remarkably, Transformers can handle long sequences which allows them to produce long coherent outputs: full paragraphs produced by GPT-3 or well-structured images produced by DALL-E. These large language models are impressive but also very inefficient and costly, which limits their applications and accessibility. We postulate that having an explicit hierarchical architecture is the key to Transformers that efficiently handle long sequences. To verify this claim, we first study different ways to downsample and upsample activations in Transformers so as to make them hierarchical. We use the best performing upsampling and downsampling layers to create Hourglass - a hierarchical Transformer language model. Hourglass improves upon the Transformer baseline given the same amount of computation and can yield the same results as Transformers more efficiently. In particular, Hourglass sets new state-of-the-art for Transformer models on the ImageNet32 generation task and improves language modeling efficiency on the widely studied enwik8 benchmark.
Learning to Give Checkable Answers with Prover-Verifier Games
Aug 27, 2021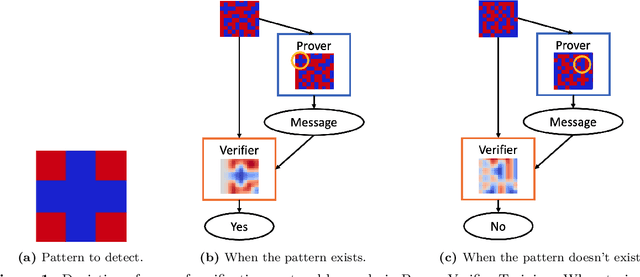
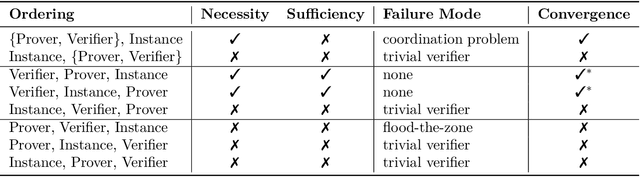

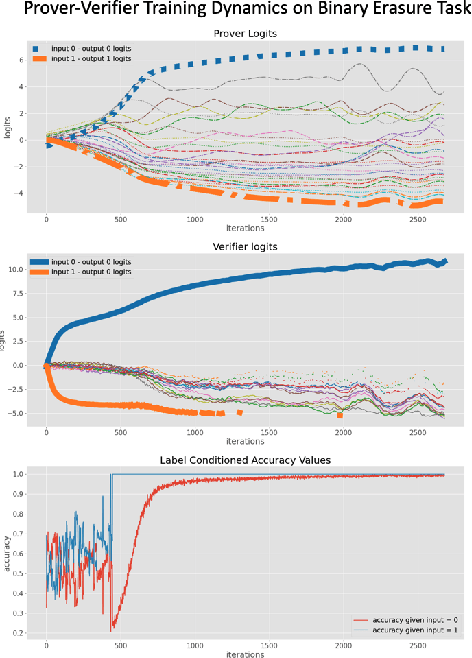
Our ability to know when to trust the decisions made by machine learning systems has not kept up with the staggering improvements in their performance, limiting their applicability in high-stakes domains. We introduce Prover-Verifier Games (PVGs), a game-theoretic framework to encourage learning agents to solve decision problems in a verifiable manner. The PVG consists of two learners with competing objectives: a trusted verifier network tries to choose the correct answer, and a more powerful but untrusted prover network attempts to persuade the verifier of a particular answer, regardless of its correctness. The goal is for a reliable justification protocol to emerge from this game. We analyze variants of the framework, including simultaneous and sequential games, and narrow the space down to a subset of games which provably have the desired equilibria. We develop instantiations of the PVG for two algorithmic tasks, and show that in practice, the verifier learns a robust decision rule that is able to receive useful and reliable information from an untrusted prover. Importantly, the protocol still works even when the verifier is frozen and the prover's messages are directly optimized to convince the verifier.
Subgoal Search For Complex Reasoning Tasks
Aug 25, 2021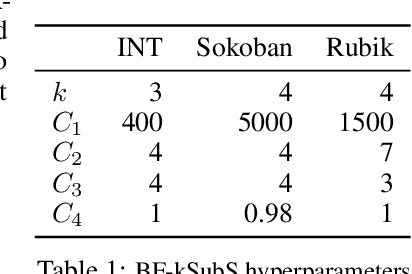
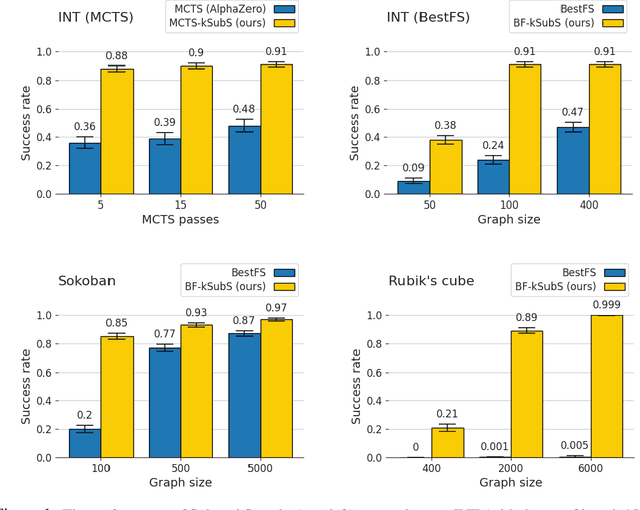
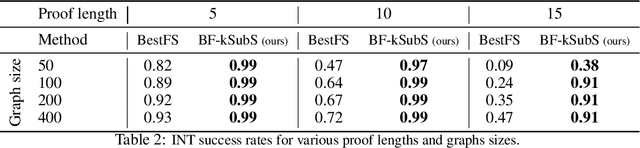
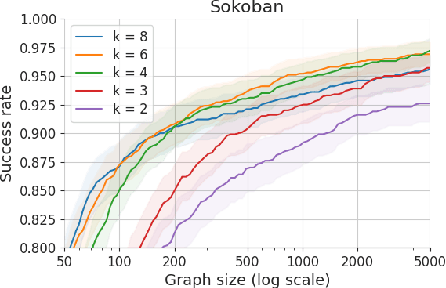
Humans excel in solving complex reasoning tasks through a mental process of moving from one idea to a related one. Inspired by this, we propose Subgoal Search (kSubS) method. Its key component is a learned subgoal generator that produces a diversity of subgoals that are both achievable and closer to the solution. Using subgoals reduces the search space and induces a high-level search graph suitable for efficient planning. In this paper, we implement kSubS using a transformer-based subgoal module coupled with the classical best-first search framework. We show that a simple approach of generating $k$-th step ahead subgoals is surprisingly efficient on three challenging domains: two popular puzzle games, Sokoban and the Rubik's Cube, and an inequality proving benchmark INT. kSubS achieves strong results including state-of-the-art on INT within a modest computational budget.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Nonlinear Invariant Risk Minimization: A Causal Approach
Feb 24, 2021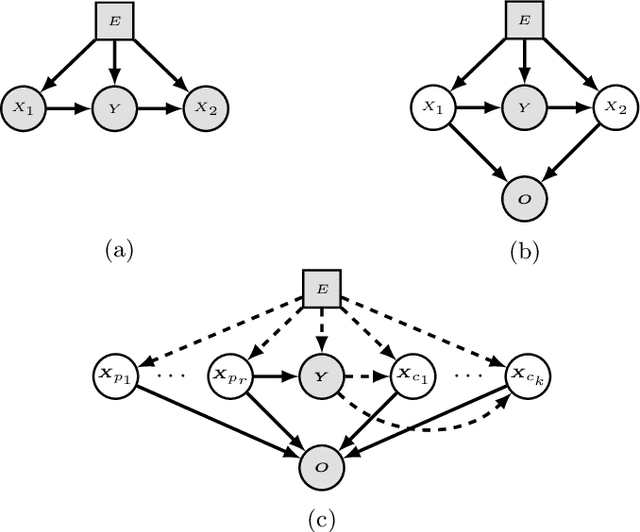
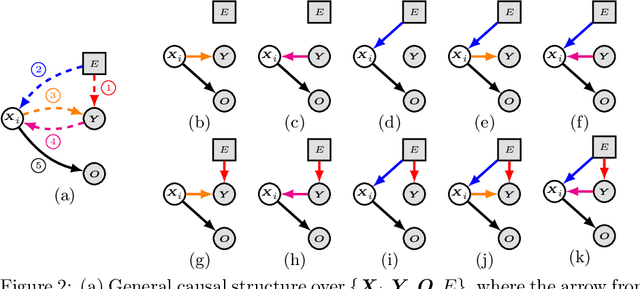
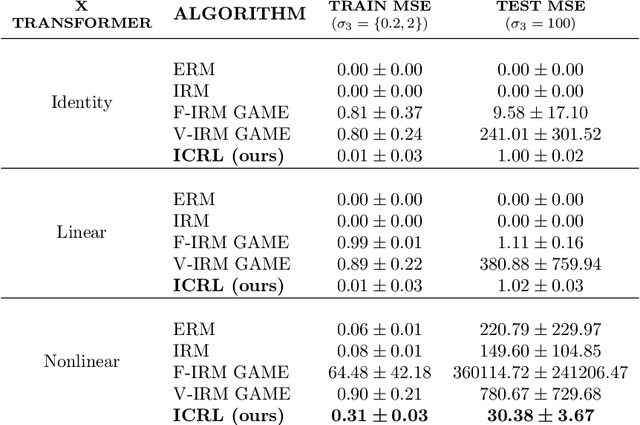
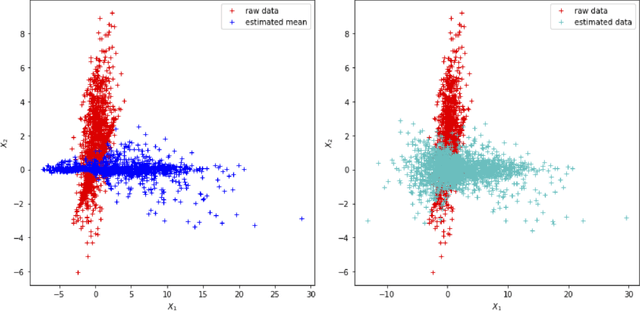
Due to spurious correlations, machine learning systems often fail to generalize to environments whose distributions differ from the ones used at training time. Prior work addressing this, either explicitly or implicitly, attempted to find a data representation that has an invariant causal relationship with the target. This is done by leveraging a diverse set of training environments to reduce the effect of spurious features and build an invariant predictor. However, these methods have generalization guarantees only when both data representation and classifiers come from a linear model class. We propose Invariant Causal Representation Learning (ICRL), a learning paradigm that enables out-of-distribution (OOD) generalization in the nonlinear setting (i.e., nonlinear representations and nonlinear classifiers). It builds upon a practical and general assumption: the prior over the data representation factorizes when conditioning on the target and the environment. Based on this, we show identifiability of the data representation up to very simple transformations. We also prove that all direct causes of the target can be fully discovered, which further enables us to obtain generalization guarantees in the nonlinear setting. Extensive experiments on both synthetic and real-world datasets show that our approach significantly outperforms a variety of baseline methods. Finally, in the concluding discussion, we further explore the aforementioned assumption and propose a general view, called the Agnostic Hypothesis: there exist a set of hidden causal factors affecting both inputs and outcomes. The Agnostic Hypothesis can provide a unifying view of machine learning in terms of representation learning. More importantly, it can inspire a new direction to explore the general theory for identifying hidden causal factors, which is key to enabling the OOD generalization guarantees in machine learning.
Proof Artifact Co-training for Theorem Proving with Language Models
Feb 11, 2021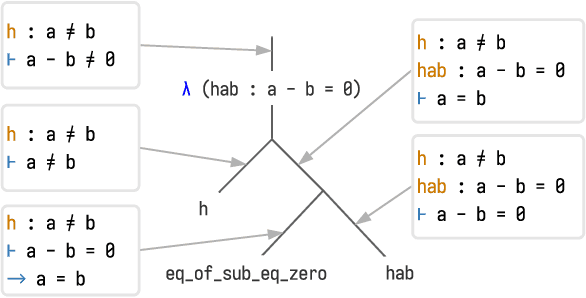

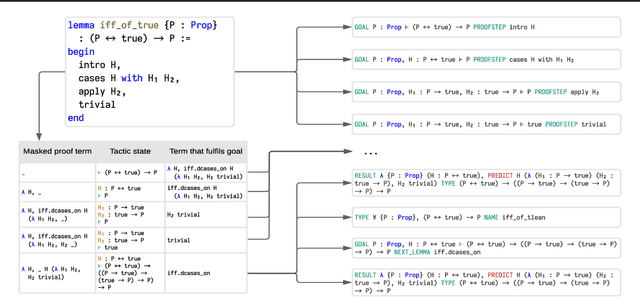
Labeled data for imitation learning of theorem proving in large libraries of formalized mathematics is scarce as such libraries require years of concentrated effort by human specialists to be built. This is particularly challenging when applying large Transformer language models to tactic prediction, because the scaling of performance with respect to model size is quickly disrupted in the data-scarce, easily-overfitted regime. We propose PACT ({\bf P}roof {\bf A}rtifact {\bf C}o-{\bf T}raining), a general methodology for extracting abundant self-supervised data from kernel-level proof terms for co-training alongside the usual tactic prediction objective. We apply this methodology to Lean, an interactive proof assistant which hosts some of the most sophisticated formalized mathematics to date. We instrument Lean with a neural theorem prover driven by a Transformer language model and show that PACT improves theorem proving success rate on a held-out suite of test theorems from 32\% to 48\%.
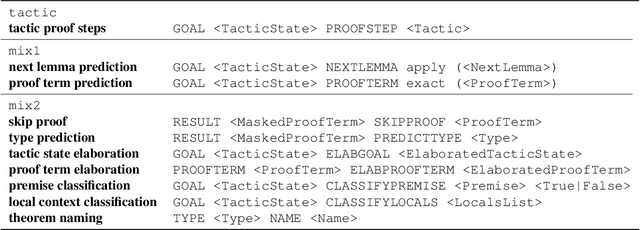
LIME: Learning Inductive Bias for Primitives of Mathematical Reasoning
Jan 15, 2021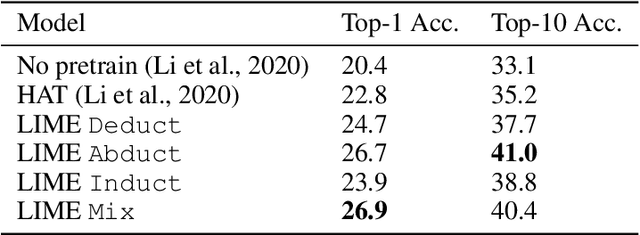
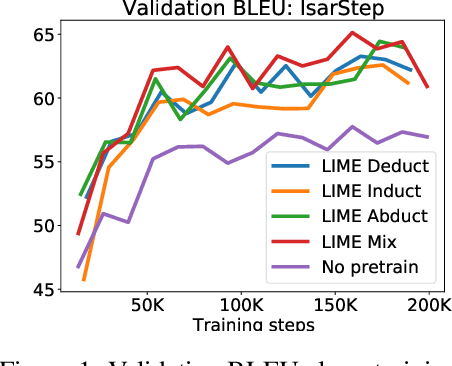

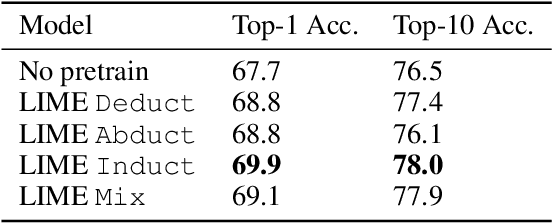
While designing inductive bias in neural architectures has been widely studied, we hypothesize that transformer networks are flexible enough to learn inductive bias from suitable generic tasks. Here, we replace architecture engineering by encoding inductive bias in the form of datasets. Inspired by Peirce's view that deduction, induction, and abduction form an irreducible set of reasoning primitives, we design three synthetic tasks that are intended to require the model to have these three abilities. We specifically design these synthetic tasks in a way that they are devoid of mathematical knowledge to ensure that only the fundamental reasoning biases can be learned from these tasks. This defines a new pre-training methodology called "LIME" (Learning Inductive bias for Mathematical rEasoning). Models trained with LIME significantly outperform vanilla transformers on three very different large mathematical reasoning benchmarks. Unlike dominating the computation cost as traditional pre-training approaches, LIME requires only a small fraction of the computation cost of the typical downstream task.
The Scattering Compositional Learner: Discovering Objects, Attributes, Relationships in Analogical Reasoning
Jul 08, 2020
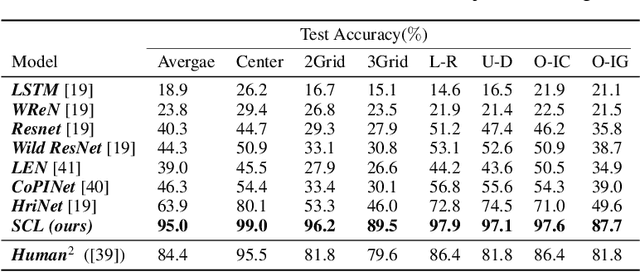
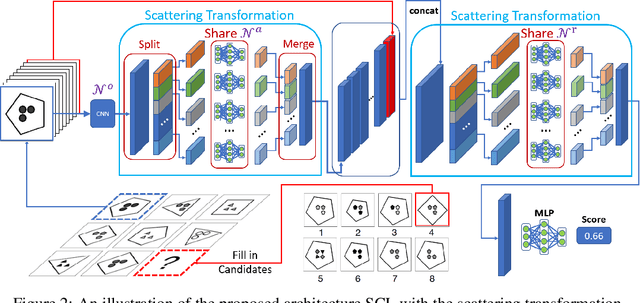
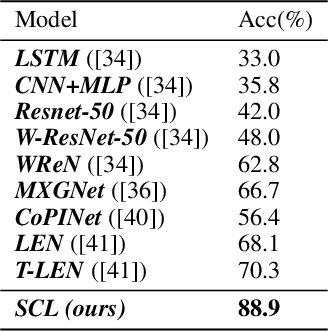
In this work, we focus on an analogical reasoning task that contains rich compositional structures, Raven's Progressive Matrices (RPM). To discover compositional structures of the data, we propose the Scattering Compositional Learner (SCL), an architecture that composes neural networks in a sequence. Our SCL achieves state-of-the-art performance on two RPM datasets, with a 48.7% relative improvement on Balanced-RAVEN and 26.4% on PGM over the previous state-of-the-art. We additionally show that our model discovers compositional representations of objects' attributes (e.g., shape color, size), and their relationships (e.g., progression, union). We also find that the compositional representation makes the SCL significantly more robust to test-time domain shifts and greatly improves zero-shot generalization to previously unseen analogies.
Learning Branching Heuristics for Propositional Model Counting
Jul 07, 2020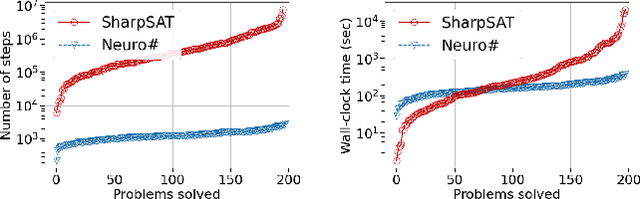
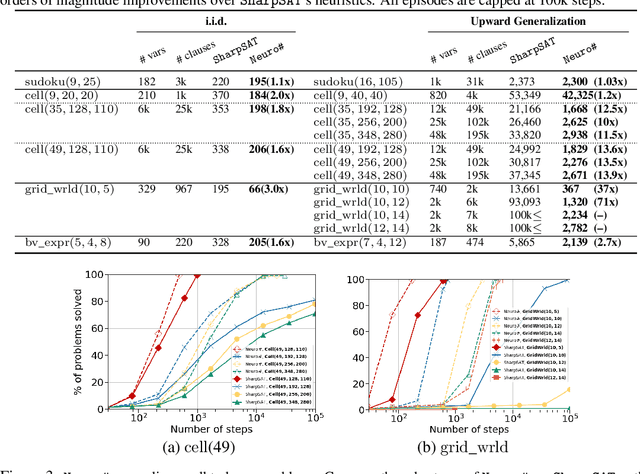
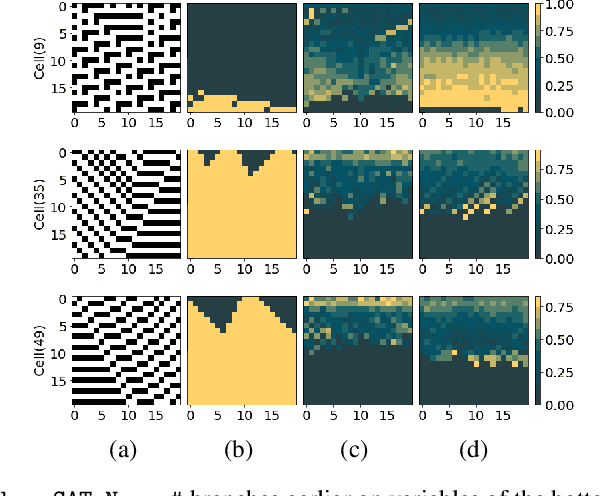
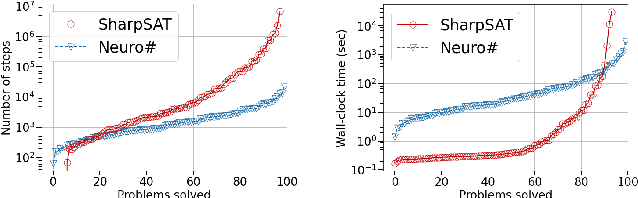
Propositional model counting or #SAT is the problem of computing the number of satisfying assignments of a Boolean formula and many discrete probabilistic inference problems can be translated into a model counting problem to be solved by #SAT solvers. Generic ``exact'' #SAT solvers, however, are often not scalable to industrial-level instances. In this paper, we present Neuro#, an approach for learning branching heuristics for exact #SAT solvers via evolution strategies (ES) to reduce the number of branching steps the solver takes to solve an instance. We experimentally show that our approach not only reduces the step count on similarly distributed held-out instances but it also generalizes to much larger instances from the same problem family. The gap between the learned and the vanilla solver on larger instances is sometimes so wide that the learned solver can even overcome the run time overhead of querying the model and beat the vanilla in wall-clock time by orders of magnitude.